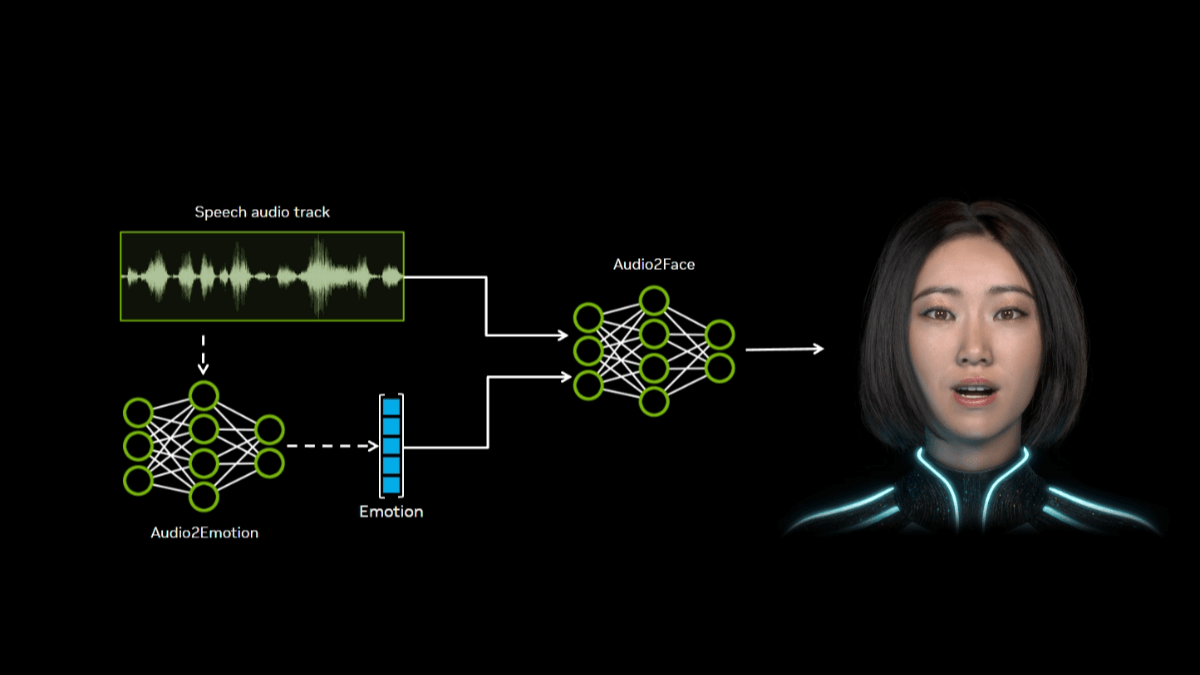
칸딘스키 5.0은 러시아 AI 팀이 개발한 최신 비디오 생성 모델 시리즈로, 가벼운 디자인과 고성능 성능에 중점을 두고 있습니다. 이 시리즈의 첫 번째 모델인 칸딘스키 5.0 비디오 라이트는 매개 변수가 20억 개에 불과하지만, 특히 유사한 14억 개에 달하는 모델을 능가합니다.
송블룸은 홍콩 중문대학교(선전) 및 난징대학교와 협력하여 Tencent AI Lab에서 개발한 오픈 소스 노래 생성 모델로, AI 음악 생성의 '가소성' 문제를 해결하고 구조적으로 완벽한 고품질의 노래를 생성할 수 있습니다. 10초 분량의 레퍼런스 오디오와 해당 가사를 입력하기만 하면...
Pyscn은 파이썬 개발자가 코드의 잠재적 문제를 감지하여 유지보수성을 개선할 수 있도록 설계된 지능형 코드 품질 분석 도구입니다. 제어 흐름도를 통해 데드 코드를 분석하고, APTED+LSH 알고리즘을 사용하여 중복 코드를 식별하고, 모듈 결합 및 원 복잡도와 같은 메트릭을 계산합니다....
Youtu-Embedding은 엔터프라이즈급 애플리케이션을 위해 설계된 Tencent의 Youtu Labs에서 개발한 오픈 소스 범용 텍스트 표현 모델입니다. 텍스트는 심층 신경망에 의해 고차원 벡터 공간에 매핑되어 의미적으로 유사한 문장이 해당 공간에서 서로 가깝게 배치되어 정확한 의미 검색을 달성합니다.
SAIL-VL2는 이미지와 텍스트와 같은 멀티모달 입력의 공동 모델링에 중점을 둔 Byte Jump 팀의 오픈 소스 멀티모달 시각 언어 모델입니다. 전문가(MoE) 아키텍처와 점진적 훈련 전략의 희소 혼합을 사용하여 2B~8B의 매개변수 규모, 특히 그래픽 이해, 수학적 이해에서 높은 성능을 달성합니다.
의사 결정 트리(DT)는 일련의 규칙을 통해 데이터를 분류하거나 예측하는 인간의 의사 결정 과정을 시뮬레이션하는 나무 모양의 예측 모델입니다. 각 내부 노드는 기능 테스트를 나타내고, 가지는 테스트 결과에 해당하며, 리프 노드는 최종 결정을 저장합니다. 이 알고리즘은 분할 및 정복 전략을 사용합니다...
MineContext는 사용자가 방대한 양의 정보를 효율적으로 관리하고 지식 업무의 효율성을 개선할 수 있도록 돕기 위해 ByteDance Viking 팀이 오픈소스로 제공하는 적극적인 상황 인식 AI 파트너입니다. 스크린샷 및 콘텐츠 이해 기술을 통해 사용자의 일상적인 작업(예: 웹 검색, 문서 편집 등)을 자동으로 기록하고, 지원...
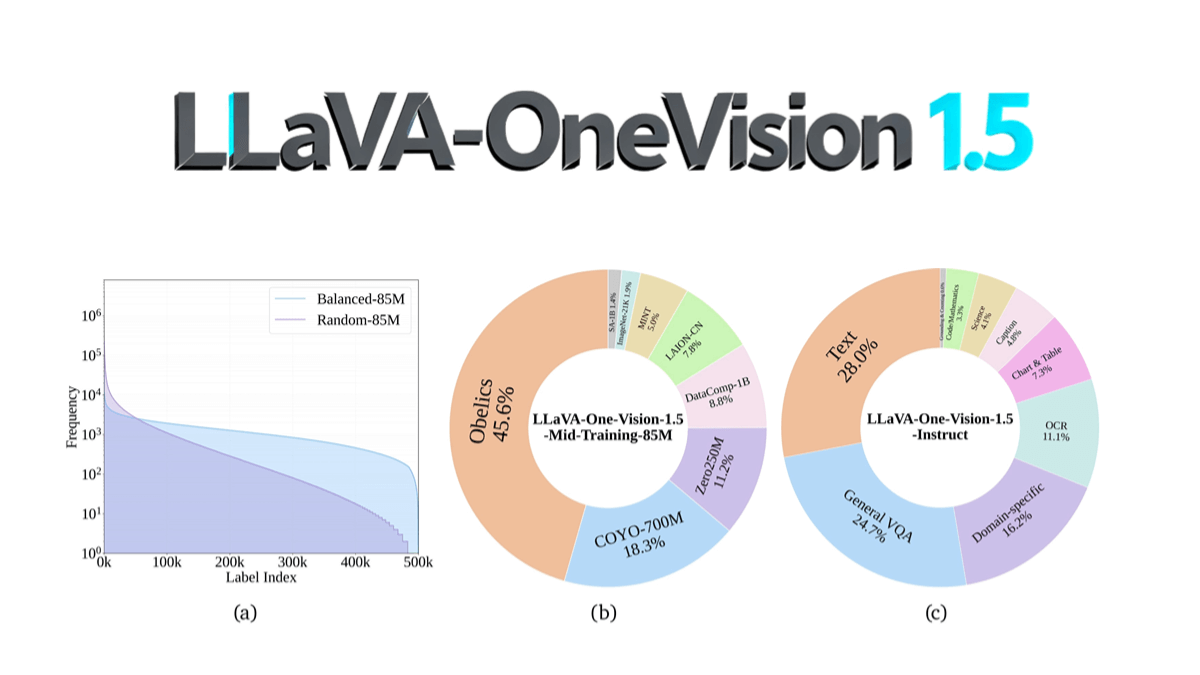
LLaVA-OneVision-1.5는 128개의 A800...에서 8B 파라미터 스케일을 사용하는 EvolvingLMMS-Lab 팀의 오픈 소스 멀티모달 모델로, 컴팩트한 3단계 훈련 프로세스(언어-이미지 정렬, 개념 평형화 및 지식 주입, 명령어 미세 조정)를 통해 학습합니다.
로지스틱 회귀는 이진 분류 문제를 해결하는 데 사용되는 통계적 학습 방법입니다. 핵심 목표는 입력된 특징을 바탕으로 샘플이 특정 범주에 속할 확률을 예측하는 것입니다. 이 모델은 S자형 함수를 사용하여 고유값을 선형적으로 결합하여 선형 출력을 0과 1 사이로 매핑합니다....
