
일반 소개
비전 에이전트는 사용자가 컴퓨터 비전 작업을 해결하기 위한 코드를 빠르게 생성할 수 있도록 돕기 위해 LandingAI(엔다 우의 팀)에서 개발하고 GitHub에서 호스팅하는 오픈 소스 프로젝트입니다. 고급 에이전트 프레임워크와 멀티모달 모델을 사용하여 이미지 감지, 비디오 추적, 객체 수 계산 등 다양한 시나리오에 대한 간단한 프롬프트를 통해 효율적인 비전 AI 코드를 생성합니다. 이 도구는 신속한 프로토타이핑을 지원할 뿐만 아니라 생산 환경에 원활하게 배포할 수 있어 제조, 의료, 농업 등에 폭넓게 적용 가능합니다. 비전 에이전트는 복잡한 비전 작업을 자동화하도록 설계되었으며, 개발자는 작업에 대한 설명만 제공하면 실행 가능한 코드를 얻을 수 있어 비전 AI 개발의 문턱을 크게 낮췄습니다. 현재 3,000개 이상의 스타 태그를 받았으며, 커뮤니티가 매우 활발하고 지속적으로 업데이트되고 있습니다.

적용 사례는 다음에서 확인할 수 있습니다. 에이전트 객체 감지: 주석 및 교육 없이 시각적 객체를 감지하는 도구

기능 목록
- 자동 코드 생성사용자가 입력한 작업 설명을 기반으로 이미지 또는 동영상에 대한 시각적 AI 코드를 생성합니다.
- 물체 감지 및 카운팅이미지 또는 동영상에서 특정 객체를 감지하고 인원 수와 같은 개수를 계산하는 기능을 지원합니다.
- 비디오 프레임 분석비디오에서 프레임을 추출하고 객체 추적 또는 세그먼테이션을 수행합니다.
- 시각화 도구바운딩 박스 오버레이 및 분할 마스크의 이미지/비디오 시각화를 제공합니다.
- 다중 모델 지원사용자가 필요에 따라 전환할 수 있는 다양한 오픈 소스 시각적 모델을 통합합니다.
- 사용자 지정 도구 확장특정 작업 요구 사항을 충족하기 위해 새 도구 또는 모델을 추가할 수 있습니다.
- 배포 지원프로덕션 환경에서 신속한 프로토타이핑 및 배포를 지원하는 코드를 생성합니다.
도움말 사용
설치 및 사용 방법
Vision Agent는 Python 기반 라이브러리이므로 사용자는 GitHub를 통해 소스 코드를 다운로드하여 로컬 환경에 설치해야 합니다. 자세한 설치 및 사용 절차는 다음과 같습니다:
설치 프로세스
- 환경 준비
- 컴퓨터에 Python 3.8 이상이 설치되어 있는지 확인하세요.
- Git을 설치하여 GitHub에서 리포지토리를 복제합니다.
- 선택 사항: 가상 환경을 사용하는 것이 좋습니다(예
venv어쩌면conda)를 사용하여 종속성을 분리합니다.
- 클론 창고
터미널을 열고 다음 명령을 실행하여 Vision 에이전트 소스 코드를 가져옵니다:git clone https://github.com/landing-ai/vision-agent.git cd vision-agent
- 종속성 설치
리포지토리 디렉터리에서 필요한 종속성을 설치합니다:pip install -r requirements.txt특정 모델을 사용해야 하는 경우(예 인류학 또는 OpenAI)를 사용하는 경우 API 키의 추가 구성이 필요합니다(나중에 참조하세요).
- 설치 확인
다음 명령을 실행하여 설치가 성공했는지 확인합니다:python -c "import vision_agent; print(vision_agent.__version__)"버전 번호가 반환되면(예: 0.2) 설치가 완료된 것입니다.
주요 기능 사용
비전 에이전트의 핵심 기능은 프롬프트에서 코드를 생성하고 비전 작업을 수행하는 것입니다. 다음은 주요 기능에 대한 자세한 단계별 절차입니다:
1. 시각적 AI 코드 생성
- 절차::
- 비전 에이전트 모듈을 가져옵니다:
from vision_agent.agent import VisionAgentCoderV2 agent = VisionAgentCoderV2(verbose=True) - 작업 설명과 미디어 파일을 준비합니다. 예를 들어 이미지에 있는 사람의 수를 계산합니다:
code_context = agent.generate_code([ {"role": "user", "content": "Count the number of people in this image", "media": ["people.png"]} ]) - 생성된 코드를 저장합니다:
with open("count_people.py", "w") as f: f.write(code_context.code)
- 비전 에이전트 모듈을 가져옵니다:
- 기능 설명이미지 경로와 작업 설명을 입력하면 비전 에이전트가 객체 감지 및 카운팅 로직이 포함된 Python 코드를 자동으로 생성합니다. 생성된 코드는 다음과 같은 기본 제공 도구를 사용합니다.
countgd_object_detection.
