

V-JEPA 2란?
V-JEPA 2 예 메타 AI 12억 개의 매개변수가 포함된 비디오 데이터를 기반으로 한 세계 규모의 모델을 출시했습니다. 이 모델은 100만 시간 이상의 비디오와 100만 장의 이미지에서 자가 지도 학습을 기반으로 학습하여 실제 세계의 사물, 동작, 움직임을 이해하고 미래 상태를 예측합니다. 이 모델은 인코더-예측기 아키텍처를 동작 상태 예측과 결합하여 제로 샘플 로봇 계획을 지원함으로써 로봇이 새로운 환경에서 작업을 완료할 수 있도록 합니다. 이 모델은 비디오 Q&A 기능을 갖추고 있으며 언어 모델을 결합하여 비디오 콘텐츠와 관련된 질문에 답할 수 있도록 지원합니다.V-JEPA 2는 동작 인식, 예측, 비디오 Q&A 등의 작업에 탁월하여 로봇 제어, 지능형 감시, 교육, 의료 분야에 강력한 기술 지원을 제공하며 고급 기계 지능을 향한 중요한 발걸음이 될 것입니다.
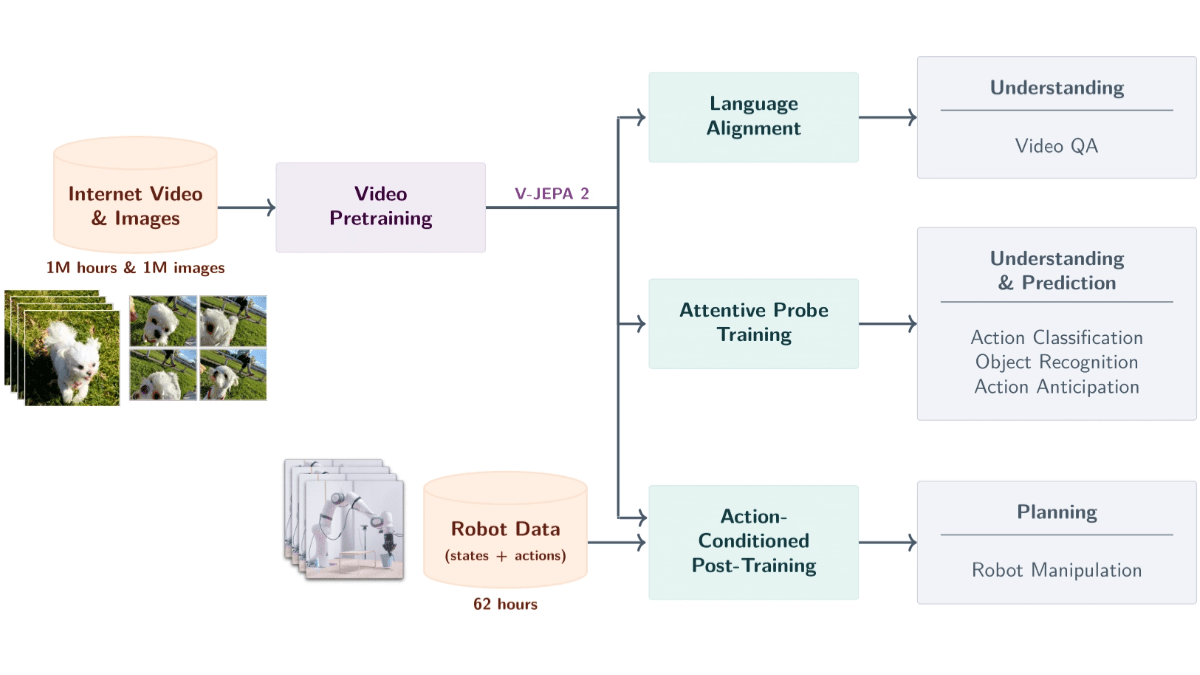
V-JEPA 2의 주요 기능
- 비디오 시맨틱 구문 분석동영상에서 사물, 동작, 움직임을 인식하고 장면에 대한 의미 정보를 정확하게 추출합니다.
- 향후 이벤트 예측현재 상태 및 동작을 기반으로 미래의 비디오 프레임 또는 동작 결과를 예측하여 단기 및 장기 예측을 모두 지원합니다.
- 로봇 제로 샘플 계획추가 학습 데이터 없이 예측 기능을 기반으로 물체를 파악하고 조작하는 등 새로운 환경에서 로봇이 수행할 작업을 계획합니다.
- 비디오 Q&A 상호 작용언어 모델링과 함께 동영상 내용과 관련된 질문에 답하며, 물리적 인과 관계와 장면 이해도를 다룹니다.
- 장면 간 일반화는 보이지 않는 환경과 물체에서도 잘 작동하며 새로운 장면에서 제로 샘플 학습과 적응을 지원합니다.
V-JEPA 2의 공식 웹사이트 주소
- 프로젝트 웹사이트::https://ai.meta.com/blog/v-jepa-2
- GitHub 리포지토리::https://github.com/facebookresearch/vjepa2
- 기술 문서::https://scontent-lax3-2.xx.fbcdn.net/v/t39.2365-6
V-JEPA 2 사용 방법
- 모델 리소스에 액세스미리 학습된 모델 파일과 관련 코드를 GitHub 리포지토리에서 다운로드합니다. 모델 파일은 .pth 또는 .ckpt 형식으로 제공됩니다.