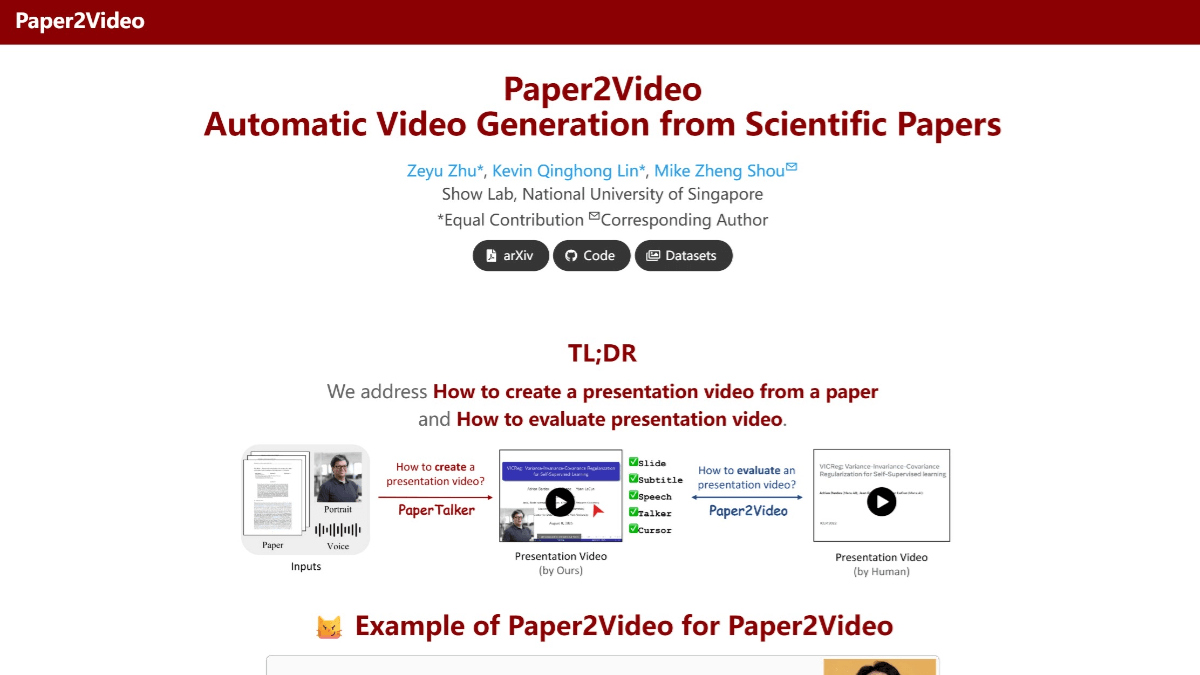
Paper2Video는 싱가포르 국립대학교 쇼 랩에서 학술 논문을 위한 자동 프레젠테이션 비디오 생성을 위한 오픈 소스 프로젝트입니다. PaperTalker 다중 지능 프레임워크를 사용하여 논문을 슬라이드, 자막, 음성 해설 및 발표자 아바타가 포함된 완전한 프레젠테이션 비디오로 변환합니다....
NeuTTS Air는 Neuphonic 팀이 개발한 오픈 소스 경량 음성 합성 모델로, 클라우드에 의존하지 않고 로컬 장치(예: 휴대폰, 노트북, 라즈베리파이)에서 실시간으로 실행할 수 있습니다. 0.5B 매개변수 Qwen 아키텍처와 자체 개발한 NeuCodec 코덱 사용...
KAT-Dev-72B-Exp는 레이서 팀에서 출시한 오픈소스 프로그래밍 전용 대규모 언어 모델로, 강화 학습 기법을 기반으로 최적화되어 SWE-Bench Verified 벤치마크 테스트에서 현재 오픈소스 모델 중 최고 성능인 74.6%의 정확도를 달성했습니다. 이 모델은 혁신적인...
에이전틱 AI는 어니스트 응이 출시한 지능형 바디에 관한 최신 강좌로, 반영, 도구 사용, 계획 및 다중 지능형 바디 협업의 네 가지 설계 패턴을 다루는 지능형 바디의 설계 및 구축에 중점을 둡니다. 학습자는 이론적 설명과 코드 실습을 통해 지능형 바디가 출력을 확인하고 자율적으로 조정하는 방법을 익히게 됩니다....
오픈에이전트는 AI 에이전트 네트워크를 생성하고 에이전트 간의 개방형 협업을 촉진하는 오픈 소스 프로젝트입니다. AI 에이전트가 원활하게 연결하고 협업할 수 있도록 기본 네트워크 인프라가 제공됩니다. 사용자는 자체 에이전트 네트워크를 빠르게 시작하고, 모듈식 아키텍처를 통해 기능을 확장하고, 지원...
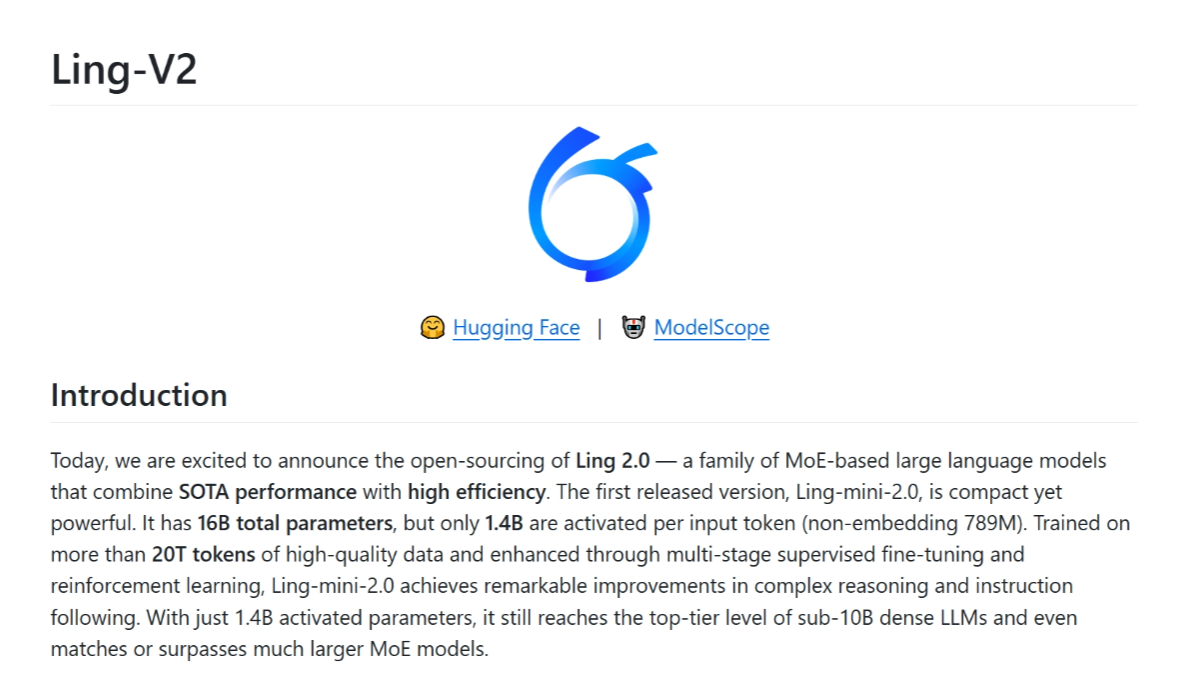
Ling-1T는 Ant Group에서 오픈소스화한 1조 개 매개변수 범용 언어 모델로, 베링의 대형 모델인 Ling 2.0 시리즈의 플래그십 제품에 속합니다. 이 모델은 고효율 MoE 아키텍처를 채택하고 128K 컨텍스트 윈도우를 지원하며 코드 생성, 수학적 추론, 논리 테스트 등 7가지 벤치마크에서 GPT를 능가합니다.
에코케어는 중국과학원(CAS) 홍콩혁신연구센터의 인공지능 및 로봇공학 혁신센터(CAIR)가 개발한 대규모 초음파 기반 모델로, 다센터, 다지역, 다인종, 50개 이상의 개인을 포함하는 세계 최대 규모의 초음파 이미지 데이터세트(450만 개 이상의 이미지)로 훈련되었습니다....
Code2Video는 코드 스니펫을 고품질 비디오 콘텐츠(MP4 형식)로 자동 변환하는 혁신적인 오픈 소스 프로젝트입니다. 독특한 코드 중심 패러다임을 통한 이 프로젝트는 탄소-now-cli 도구를 사용하여 코드를 아름다운 이미지로 생성하고, ffmpeg를 사용합니다 ...
