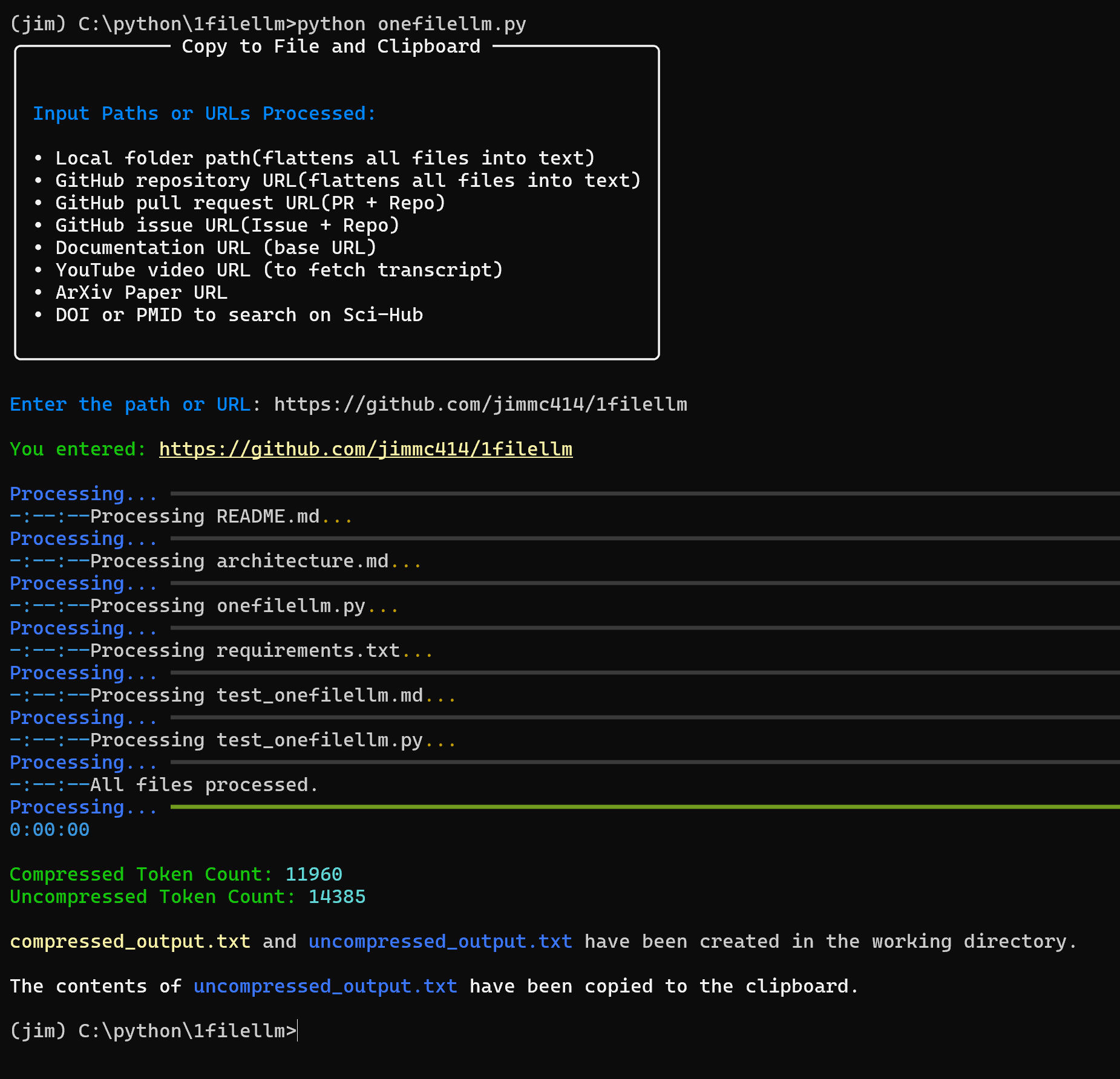
