
일반 소개
TangoFlux는 DeCLaRe Lab에서 개발한 효율적인 텍스트-오디오(TTA) 생성 모델입니다. 이 모델은 3.7초 만에 최대 30초 분량의 44.1kHz 스테레오 오디오를 생성할 수 있습니다. TangoFlux는 스트림 매칭과 CRPO(박수 순위 선호도 최적화) 기술을 사용하여 선호도 데이터를 생성하고 최적화함으로써 TTA 정렬을 향상시킵니다. 이 모델은 객관적 벤치마크와 주관적 벤치마크 모두에서 우수한 성능을 보이며, 모든 코드와 모델은 오픈 소스로 제공되어 추가적인 TTA 생성 연구를 지원합니다.

체험: https://huggingface.co/spaces/declare-lab/TangoFlux
싱가포르 기술 디자인 대학(SUTD)과 엔비디아는 단일 A40 GPU에서 단 3.7초 만에 최대 44.1kHz 오디오를 생성할 수 있는 약 1억 1,500만 개의 파라미터를 갖춘 고효율 텍스트-오디오(TTA) 생성 모델인 TangoFlux를 공동 출시했습니다. 약 5억 1,500만 개의 파라미터를 갖춘 이 모델은 단일 A40 GPU에서 단 3.7초 만에 최대 30초 분량의 44.1kHz 오디오를 생성할 수 있습니다. TangoFlux는 초고속 생성 속도뿐만 아니라 Stable Audio와 같은 오픈소스 오디오 모델보다 우수한 오디오 품질을 제공합니다.
다른 최신 오픈 소스 텍스트-오디오 생성 모델과 TANGoFLux를 비교해보면, 가장 빠른 모델보다 약 2배 빠르게 생성할 뿐만 아니라 더 나은 오디오 품질(CLAP 및 FD 점수로 측정)을 달성하며, 이 모든 것을 더 적은 수의 학습 가능한 파라미터로 구현합니다.

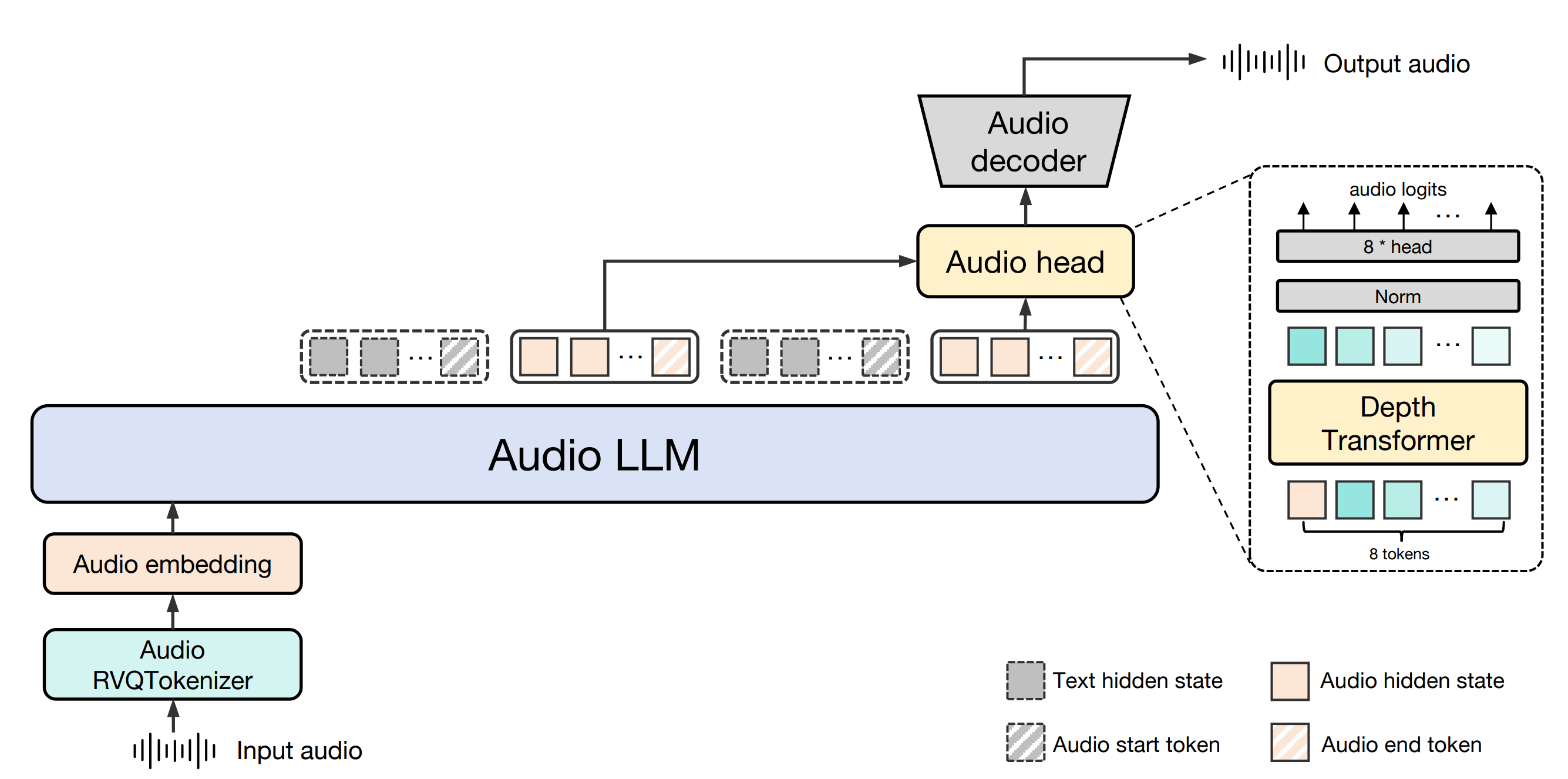
"스트림 매칭 및 박수 순위 선호도 최적화를 통한 초고속의 충실한 텍스트-오디오 생성"이라는 제목의 TangoFlux는 텍스트 단서와 길이 임베딩을 조건으로 최대 30초의 44.1kHz 오디오를 생성하는 확산 트랜스포머(DiT) 및 다중 모드 확산 트랜스포머(MMDiT)인 FluxTransformer 블록으로 구성됩니다. 텍스트 단서 및 지속 시간 임베딩을 조건으로 최대 30초 길이의 44.1kHz 오디오를 생성하는 확산 트랜스포머(DiT) 및 멀티모달 확산 트랜스포머(MMDiT)는 가변 자동 인코더(VAE)로 인코딩된 오디오의 잠재적 표현의 정류된 스트리밍 궤적을 학습합니다.TangoFlux 학습 파이프라인은 사전 학습, 미세 조정 및 CRPO를 사용한 기본 설정 최적화의 세 단계로 구성됩니다. 특히 CRPO는 새로운 합성 데이터를 반복적으로 생성하고 스트림 매칭을 위한 선호도 최적화를 위해 DPO 손실을 사용하여 선호도 쌍을 구성합니다.