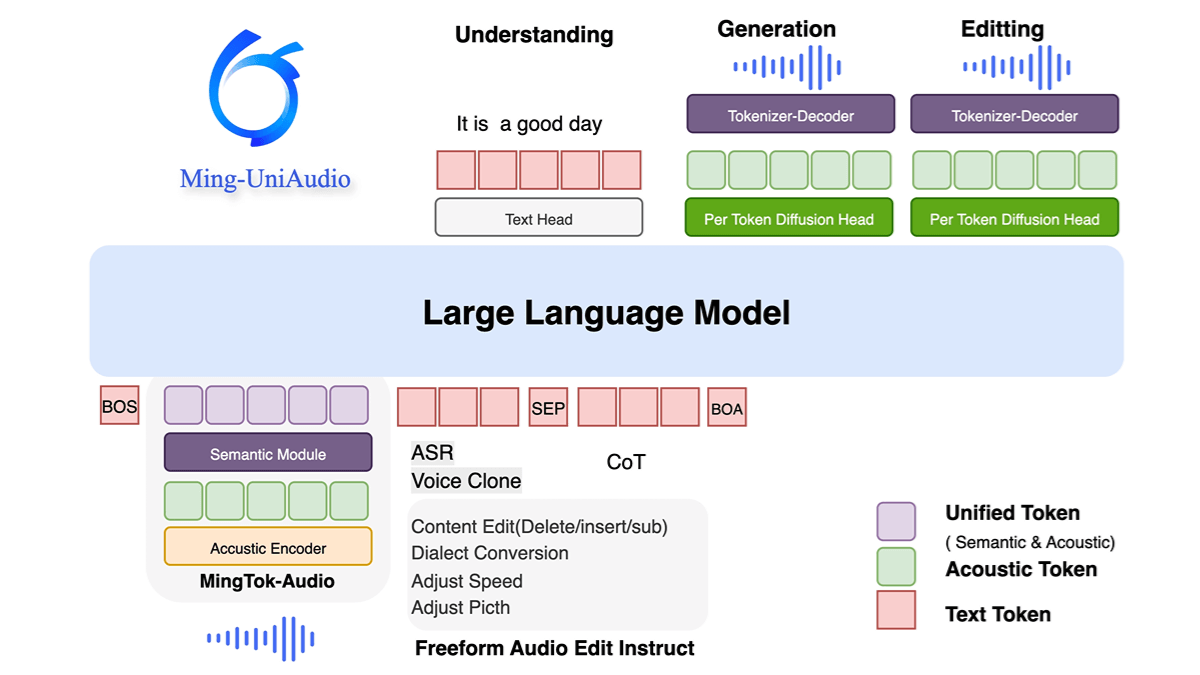
밍유니오디오는 텍스트, 오디오, 이미지, 비디오의 혼합 입력 및 출력을 지원하는 Ant Group의 오픈 소스 통합 오디오 멀티모달 생성 모델입니다. 멀티스케일 트랜스포머 및 혼합 전문가(MoE) 아키텍처를 사용하여 모달 인식 라우팅 메커니즘을 통해 크로스 모달을 효율적으로 처리합니다.
AIMangaStudio는 창작자에게 줄거리 생성, 서브 장면 디자인, 캐릭터 설정 및 기타 기능을 포함한 완벽한 만화 제작 파이프라인을 제공하는 무료 AI 만화 제작 도구로, 스크립트에서 만화 페이지까지 제작 프로세스를 간소화할 수 있습니다. 줄거리, 대사를 포함한 만화 대본의 자연어 생성을 지원합니다.
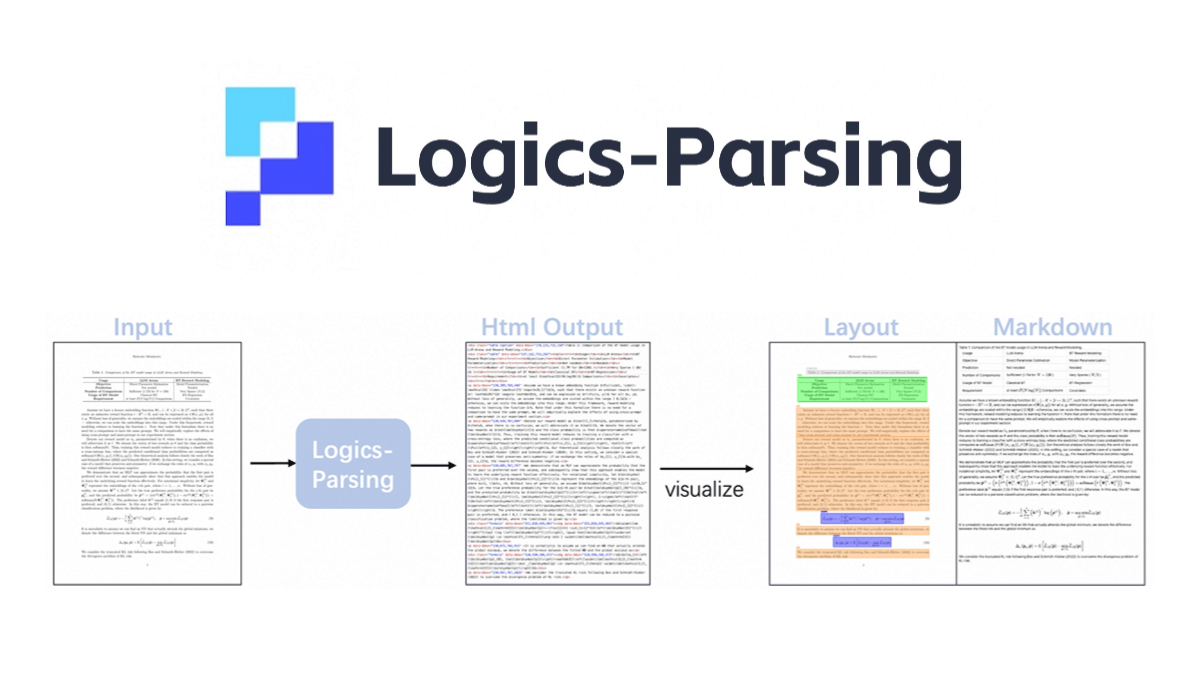
논리 구문 분석은 Qwen2.5-VL-7B를 기반으로하는 Ali 오픈 소스 엔드 투 엔드 문서 구문 분석 모델입니다. 강화 학습을 통해 문서 레이아웃 분석 및 읽기 순서 추론을 최적화하고 PDF 이미지를 구조화 된 HTML 출력으로 변환하고 다양한 콘텐츠를 지원할 수 있습니다 ...
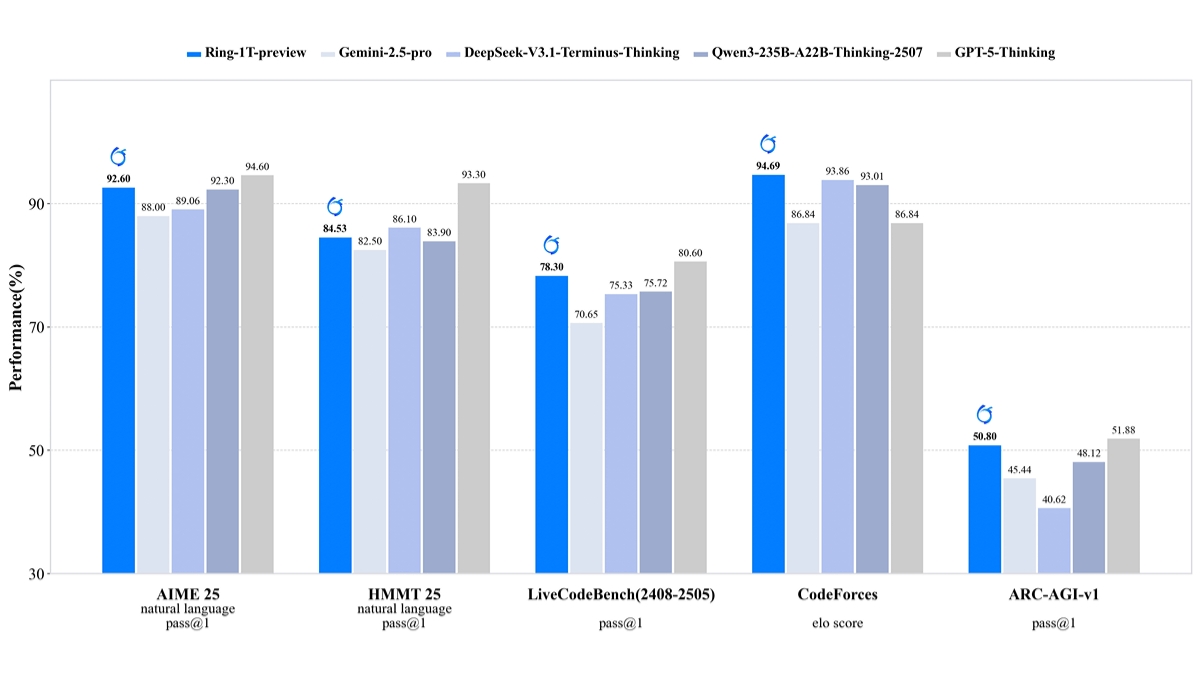
Ring-1T-preview는 Ling 2.0 MoE 아키텍처를 기반으로 하는 Ant Group의 오픈 소스 1조 개 매개변수 매크로 모델로, 20T 코퍼스로 사전 학습되고 자체 개발한 강화 학습 시스템인 ASystem으로 추론 능력을 훈련받았습니다. 자연어 추론에서 ...