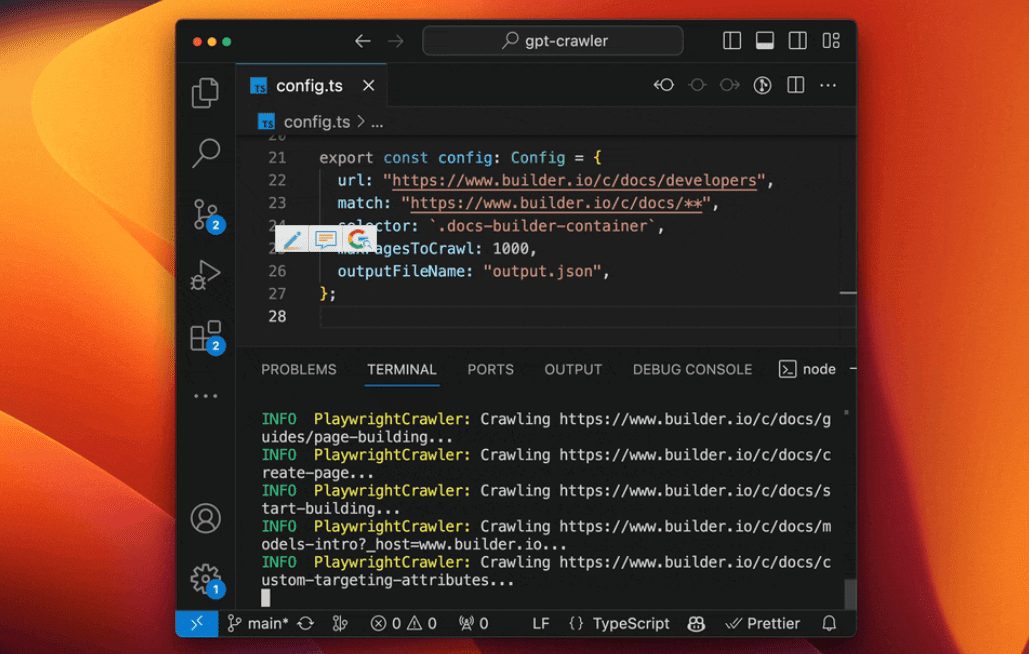
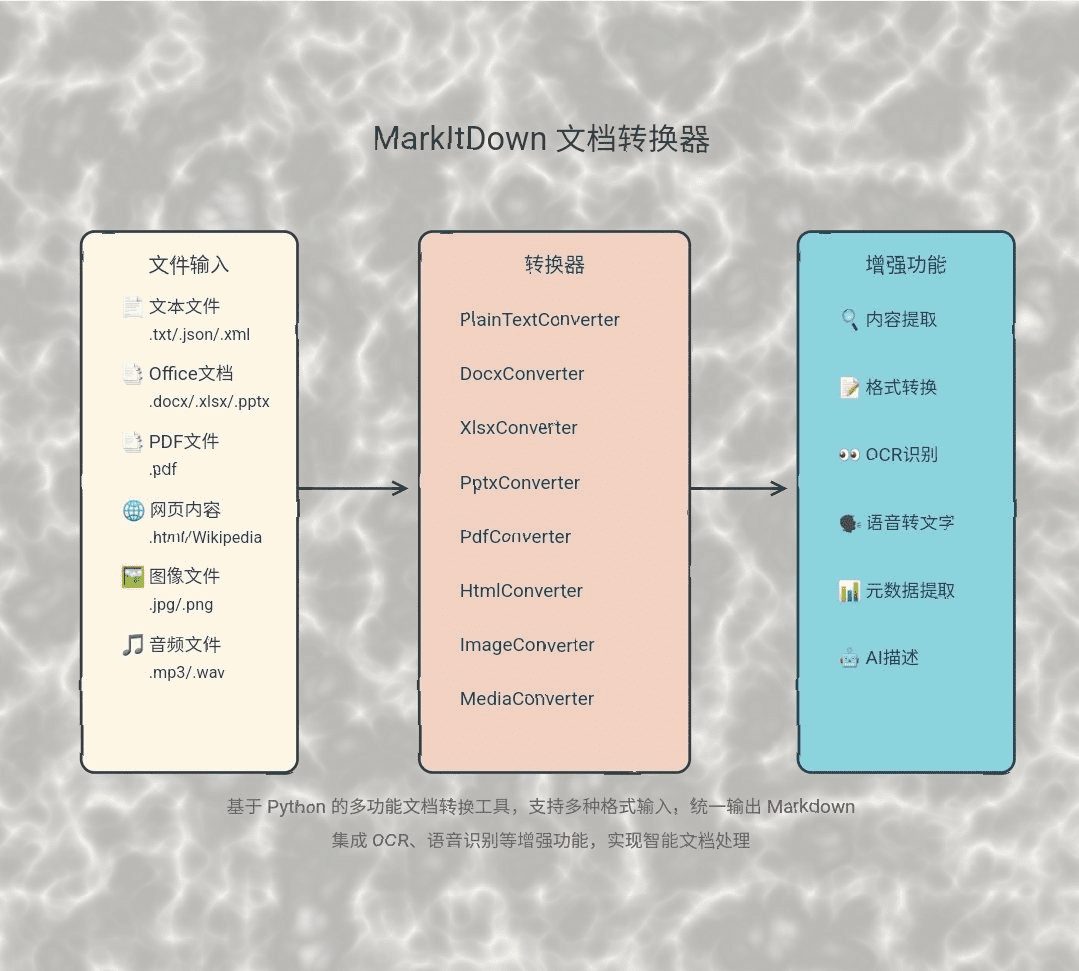
