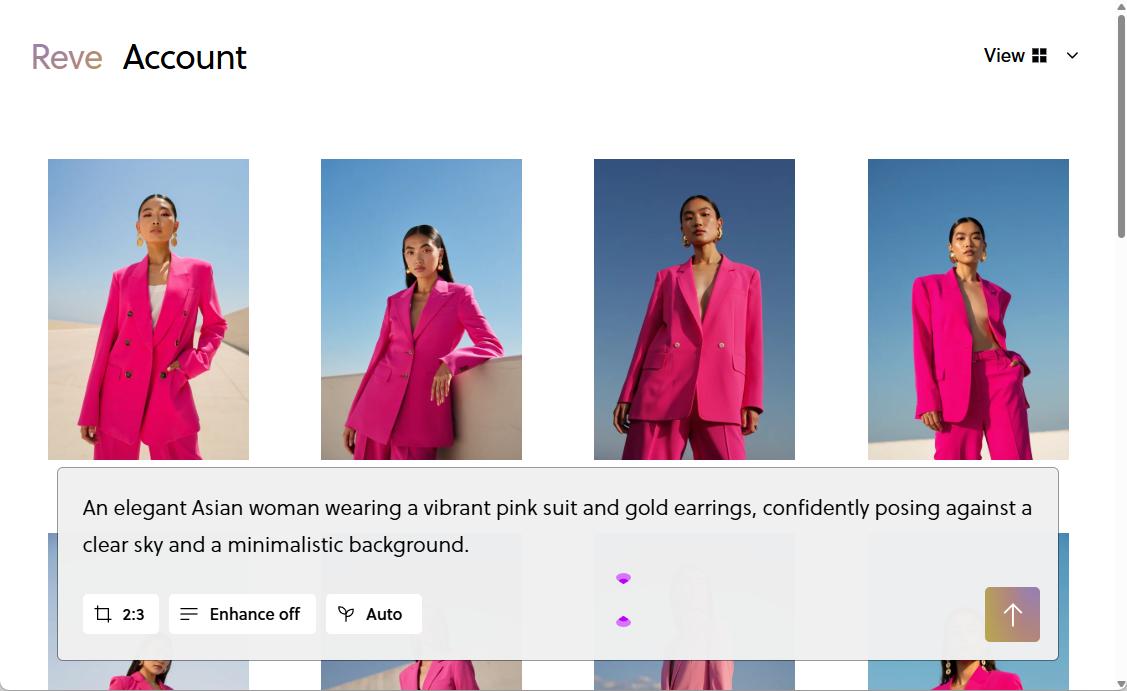

일반 소개
Unsloth는 대규모 언어 모델(LLM)을 미세 조정하고 훈련하기 위한 효율적인 도구를 제공하기 위해 설계된 오픈 소스 프로젝트입니다. 이 프로젝트는 라마, 미스트랄, 파이, 젬마 등 잘 알려진 다양한 모델을 지원합니다. Unsloth의 주요 기능은 메모리 사용량을 크게 줄이고 학습 속도를 높여 사용자가 더 짧은 시간에 모델을 미세 조정하고 학습할 수 있도록 하는 기능입니다. 또한 Unsloth는 사용자가 빠르게 시작하고 기능을 최대한 활용할 수 있도록 광범위한 문서와 튜토리얼을 제공합니다.

기능 목록
- 효율적인 미세 조정2~5배 빠른 미세 조정과 50~80% 적은 메모리 사용량으로 라마, 미스트랄, 파이, 젬마 등 여러 모델을 지원합니다.
- 무료 사용사용자가 데이터 집합을 추가하고 모든 코드를 실행하여 미세 조정된 모델을 얻을 수 있도록 무료로 사용할 수 있는 노트북이 제공됩니다.
- 여러 내보내기 형식미세 조정된 모델을 GGUF, Ollama, vLLM으로 내보내거나 허깅 페이스에 업로드할 수 있도록 지원합니다.
- 동적 정량화동적 4비트 양자화를 지원하여 모델 정확도를 향상시키면서 10% 미만의 메모리를 추가합니다.
- 긴 컨텍스트 지원Llama 3.3(70B) 모델의 경우 89K 컨텍스트 창을, Llama 3.1(8B) 모델의 경우 342K 컨텍스트 창을 지원합니다.
- 시각적 모델링 지원라마 3.2 비전(11B), 퀀 2.5 VL(7B), 픽스트랄(12B) 등의 비전 모델을 지원합니다.
- 추론 최적화추론 속도를 크게 향상시키기 위한 다양한 추론 최적화 옵션을 제공합니다.
도움말 사용
설치 프로세스
- 종속성 설치파이썬 3.8 이상이 설치되어 있고 다음 종속성이 설치되어 있는지 확인합니다:
bash
pip install torch transformers datasets - 클론 창고Git을 사용하여 Unsloth 리포지토리를 복제합니다:
bash
git clone https://github.com/unslothai/unsloth.git
cd unsloth - Unsloth 설치: 다음 명령을 실행하여 Unsloth를 설치합니다:
bash
pip install -e .
튜토리얼
- 모델 로드파이썬 스크립트에서 사전 학습된 모델을 로드합니다:
from transformers import AutoModelForCausalLM, AutoTokenizer model_name = "unslothai/llama-3.3" model = AutoModelForCausalLM.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name) - 모델 미세 조정모델 미세 조정을 위해 Unsloth에서 제공하는 노트북을 사용하세요. 다음은 간단한 예시입니다:
from unsloth import Trainer, TrainingArguments training_args = TrainingArguments( output_dir="./results", num_train_epochs=3, per_device_train_batch_size=4, save_steps=10_000, save_total_limit=2, ) trainer = Trainer( model=model, args=training_args, train_dataset=train_dataset, eval_dataset=eval_dataset, ) trainer.train() - 내보내기 모델미세 조정이 완료되면 모델을 다양한 포맷으로 내보낼 수 있습니다:
python
model.save_pretrained("./finetuned_model")
tokenizer.save_pretrained("./finetuned_model")
세부 기능 작동
- 동적 정량화Unsloth는 미세 조정 과정에서 동적 4비트 양자화를 지원하므로 10% 미만의 메모리 사용량을 추가하면서 모델의 정확도를 크게 향상시킬 수 있습니다. 사용자는 훈련 파라미터에서 이 기능을 활성화할 수 있습니다:
training_args = TrainingArguments( output_dir="./results", num_train_epochs=3, per_device_train_batch_size=4, save_steps=10_000, save_total_limit=2, quantization="dynamic_4bit" ) - 긴 컨텍스트 지원언슬러스는 라마 3.3(70B) 모델의 89K 컨텍스트 창과 라마 3.1(8B) 모델의 342K 컨텍스트 창을 지원합니다. 이를 통해 긴 텍스트를 더욱 효과적으로 처리할 수 있습니다. 사용자는 모델을 로드할 때 컨텍스트 창의 크기를 지정할 수 있습니다:
model = AutoModelForCausalLM.from_pretrained(model_name, context_window=89000) - 시각적 모델링 지원Unsloth는 Llama 3.2 Vision(11B), Qwen 2.5 VL(7B), Pixtral(12B) 등 다양한 비전 모델도 지원합니다. 사용자는 이러한 모델을 이미지 생성 및 처리 작업에 사용할 수 있습니다:
python
model_name = "unslothai/llama-3.2-vision"
model = AutoModelForImageGeneration.from_pretrained(model_name)
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...