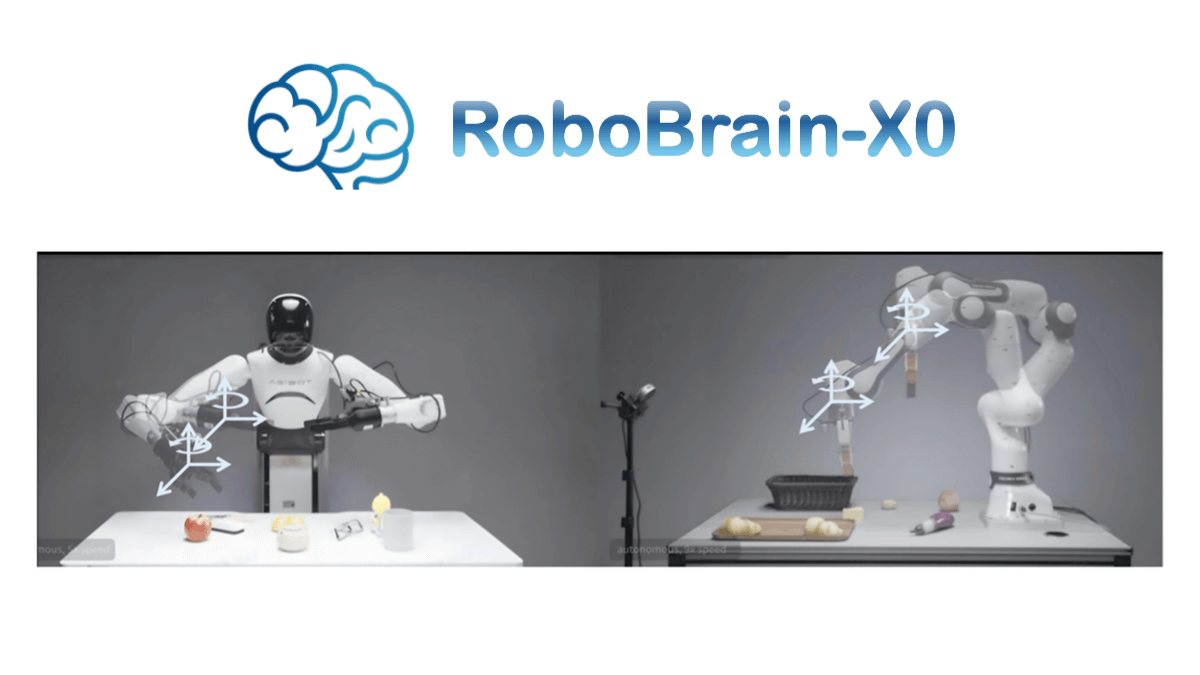
로보브레인-X0은 위즈덤 소스 연구소가 오픈소스로 공개한 세계 최초의 제로 샘플 교차 온톨로지 일반화를 지원하는 오픈소스 구현 모델로, 업계에서 큰 의미를 지니고 있습니다. 다양한 구성의 여러 실제 로봇을 구동하여 미세 조정없이 기본 작동 작업을 완료 할 수 있으며, 소량의 샘플 미세 조정 후 복제 기능을 보여줍니다.
모델 미세 조정(미세 조정)은 머신 러닝에서 전이 학습을 구체적으로 구현한 것입니다. 핵심 프로세스는 대규모 데이터 세트를 사용하여 일반 패턴을 학습하고 광범위한 특징 추출 기능을 개발하는 사전 학습 모델을 기반으로 합니다. 그런 다음 미세 조정 단계에서는 작업별 데이터 세트를 도입하여 ...
훈위안이미지 3.0(훈위안 이미지 3.0)은 텐센트에서 공개하고 오픈소스로 제공한 네이티브 멀티모달 이미지 생성 모델입니다. 모델 매개변수 크기는 80B로, 현재 오픈소스 이미지 생성 모델 중 가장 많은 매개변수를 가진 최고의 평가 결과입니다. 하이브리드 이미지 3.0은 실시간 이미지 생성을 지원하며, 사용자는 측면 ...
후위안 3D 파트(하이브리드 3D 파트)는 텐센트에서 공개하고 오픈소스로 제공하는 3D 생성 모델입니다. P3 - SAM과 X - Part로 구성된 이 모델은 최초로 고정밀 제어가 가능한 컴포넌트 기반 3D 생성을 실현하여 자동으로 생성되는 50개 이상의 컴포넌트를 지원합니다. 사용자는 먼저 사용할 수 있습니다...
AudioFly는 텍스트에서 음향 효과를 생성하기 위한 오픈 소스 AI 모델입니다. 10억 개의 파라미터가 포함된 잠재적 확산 모델 아키텍처를 기반으로 AudioSet, AudioCaps, TUT 및 내부 데이터 세트와 같은 대규모의 다양한 오디오 텍스트 데이터 세트에 대해 학습된 모델입니다.
Hunyuan3D-Omni(하이브리드 3D-옴니)는 텐센트 하이브리드 3D 팀이 개발한 오픈 소스 3D 자산 생성 프레임워크로, 여러 제어 신호를 통해 정확한 3D 모델을 생성할 수 있습니다. Hunyuan3D 2.1 아키텍처를 기반으로 포인트를 처리할 수 있는 통합 제어 인코더를 도입했습니다.
FLM-Audio는 베이징 즈위안 인공지능 연구소가 스핀 매트릭스 및 싱가포르 난양 공과대학교와 함께 출시한 네이티브 전이중 오디오 대화 매크로 모델로, 중국어와 영어를 모두 지원합니다. 네이티브 전이중 아키텍처를 채택하여 각 시간 단계에서 듣기, 말하기 및 독백을 병합 할 수 있습니다 ...
트랜스포머 아키텍처는 기계 번역이나 텍스트 요약과 같은 순차적 작업을 처리하기 위해 설계된 딥러닝 모델입니다. 핵심 혁신은 기존의 루프나 컨볼루션 구조에서 벗어나 자기 주의 메커니즘에만 의존하는 데 있습니다. 이 모델이 시퀀스의 모든 요소를 병렬로 처리할 수 있게 함으로써 대규모...
CWM(코드 월드 모델)은 메타 페어 팀이 공개한 320억 개의 파라미터를 가진 오픈 소스 월드 언어 모델로, 코드 생성 및 추론을 위해 설계되었습니다. 코드 실행 프로세스를 시뮬레이션하고 변수 상태 변화를 예측하고 미리 예측할 수 있는 '월드 모델'이라는 개념을 도입했습니다.
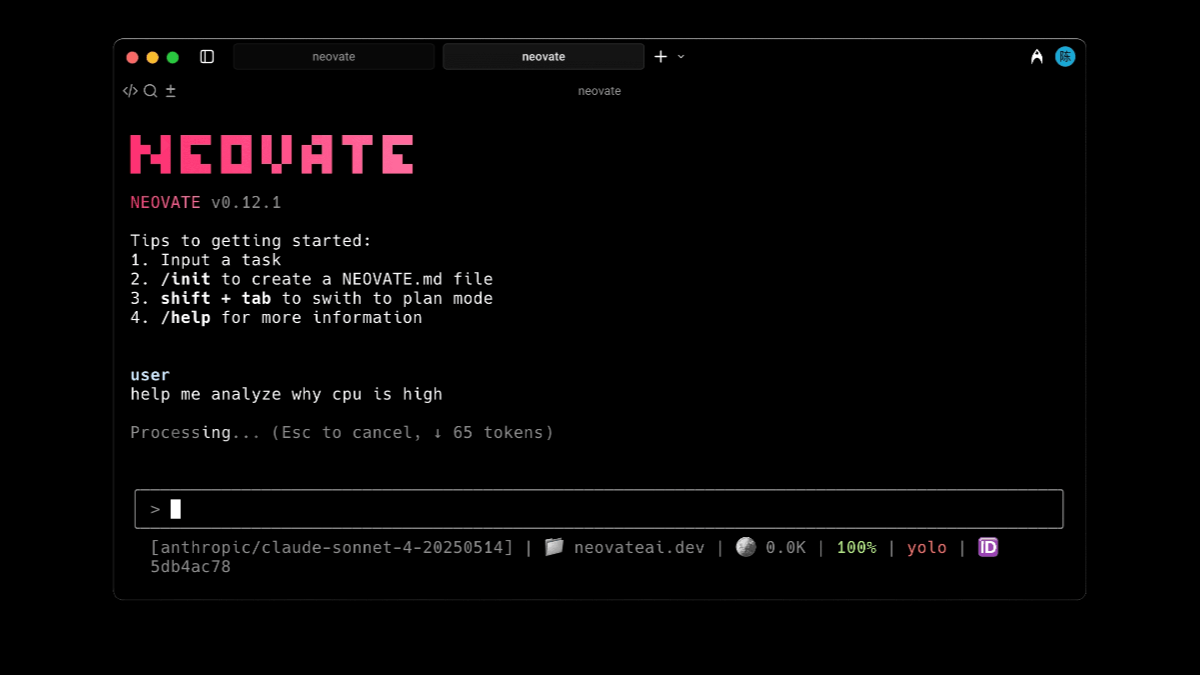
네오베이트 코드는 앤트그룹 알리페이 경험 기술 부서의 오픈소스 지능형 프로그래밍 도우미로, 인공지능 기술을 통해 개발 효율성을 향상시킵니다. 대화형 개발 기능을 통해 개발자는 자연어를 통해 요구 사항을 설명할 수 있으며, Neovate Code는 이를 이해하고 해당 세대를 생성할 수 있습니다.
