

일반 소개
비디오리토킹은 입력된 오디오를 기반으로 립싱크된 얼굴 동영상을 생성하여 다양한 감정에도 고품질의 립싱크된 출력 동영상을 생성할 수 있는 혁신적인 시스템입니다. 이 시스템은 일반적인 표정을 가진 얼굴 비디오 생성, 오디오 기반 립싱크, 사실감을 높이기 위한 얼굴 향상이라는 세 가지 연속적인 작업으로 나뉩니다. 이 세 단계는 사용자 개입 없이 순차적으로 수행할 수 있는 학습 기반 접근 방식을 사용하여 모두 처리합니다. 제공된 링크를 통해 비디오리토킹과 오디오 기반 립싱크 토킹 헤드 비디오 편집에 적용하는 방법을 살펴보세요.

(선명하지 않음, 동영상 품질을 두 번 향상시켜야 함, 중국어 립싱크가 약간 불량함)
기능 목록
얼굴 동영상 생성: 입력된 오디오를 기반으로 일반적인 표정이 담긴 얼굴 동영상을 생성합니다.
오디오 기반 립싱크: 주어진 오디오를 기반으로 립싱크된 비디오를 생성합니다.
얼굴 향상: 신원 인식 얼굴 향상 네트워크와 후처리를 통해 합성 얼굴의 사실감을 향상합니다.
도움말 사용
사전 학습된 모델을 다운로드하여 `. /체크포인트`에 넣습니다.
동영상을 빠르게 추론하려면 `python3 inference.py`를 실행하세요.
인자 `--exp_img` 또는 `--up_face`를 추가하여 표현식을 제어할 수 있습니다.
온라인 체험 주소
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서
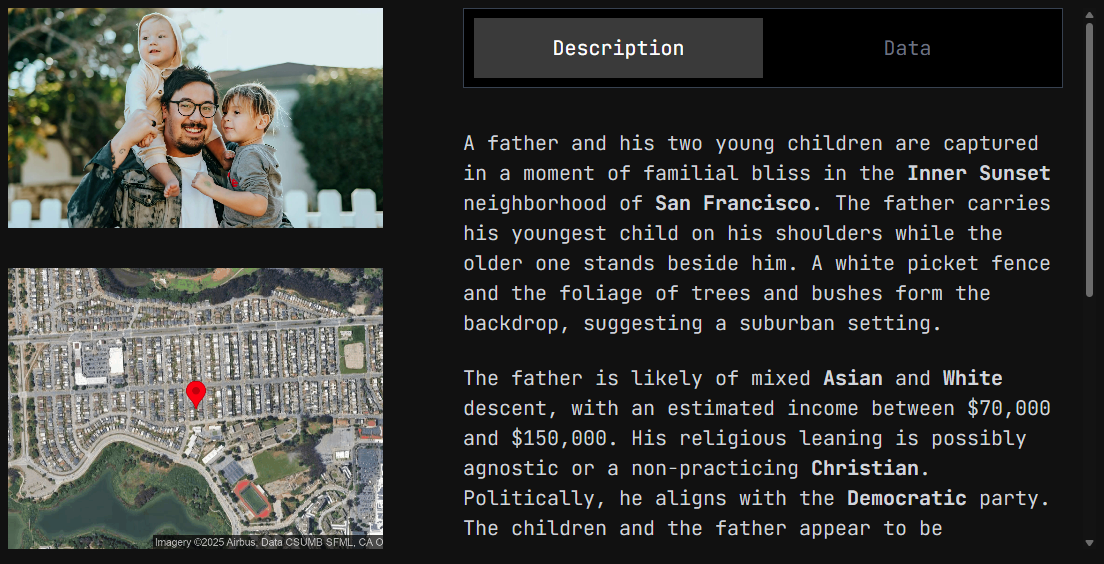


댓글 없음...