기능 목록
- 빠른 오디오 생성3.7초 만에 최대 30초 분량의 고품질 오디오를 생성합니다.
- 스트림 매칭 기술플럭스 트랜스포머와 멀티모달 확산 트랜스포머를 사용한 오디오 생성.
- CRPO 최적화환경설정 데이터를 생성하고 최적화하여 오디오 생성 품질을 향상시킵니다.
- 다단계 교육사전 교육, 미세 조정 및 환경 설정 최적화의 세 단계로 구성됩니다.
- 오픈 소스모든 코드와 모델은 추가 연구를 지원하기 위해 오픈소스로 공개됩니다.
도움말 사용
설치 프로세스
- 환경 구성파이썬 3.7 이상이 설치되어 있고 필요한 종속 라이브러리가 설치되어 있는지 확인합니다.
- 클론 창고터미널에서 실행
git clone https://github.com/declare-lab/TangoFlux.git복제 창고. - 종속성 설치프로젝트 디렉토리로 이동하여
pip install -r requirements.txt모든 종속성을 설치합니다.
사용 프로세스
- 모델 교육::
- 구성 가속기: 실행
accelerate config를 클릭하고 지시에 따라 런타임 환경을 구성합니다. - 교육 파일 경로 구성: 교육 파일 경로의
configs/tangoflux_config.yaml에서 학습 파일 경로와 모델 하이퍼파라미터를 지정합니다. - 교육 스크립트 실행: 다음 명령을 사용하여 교육을 시작합니다:
CUDA_VISIBLE_DEVICES=0,1 accelerate launch --config_file='configs/accelerator_config.yaml' src/train.py --checkpointing_steps="best" --save_every=5 --config='configs/tangoflux_config.yaml'- DPO 교육: '선택됨', '거부됨', '캡션' 및 '기간' 필드를 포함하도록 교육 파일을 수정하고 다음 명령을 실행합니다:
CUDA_VISIBLE_DEVICES=0,1 accelerate launch --config_file='configs/accelerator_config.yaml' src/train_dpo.py --checkpointing_steps="best" --save_every=5 --config='configs/tangoflux_config.yaml' - 구성 가속기: 실행
- 모델링된 추론::
- 모델 다운로드: TangoFlux 모델을 다운로드했는지 확인합니다.
- 오디오 생성: 다음 코드를 사용하여 텍스트 프롬프트에서 오디오를 생성할 수 있습니다:
import torchaudio from tangoflux import TangoFluxInference from IPython.display import Audio model = TangoFluxInference(name='declare-lab/TangoFlux') audio = model.generate("生成音频的文本提示", duration=10) Audio(audio, rate=44100)
세부 기능 작동
- 텍스트-오디오 생성텍스트 프롬프트를 입력하고 생성되는 오디오의 지속 시간(1~30초)을 설정하면 모델에서 해당 고품질 오디오를 생성합니다.
- 최적화에 대한 편향성CRPO 기술을 통해 사용자의 선호도에 더 부합하는 오디오를 생성할 수 있습니다.
- 다단계 교육모델이 생성하는 오디오의 품질과 일관성을 보장하기 위해 사전 학습, 미세 조정 및 기본 설정 최적화의 세 단계로 구성됩니다.
주의
- 하드웨어 요구 사항최적의 성능을 위해 더 높은 연산 능력을 갖춘 GPU(예: A40)를 사용하는 것이 좋습니다.
- 데이터 준비모델 생성을 개선하기 위해 학습 데이터의 다양성과 품질을 보장합니다.
이 단계를 통해 사용자는 고품질 텍스트-오디오 변환을 위해 TangoFlux를 빠르게 시작할 수 있습니다. 자세한 설치 및 사용 지침을 통해 사용자는 모델 훈련 및 추론 프로세스를 성공적으로 완료할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서

댓글 없음...