Qwen3-VL은 알리클라우드 통이 첸첸 팀의 오픈소스 멀티모달 시각 언어 대형 모델로, 235억 개의 참조와 약 471GB의 모델 파일이 있으며, 인스트럭션 및 사고 버전을 포함하고, 향상된 MRope 인터리브 레이아웃, 딥스택 및 기타 기술을 채택하여 시각 변환을 효과적으로 사용할 수 있습니다 ...
Qwen3Guard는 보안 탐지를 위해 설계된 Qwen3 기본 모델을 기반으로 미세 조정된 보안 보호 모델입니다. 프롬프트 및 응답에 대한 정확한 보안 분류를 제공하고 위험 수준을 제공하며 영어, 중국어 및 다국어 환경을 지원합니다.Qwen3Guard는 두 가지 프로 버전으로 제공됩니다.
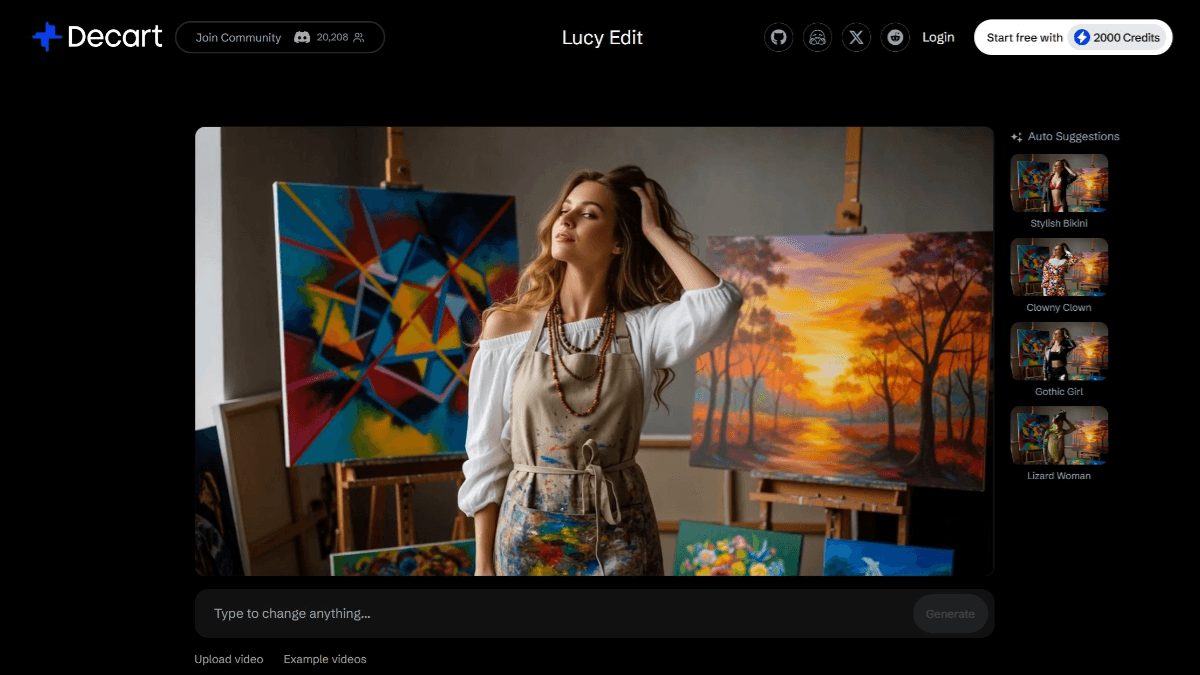
루시 에디터는 Decart AI에서 개발한 오픈 소스 AI 동영상 편집 툴입니다. 사용자는 복잡한 미세 조정이나 마스크 사용 없이도 "캐릭터를 북극곰으로 바꿔" 또는 "장면을 2D 만화 스타일로 바꿔"와 같은 간단한 자연어 설명을 통해 동영상을 편집할 수 있습니다....
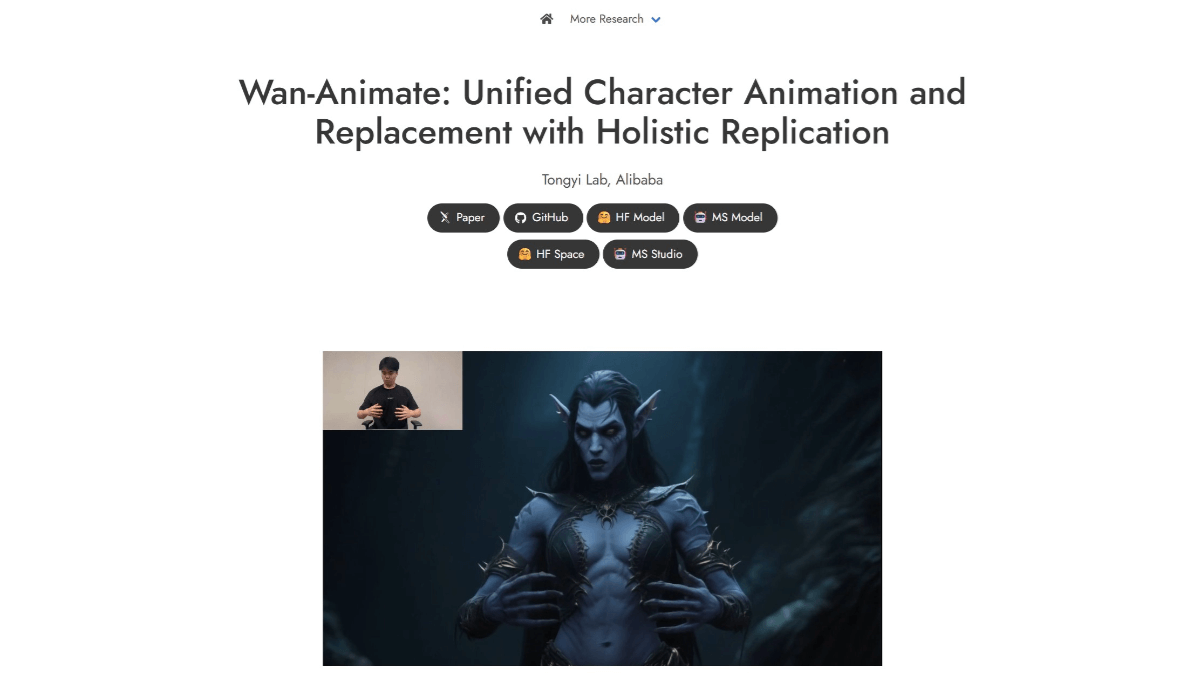
완2.2-애니메이트는 통이완샹의 오픈 소스 액션 생성 모델로, 액션 모방과 롤플레잉의 두 가지 모드를 지원합니다. 사용자는 캐릭터 사진과 참조 비디오 만 입력하면 모델이 비디오 캐릭터의 움직임과 표정을 그림 캐릭터로 마이그레이션하여 그림 캐릭터에 역동적 인 표현을 제공 할 수 있습니다 ...