- 개발 환경 설정::
- Python 설치파이썬이 설치되어 있는지 확인합니다(파이썬 3.8 이상 권장).
- 종속 라이브러리 설치pip를 사용하여 프로젝트에 필요한 종속성을 설치합니다. 일반적으로 프로젝트는 다음 명령에 따라 종속성을 설치하는 요구 사항.txt 파일을 제공합니다:
pip install -r requirements.txt- 딥 러닝 프레임워크 설치V-JEPA 2는 PyTorch를 기반으로 하며 시스템 및 GP 구성에 따라 PyTorch를 설치해야 하므로 PyTorch 웹사이트에서 설치 명령을 받습니다.
- 모델 로드::
- 사전 학습된 모델 로드파이토치로 미리 학습된 모델 파일을 로드합니다.
import torch
from vjepa2.model import VJEPA2 # 假设模型类名为 VJEPA2
# 加载模型
model = VJEPA2()
model.load_state_dict(torch.load("path/to/model.pth"))
model.eval() # 设置为评估模式- 데이터 입력 준비::
- 비디오 데이터 전처리V-JEPA 2는 비디오 데이터를 입력으로 필요로 합니다. 비디오 데이터는 모델에 필요한 형식(일반적으로 텐서)으로 변환됩니다. 아래는 간단한 전처리 예제입니다:
from torchvision import transforms
from PIL import Image
import cv2
# 定义视频帧的预处理
transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整帧大小
transforms.ToTensor(), # 转换为张量
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])
# 读取视频帧
cap = cv2.VideoCapture("path/to/video.mp4")
frames = []
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = Image.fromarray(frame)
frame = transform(frame)
frames.append(frame)
cap.release()
# 将帧堆叠为一个张量
video_tensor = torch.stack(frames, dim=0).unsqueeze(0) # 添加批次维度- 모델을 사용한 예측::
- 구현 예상: 전처리된 동영상 데이터를 모델에 입력하면 예측 결과를 얻을 수 있습니다. 다음은 샘플 코드입니다:
with torch.no_grad(): # 禁用梯度计算
predictions = model(video_tensor)- 예측 결과 구문 분석 및 적용::
- 예측 결과 분석: 작업 요구 사항에 따라 모델의 출력을 구문 분석합니다.
- 실제 시나리오에 적용하기로봇 제어, 비디오 퀴즈, 이상 징후 감지 등 실제 작업에 예측을 적용하세요.
V-JEPA 2의 핵심 이점
- 물리적 세계에 대한 높은 이해도V-JEPA 2는 비디오 입력을 기반으로 물체의 동작과 움직임을 정확하게 인식하여 장면에 대한 의미 정보를 캡처하고 복잡한 작업에 대한 기본적인 지원을 제공합니다.
- 효율적인 미래 상태 예측현재 상태와 동작을 기반으로 미래의 비디오 프레임 또는 동작 결과를 예측하여 단기 및 장기 예측을 모두 지원하여 로봇 계획 및 지능형 모니터링과 같은 애플리케이션을 활성화할 수 있습니다.
- 제로 샘플 학습 및 일반화 기능V-JEPA 2는 보이지 않는 환경과 물체에서도 잘 작동하고, 제로 샘플 학습 및 적응을 지원하며, 새로운 작업을 완료하는 데 추가 학습 데이터가 필요하지 않습니다.
- 언어 모델링과 결합된 비디오 Q&A 기능언어 모델과 결합하면 V-JEPA 2는 비디오 콘텐츠와 관련된 질문에 물리적 인과관계 및 장면 이해를 포함한 답변을 제공할 수 있어 교육 및 의료 등의 분야로 응용 분야를 확장할 수 있습니다.
- 자기 주도 학습을 기반으로 한 효율적인 교육데이터에 수동으로 레이블을 지정하지 않고도 자가 지도 학습을 기반으로 대규모 비디오 데이터에서 일반적인 시각적 표현을 학습하여 비용을 절감하고 일반화를 개선합니다.
- 다단계 훈련 및 이동 조건 예측다단계 학습을 기반으로 인코더를 사전 학습한 다음 동작 상태 예측기를 학습시켜 시각 정보와 동작 정보를 결합하여 정확한 예측 제어를 지원하는 V-JEPA 2.
V-JEPA 2의 대상 사용자
- 인공 지능 연구원기계 지능을 촉진하기 위한 V-JEPA 2의 최첨단 기술을 통한 학술 연구 및 기술 혁신.
- 로봇 공학 엔지니어모델 제로 샘플 계획 기능을 통해 새로운 환경과 복잡한 작업에 적합한 로봇 시스템을 개발합니다.
- 컴퓨터 비전 개발자지능형 보안, 산업 자동화 및 기타 분야에서 사용되는 V-JEPA 2로 영상 분석의 효율성을 향상하세요.
- 자연어 처리(NLP) 전문가시각 및 언어 모델링을 결합하여 가상 비서 및 지능형 고객 서비스와 같은 지능형 인터랙션 시스템을 개발합니다.
- 교육자비디오 퀴즈 기능을 기반으로 몰입형 교육 도구를 개발하여 교육과 학습을 강화합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서

댓글 없음...