2. 물체 감지 및 시각화
- 절차::
- 이미지를 로드하고 탐지를 실행합니다:
import vision_agent.tools as T image = T.load_image("people.png") dets = T.countgd_object_detection("person", image) - 바운딩 박스를 오버레이하고 결과를 저장합니다:
viz = T.overlay_bounding_boxes(image, dets) T.save_image(viz, "people_detected.png") - 결과 시각화(선택 사항):
import matplotlib.pyplot as plt plt.imshow(viz) plt.show()
- 이미지를 로드하고 탐지를 실행합니다:
- 기능 설명이 기능은 이미지에서 지정된 개체(예: '사람')를 감지하고 이미지에 경계 상자를 그리는 기능으로 품질 검사, 모니터링 및 기타 시나리오에 적합합니다.
3. 동영상 프레임 분석 및 추적
- 절차::
- 비디오 프레임을 추출합니다:
frames_and_ts = T.extract_frames_and_timestamps("people.mp4") frames = [f["frame"] for f in frames_and_ts] - 개체 추적을 실행합니다:
tracks = T.countgd_sam2_video_tracking("person", frames) - 시각화 동영상을 저장합니다:
viz = T.overlay_segmentation_masks(frames, tracks) T.save_video(viz, "people_tracked.mp4")
- 비디오 프레임을 추출합니다:
- 기능 설명는 동영상에서 프레임을 추출하고, 객체를 감지 및 추적하며, 마지막으로 동적 장면 분석에 적합한 세그멘테이션 마스크로 동영상 시각화를 생성합니다.
4. 다른 모델 구성
- 절차::
- 다른 모델(예: Anthropic)을 사용하도록 구성 파일을 수정합니다:
cp vision_agent/configs/anthropic_config.py vision_agent/configs/config.py - API 키를 설정합니다:
환경 변수에 키를 추가합니다:export ANTHROPIC_API_KEY="your_key_here" - 코드 생성 작업을 다시 실행합니다.
- 다른 모델(예: Anthropic)을 사용하도록 구성 파일을 수정합니다:
- 기능 설명비전 에이전트는 기본적으로 여러 모델을 지원하며, 사용자는 필요에 따라 모델을 전환하여 작업의 효율성을 높일 수 있습니다.
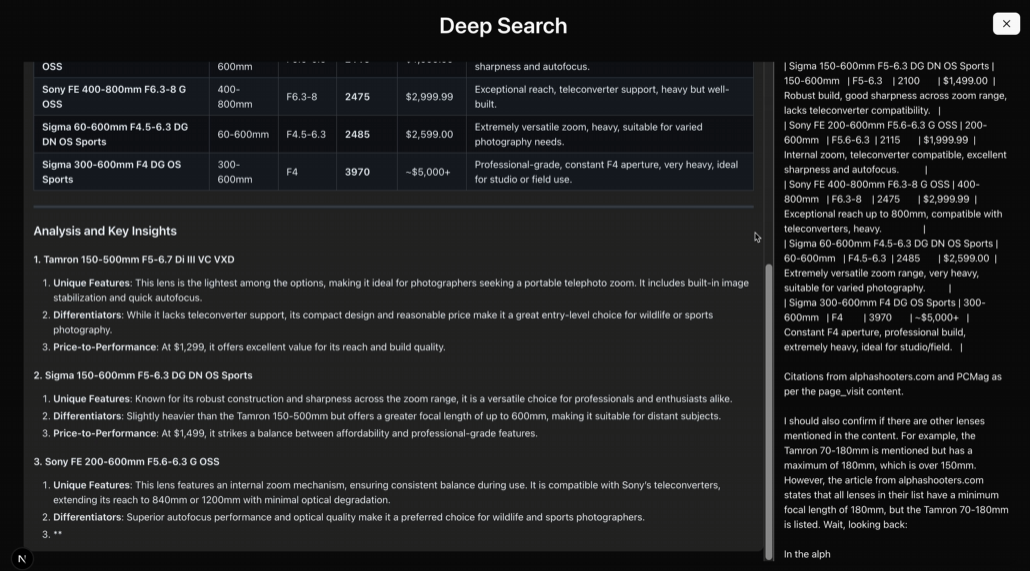
작업 프로세스 예시: 원두 충전 비율 계산하기
커피 원두가 담긴 항아리 이미지가 있고 채우기 비율을 계산하고 싶다고 가정해 보겠습니다:
- 작업 설명을 작성하고 실행합니다:
agent = VisionAgentCoderV2() code_context = agent.generate_code([ {"role": "user", "content": "What percentage of the jar is filled with coffee beans?", "media": ["jar.jpg"]} ]) - 생성된 코드를 실행합니다:
생성된 코드는 다음과 같습니다:from vision_agent.tools import load_image, florence2_sam2_image image = load_image("jar.jpg") jar_segments = florence2_sam2_image("jar", image) beans_segments = florence2_sam2_image("coffee beans", image) jar_area = sum(segment["mask"].sum() for segment in jar_segments) beans_area = sum(segment["mask"].sum() for segment in beans_segments) percentage = (beans_area / jar_area) * 100 if jar_area else 0 print(f"Filled percentage: {percentage:.2f}%") - 코드를 실행하여 결과를 얻습니다.
주의
- 입력 이미지 또는 동영상의 형식이 올바른지 확인합니다(예: PNG, MP4).
- 종속성 문제가 발생하면 다음을 업데이트해 보세요.
pip install --upgrade vision-agent. - 커뮤니티 지원: 도움이 필요하면 랜딩AI의 디스코드 커뮤니티에 가입하여 조언을 구하세요.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...