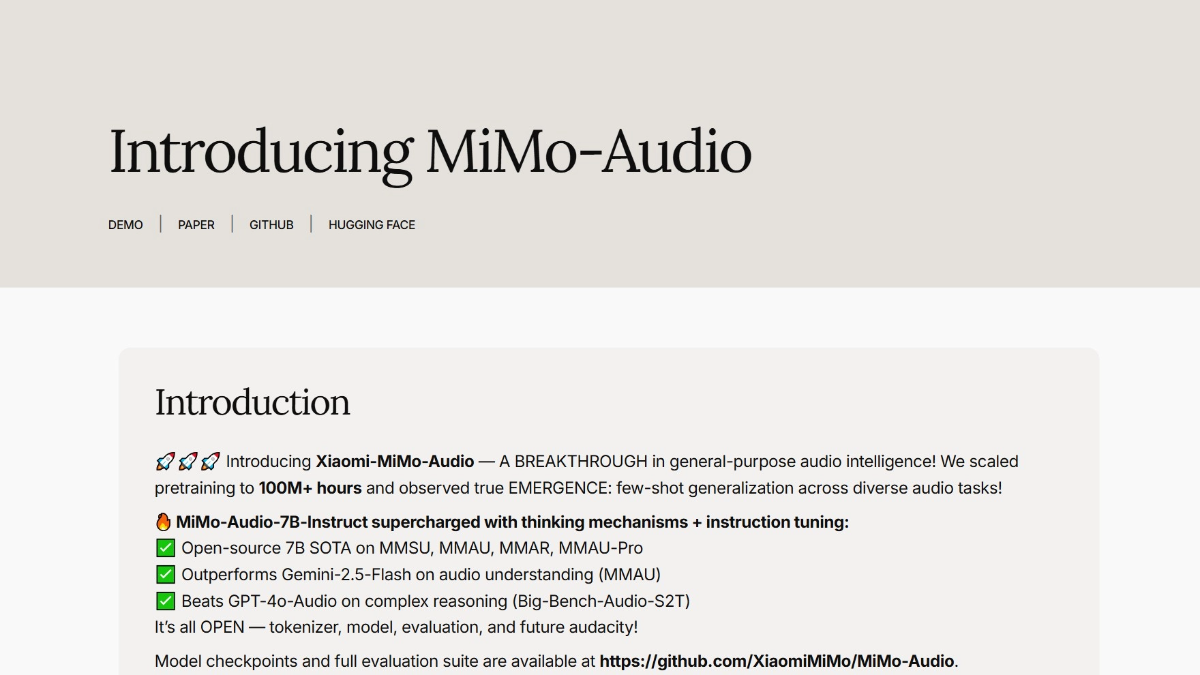
샤오미 미모 오디오는 다국어 대화, 음성 연속, 적은 샘플 일반화 및 오디오 이해와 같은 강력한 기능을 갖춘 샤오미의 오픈 소스 70억 개 파라미터 엔드투엔드 음성 매크로 모델로, 음성 지능 및 오디오 이해 벤치마크에서 구글 제미를 능가하는 SOTA 레벨에 도달할 수 있습니다.
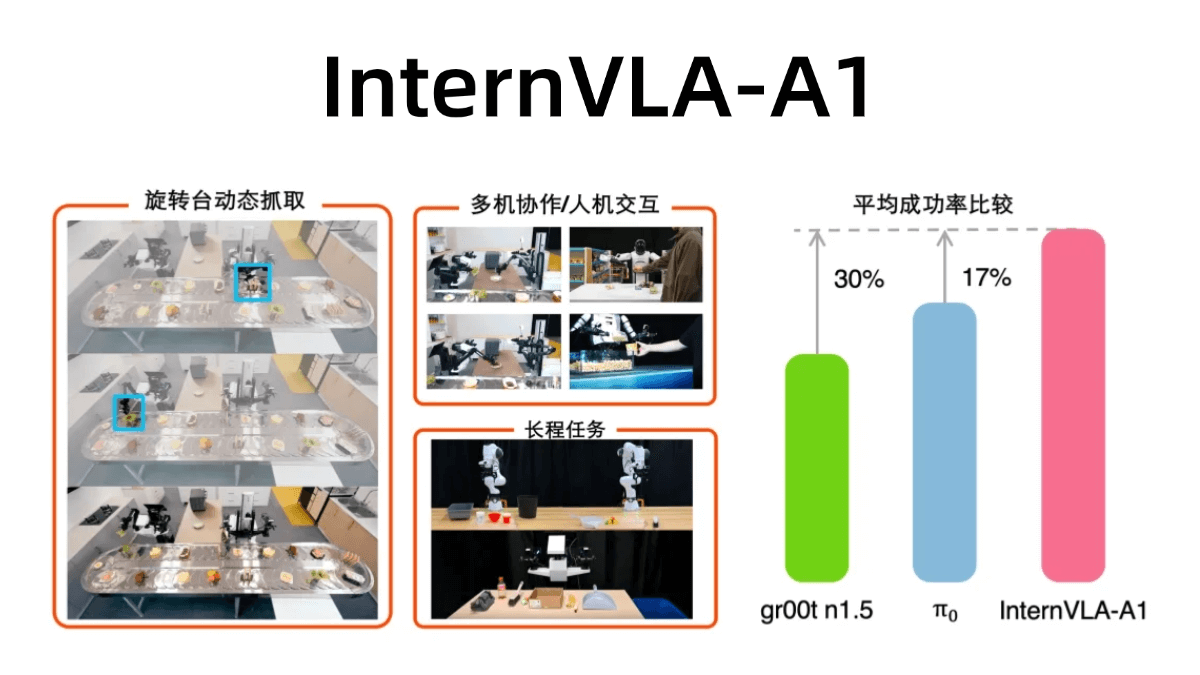
InternVLA-A1은 상하이 인공 지능 연구소에서 오픈소스로 제공하는 대규모 구현 작업 모델입니다. 통합을 이해하고, 상상하고, 실행할 수 있는 능력을 갖추고 있으며, 작업을 정확하게 완료할 수 있습니다. 이 모델은 실제 및 시뮬레이션 운영 데이터를 융합하고 대규모 가상-실제 하이브리드 장면 에셋을 통해 대규모 멀티모달 구축을 자동화합니다.
VoxCPM은 Facade Intelligence와 칭화대학교 선전 국제대학원이 공동으로 오픈소스화한 음성 생성 모델로, 엔드투엔드 확산 자동 회귀 아키텍처를 채택하여 텍스트에서 직접 연속 음성 표현을 생성함으로써 기존의 이산적 명료화의 한계를 극복합니다. 계층적 언어 모델링과 유한 상태 양자화를 통해 ...
InternVLA-N1은 상하이 인공 지능 연구소에서 오픈소스화한 엔드투엔드 듀얼 시스템 내비게이션 매크로 모델입니다. 이중 시스템 아키텍처를 사용하여 시스템 2는 언어 명령을 이해하고 장거리 경로를 계획하고, 시스템 1은 고주파 응답과 민첩한 장애물 회피에 중점을 둡니다. 이 모델은 전적으로 대규모 디지털을 통한 합성 데이터를 기반으로 훈련됩니다.
VLAC은 상하이 인공지능 연구소에서 오픈소스로 구현한 보상 매크로 모델입니다. InternVL 다중 모드 매크로 모델을 기반으로 인터넷 비디오 데이터와 로봇 작동 데이터를 통합하여 실제 세계에서 로봇 강화 학습을위한 프로세스 보상 및 작업 완료 추정을 제공합니다.VLAC는 효과적으로 ...
InternVLA-M1은 상하이 인공 지능 연구소의 오픈 소스로 구현된 운영 '두뇌'로, 명령에 따라 작동하는 두 가지 시스템 운영의 대형 모델입니다. 이 모델은 '사고-행동-학습'을 포괄하는 완전한 폐쇄 루프를 구축하며 높은 수준의 공간 추론과 작업 계획을 담당합니다. 이 모델은 2단계 교육 정책을 채택합니다 ...
대규모 모델 기초는 대규모 언어 모델(LLM)의 핵심 기술과 실무 경로를 심도 있게 분석합니다. 언어 모델링의 기초 이론부터 시작해 통계, 순환신경망(RNN), 트랜스포머 아키텍처를 기반으로 한 모델 설계 원리를 3대 대규모 언어 모델에 초점을 맞춰 체계적으로 설명합니다.
