
VikingDB란?
VikingDB는 대용량 고차원 벡터 데이터 처리를 위해 설계된 볼케이노 엔진의 고성능 클라우드 네이티브 벡터 데이터베이스로, 실시간 동기식, 비동기식 쓰기 등 다양한 데이터 쓰기 방식을 통해 다양한 시나리오의 요구를 충족하며, 자체 개발한 고효율 인덱싱 알고리즘인 HNSW 및 IVF를 기반으로 수백억 개의 벡터를 밀리초 단위로 검색할 수 있으며, 밀집 및 희소 벡터 검색과 호환됩니다. VikingDB는 여러 언어로 된 SaaS 콘솔, API 및 SDK를 제공하며 자동 탄력 확장을 지원하여 스토리지 비용을 효과적으로 절감할 수 있으며, 멀티모달 검색, 지능형 추천, RAG 시나리오 및 메모리 구성 분야에서 널리 사용되어 기업이 효율적인 데이터 관리와 지능형 애플리케이션 개발을 달성하는 데 도움이 됩니다.
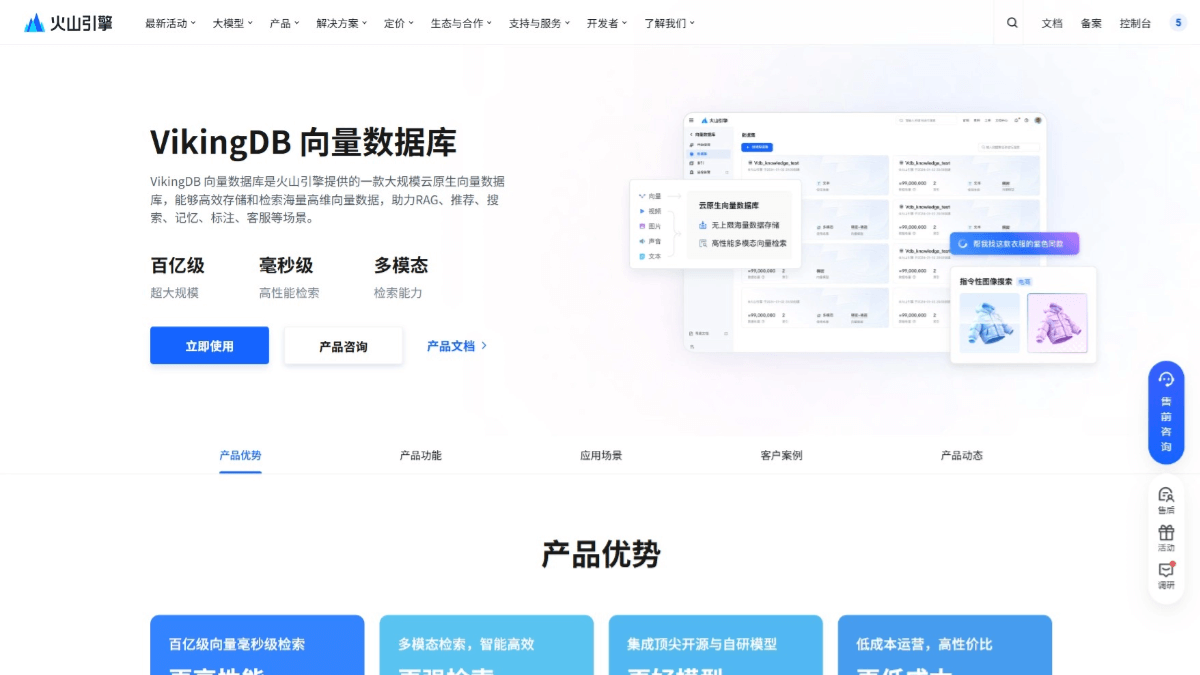
VikingDB의 주요 기능
- 유연한 데이터 쓰기실시간 동기식, 비동기식, 단일 데이터 쓰기, 일괄 쓰기 등 다양한 쓰기 방법을 제공하여 다양한 비즈니스 시나리오의 요구 사항을 충족합니다.
- 효율적인 인덱싱 및 실시간 업데이트인덱싱 알고리즘은 스트리밍 업데이트 아키텍처와 결합된 HNSW, IVF 및 기타 고급 인덱싱 알고리즘을 기반으로 하므로 부하가 많은 상황에서도 데이터를 빠르게 업데이트하고 실시간 검색을 보장할 수 있습니다.
- 강력한 검색 기능벡터, 스칼라, 혼합 및 멀티모달 데이터 검색을 지원하여 수백억 개의 벡터 데이터에서 밀리초 단위의 검색을 수행하여 복잡한 쿼리 요구 사항을 충족할 수 있습니다.
- 탄력적이고 확장 가능한 클라우드 서비스여러 언어로 된 SaaS 콘솔, API 인터페이스 및 SDK를 제공하고, 자동 탄력적 확장을 지원하며, 사용자가 데이터 검색 프로세스를 신속하게 구축하고 관리할 수 있도록 도와줍니다.