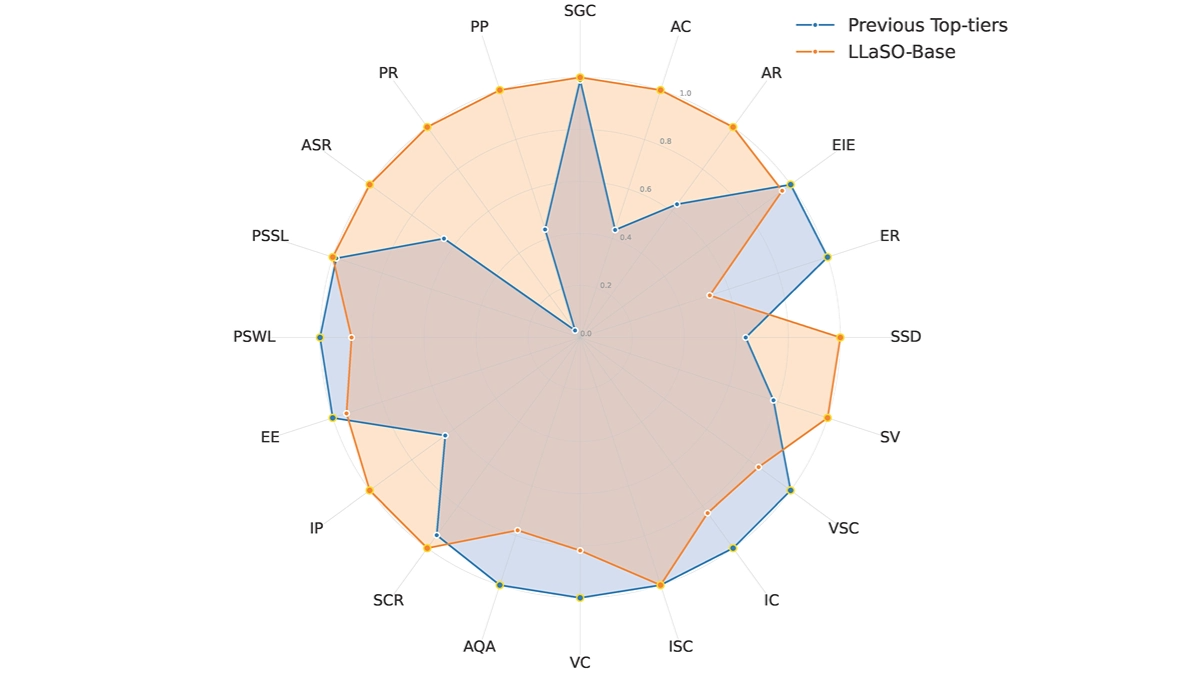
LLaSO는 베이징 뎁스 로직 인텔리전스 테크놀로지가 출시한 오픈 소스 음성 모델로, 음성 및 텍스트 데이터를 통합하고 정렬 데이터 세트, 명령 미세 조정 데이터 세트 및 평가 벤치마크를 제공하여 대규모 음성 언어 모델링 분야의 데이터 분산과 작업 범위 부족 문제를 해결합니다.
하이브리드 3D 3.0은 3D-DiT 계층적 조각 기술을 기반으로 한 텐센트의 고급 3D 세대 모델로, 최대 1536³의 기하학적 해상도로 초고화질, 디테일이 풍부한 3D 모델을 생성할 수 있으며 오감 및 체형을 정확하게 형상화하는 등 캐릭터 모델링에 탁월한 능력을 갖추고 있습니다.
UnifoLM-WMA-0은 일반 로봇 학습을 위해 설계된 유슈 테크놀로지의 여러 로봇 온톨로지 클래스에 걸친 오픈 소스 월드 모델-액션 아키텍처입니다. 월드 모델과 액션 아키텍처로 구성된 월드 모델은 로봇과 환경 상호 작용의 물리적 법칙을 이해하고, 액션 아키텍처는 특정 동작을 담당합니다.
Lumina-DiMOO는 세계 인공지능 컨퍼런스 2025에서 화웨이 라이즈와 함께 상하이 인공 지능 연구소(AIL)가 출시한 차세대 멀티모달 생성 및 이해를 위한 통합 모델입니다. Rise AI 기본 하드웨어 및 소프트웨어 플랫폼과 MindSpeed MM 멀티모달 대형 모델 제품군을 기반으로 ...
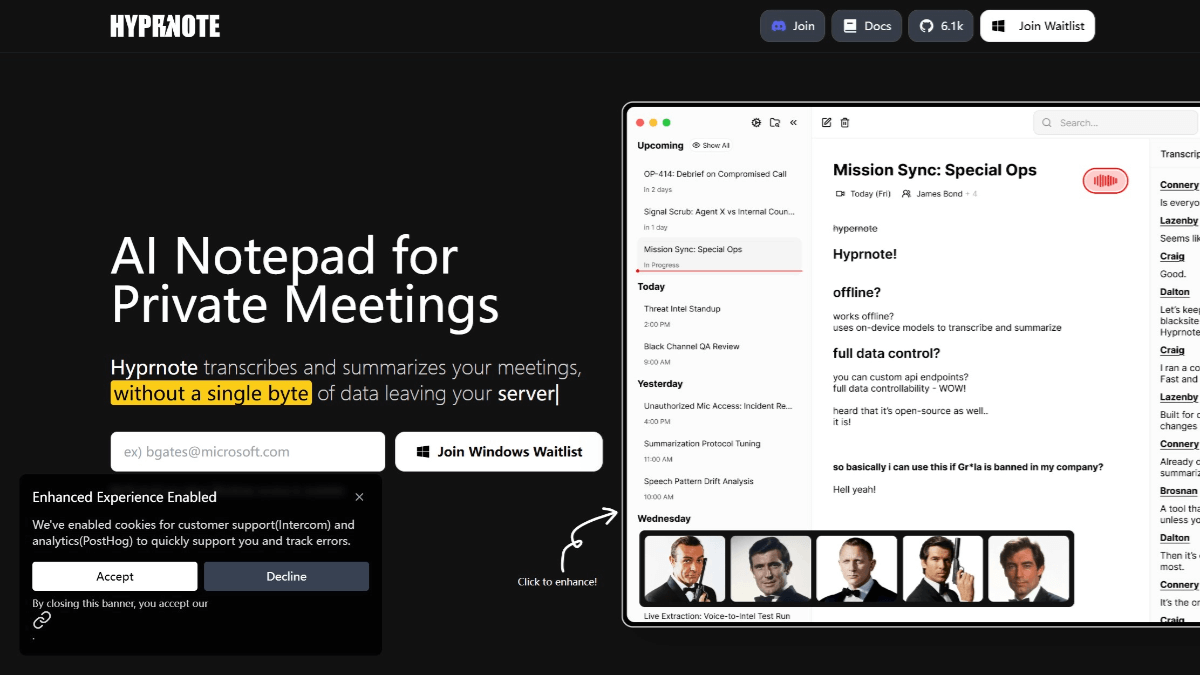
하이프노트는 사용자의 개인정보를 보호하고 회의 효율성을 개선하기 위해 전문가를 위해 설계된 로컬 우선의 오픈 소스 AI 회의 노트 필기 도구입니다. '로컬 우선' 원칙을 채택하여 모든 데이터 저장과 처리가 사용자의 로컬 장치에서 이루어지므로 데이터 보안을 보장하고 오프라인 작업을 지원합니다.
MobileLLM-R1은 수학적, 프로그래밍 및 과학적 추론을 위해 설계된 Meta의 효율적인 추론 모델 오픈 소스 시리즈입니다. 여기에는 각각 1억 4천만 개, 3억 6천만 개, 9억 5천만 개의 매개변수 버전이 포함된 기본 모델과 최종 모델이 포함되어 있습니다. 이 모델은 일반적인 채팅 모델이 아니며 미세 조정(SFT...
ERNIE-4.5-21B-A3B-Thinking은 추론 작업에 초점을 맞춘 바이두의 오픈 소스 대규모 언어 모델입니다. 혼합 전문가(MoE) 아키텍처를 사용하여 총 참조 수는 210억 개에 달하며, 각 토큰은 30억 개의 매개 변수를 활성화하여 128K의 긴 컨텍스트 창을 지원합니다 ...
모비에이전트는 상하이교통대학교 IPADS 연구소의 오픈 소스 모바일 지능형 바디 툴 체인으로, 사용자가 자신만의 모바일 지능형 비서를 구축할 수 있도록 도와줍니다. 사용자의 동작 궤적을 기록하고 고품질 데이터를 생성하여 자연어 명령을 이해할 수 있는 지능형 바디를 훈련시킵니다. 핵심 기능에는 효율적인...
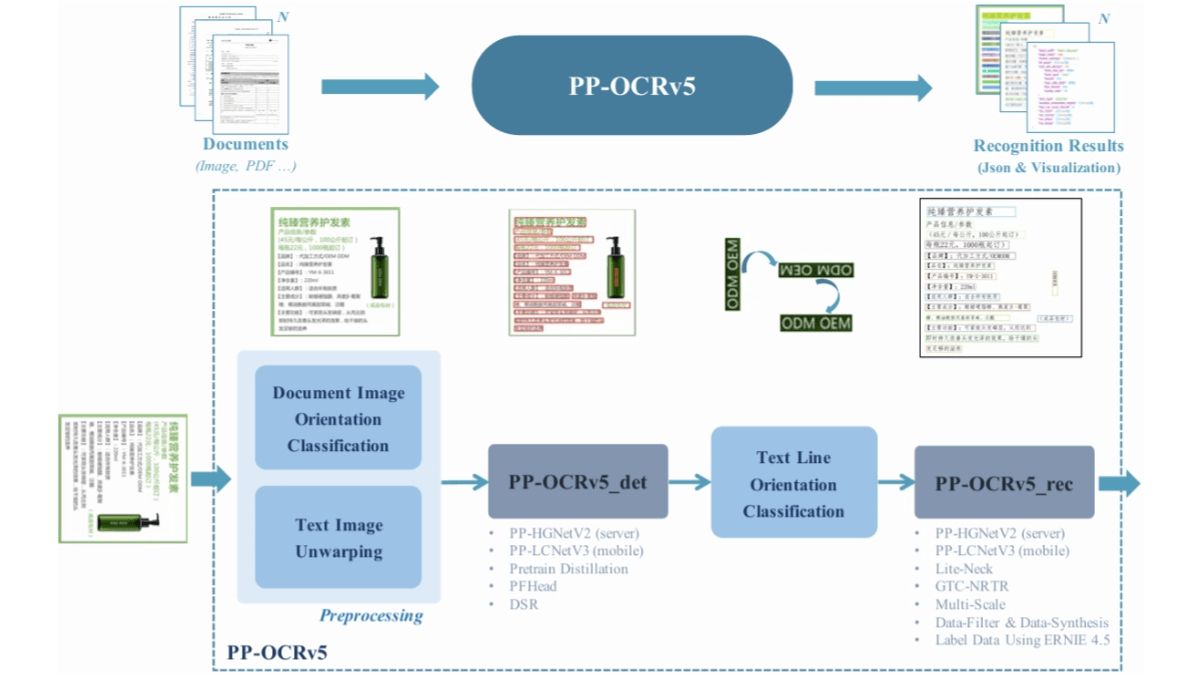
PP-OCRv5는 바이두에서 출시한 최신 세대의 텍스트 인식 AI 모델입니다. 경량 설계와 0.07B에 불과한 참조 개수로 CPU와 엣지 디바이스에서 효율적으로 실행하기에 적합하며 초당 370개 이상의 문자를 처리할 수 있습니다. 이 모델은 중국어 간체, 중국어 번체, 영어, 일본어, 병음...을 지원합니다.
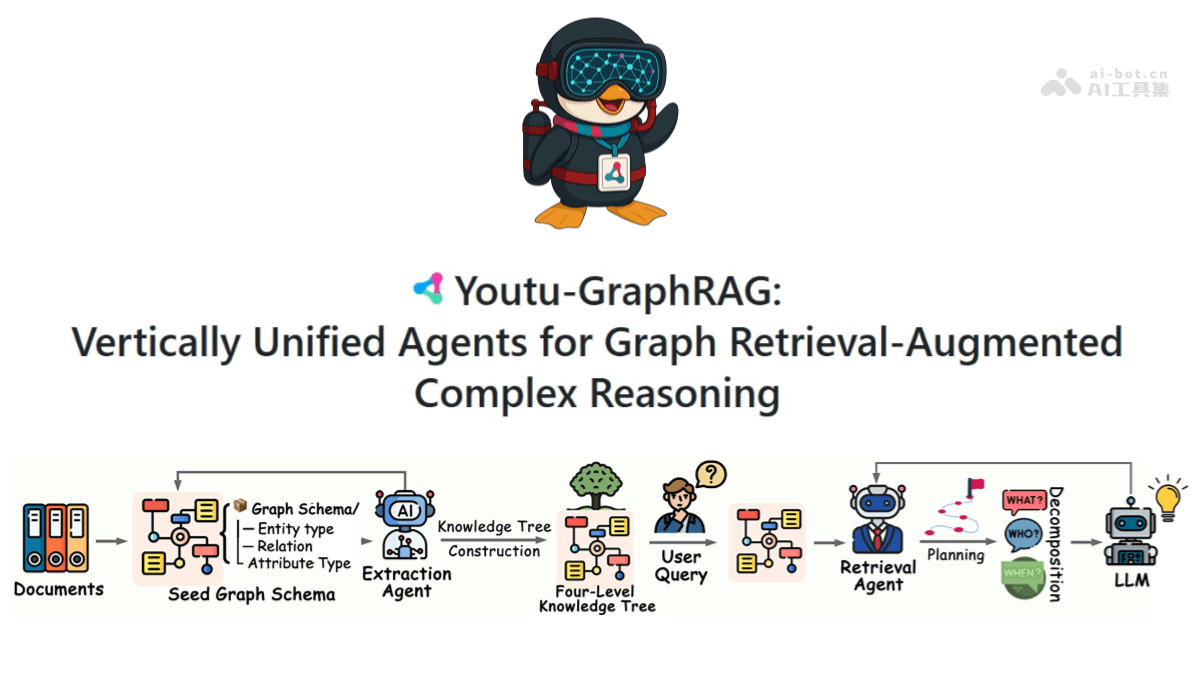
Youtu-GraphRAG는 대규모 언어 모델이 복잡한 Q&A 작업을 보다 정확하게 처리할 수 있도록 지원하는 텐센트 유투 연구소의 오픈 소스 그래프 검색 증강 생성 프레임워크입니다. 4계층 지식 트리를 구성하여 지식을 속성, 관계, 키워드 및 커뮤니티의 네 가지 수준으로 분해하여 행위의 자기 숙달에 대한 교차 도메인 지식을 달성합니다....
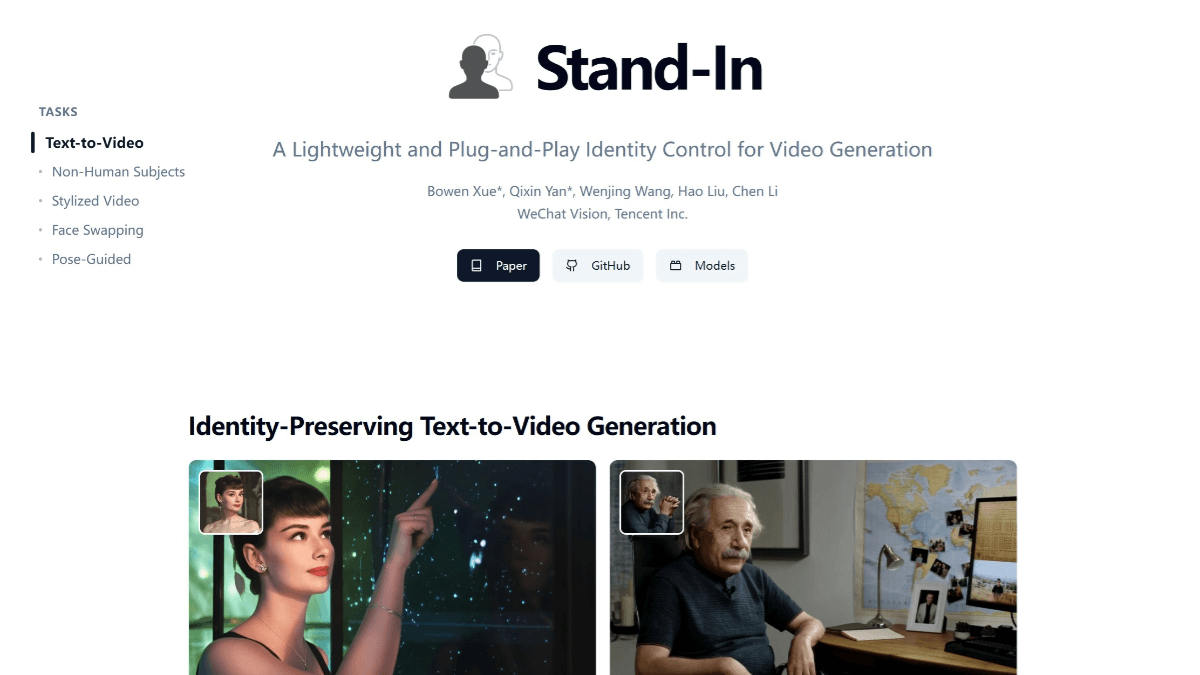
스탠드인(Stand-In)은 텐센트 WeChat 비전 팀이 개발한 가벼운 플러그 앤 플레이 방식의 신원 보존 동영상 생성 프레임워크입니다. 동영상 생성 시 특정 신원 특징을 보존하는 데 초점을 맞춘 이 프레임워크는 기본 모델 1%의 추가 파라미터만 학습하면 얼굴 유사성과 자연스러움에서 탁월한 결과를 얻을 수 있습니다.
IndexTTS2는 B 스테이션 음성 팀이 오픈소스화한 새로운 무료 텍스트 음성 변환(TTS) 모델로, 감정 표현과 지속 시간 제어에서 획기적인 발전을 이루었으며, 정밀한 지속 시간 제어를 지원하는 최초의 자동 회귀형 TTS 모델입니다. 제로 샘플 음성 복제를 지원하며 하나의 오디오 파일 만 사운드를 정확하게 복사 할 수 있습니다....
미니맥스 뮤직 1.5는 사용자의 자연어 설명을 기반으로 최대 4분 분량의 음악 생성을 지원하는 고급 AI 음악 생성 도구입니다. 이 모델은 다양한 음악 스타일과 분위기 사용자 지정을 지원하며 자연스럽고 완전한 보컬 톤, 부드러운 전환 및 풍부한 레이어 편곡을 생성합니다....