- 고성능 및 비용 최적화: 고도로 최적화된 인덱싱 알고리즘과 정량화 기술을 통해 매우 높은 검색 효율성을 달성하는 동시에 스토리지 비용을 절감하여 대규모 데이터 시나리오에서 비용 효율성을 보장합니다.
- 지식창고 및 메모리 기능대규모 모델의 복잡한 시맨틱 검색 및 장기 메모리 저장을 지원하며 지능형 비서, 교육 및 강의와 같은 개인화된 상호 작용 시나리오에 적합합니다.
VikingDB의 공식 웹사이트 주소
- 공식 웹사이트 주소:: https://www.volcengine.com/product/VikingDB
VikingDB 사용 방법
- 등록 및 로그인볼케이노 엔진의 공식 웹사이트를 방문하여 계정 등록을 완료하고 로그인하여 VikingDB 콘솔에 액세스하세요.
- 인스턴스 만들기콘솔에서 이름, 스토리지 용량, 성능 사양 등의 매개변수를 필요에 따라 구성하여 VikingDB 인스턴스를 생성합니다.
- 데이터 준비 및 벡터화처리할 데이터를 구성하고 임베딩 모델(예 Doubao 또는 기타 오픈 소스 모델)을 벡터 형식으로 변환합니다.
- SDK에 액세스VikingDB에서 제공하는 SDK(Python, Java, Go 등)를 설치 및 초기화한 후 생성된 데이터베이스 인스턴스에 연결합니다.
- 데이터 쓰기실시간 동기식, 비동기식 및 기타 쓰기 방법 중에서 선택하여 SDK를 기반으로 벡터 데이터를 VikingDB에 씁니다.
- 검색가장 유사한 결과를 찾기 위해 벡터, 스칼라 또는 하이브리드 검색을 수행하려면 SDK를 사용하세요.
- 모니터링 및 최적화콘솔에서 인스턴스 성능 메트릭을 모니터링하고 실제 사용량에 따라 성능과 비용을 최적화하도록 구성을 조정합니다.
VikingDB의 핵심 이점
- 고성능 검색자체 개발한 효율적인 인덱싱 알고리즘(예: HNSW, IVF 등)을 기반으로 수백억 개의 벡터에서 밀리초 단위의 검색을 달성하고 검색 대기 시간이 10ms로 낮아 쿼리 효율성을 크게 향상시켰습니다.
- 다양성 데이터 지원고밀도 벡터와 희소 벡터의 검색을 지원하며 벡터, 스칼라, 혼합 및 멀티모달 데이터의 검색과 호환되며 다양하고 복잡한 데이터 유형과 시나리오에 적용할 수 있습니다.
- 유연한 데이터 쓰기실시간 동기식, 비동기식 쓰기, 단일 데이터 쓰기, 일괄 쓰기 기능을 제공하여 다양한 비즈니스 시나리오의 데이터 쓰기 요구 사항을 충족하고 데이터 처리의 유연성과 효율성을 보장합니다.
- 탄력성 및 확장성클라우드 네이티브 데이터베이스로서 다양한 언어로 SaaS 콘솔, API, SDK를 제공하고 자동 탄력적 확장을 지원하며 데이터 볼륨과 쿼리 부하에 따라 리소스를 동적으로 조정하여 시스템 안정성과 효율성을 보장합니다.
- 저렴한 비용의 스토리지고도로 최적화된 인덱싱 알고리즘과 정량화 기법을 사용해 스토리지 비용을 절감하고 가격 대비 성능을 개선하면서 고성능을 달성하세요.
- 지식창고 및 메모리 기능지능형 비서, 교육 및 강의, 롤플레잉 등 개인화된 상호작용 시나리오에 적용 가능한 대규모 모델의 복잡한 시맨틱 검색과 장기 메모리 저장을 제공하며, 대규모 모델의 효율적인 검색 및 메모리 관리를 지원합니다.
VikingDB의 대상
- 인공 지능 및 머신 러닝 엔지니어대규모 벡터 데이터를 처리하고 검색해야 하는 엔지니어를 위한 모델 훈련, 특징 검색, 멀티모달 데이터 처리를 지원하는 효율적인 도구입니다.
- 데이터 과학자데이터 분석 및 마이닝 시 다양한 검색 기능과 유연한 데이터 작성 기능을 통해 데이터 과학자는 모델을 신속하게 검증하고 복잡한 데이터를 처리할 수 있습니다.
- 기업 기술팀VikingDB의 고성능과 탄력적인 확장성은 지능형 추천 시스템, 멀티모달 검색 플랫폼 또는 지식 기반을 구축해야 하는 조직의 비즈니스 성장과 기술 요구 사항을 지원합니다.
- 시스템 설계자시스템 아키텍처 설계를 담당하는 아키텍트를 위해 기존 기술 스택에 원활하게 통합되는 고성능, 확장성 및 통합이 용이한 솔루션을 제공하세요.
- 개발자VikingDB는 개발자가 효율적인 데이터 관리 및 애플리케이션 개발을 위해 VikingDB에 빠르게 액세스하고 사용할 수 있도록 다국어 SDK와 자세한 설명서를 제공합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...