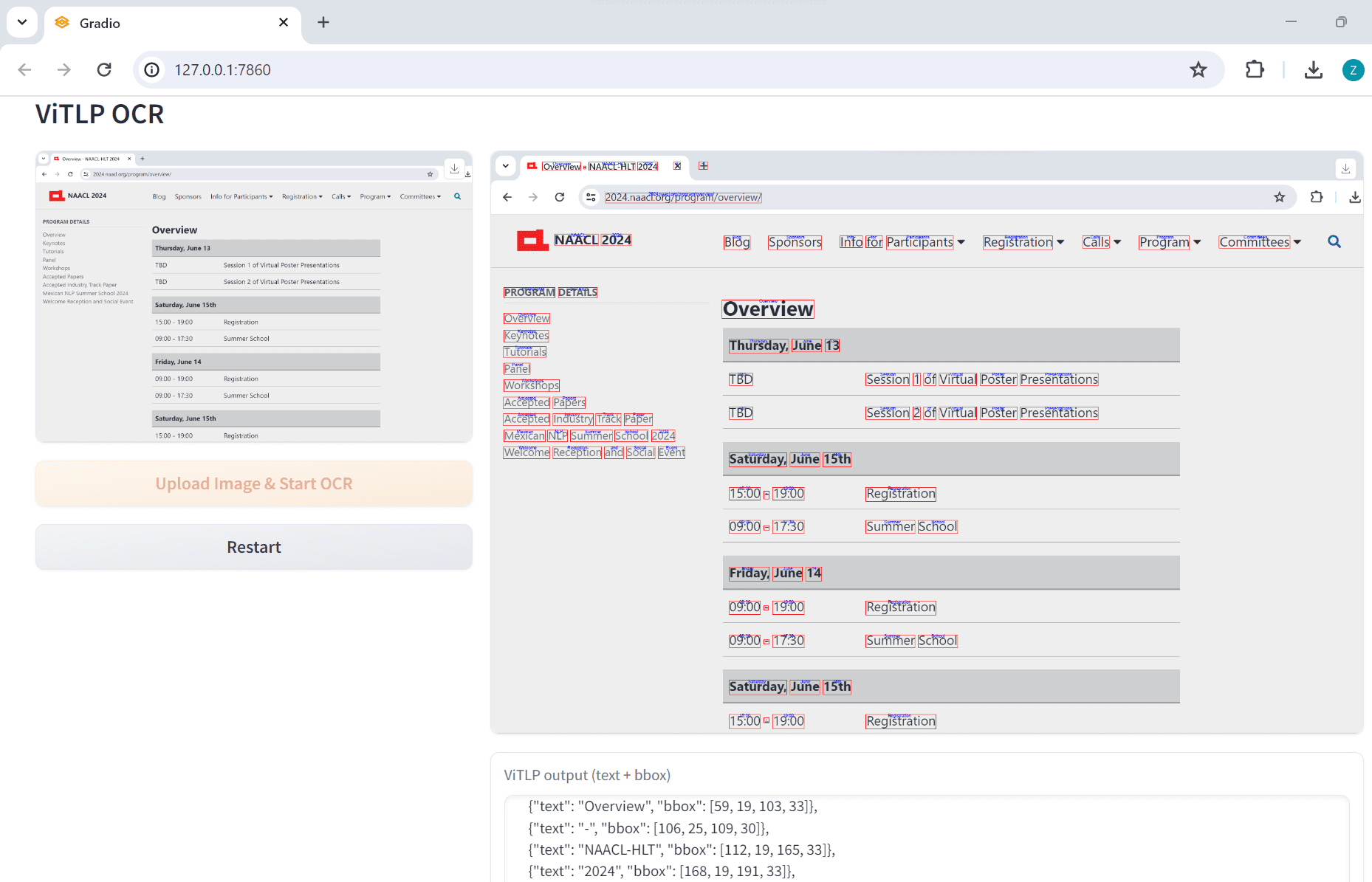
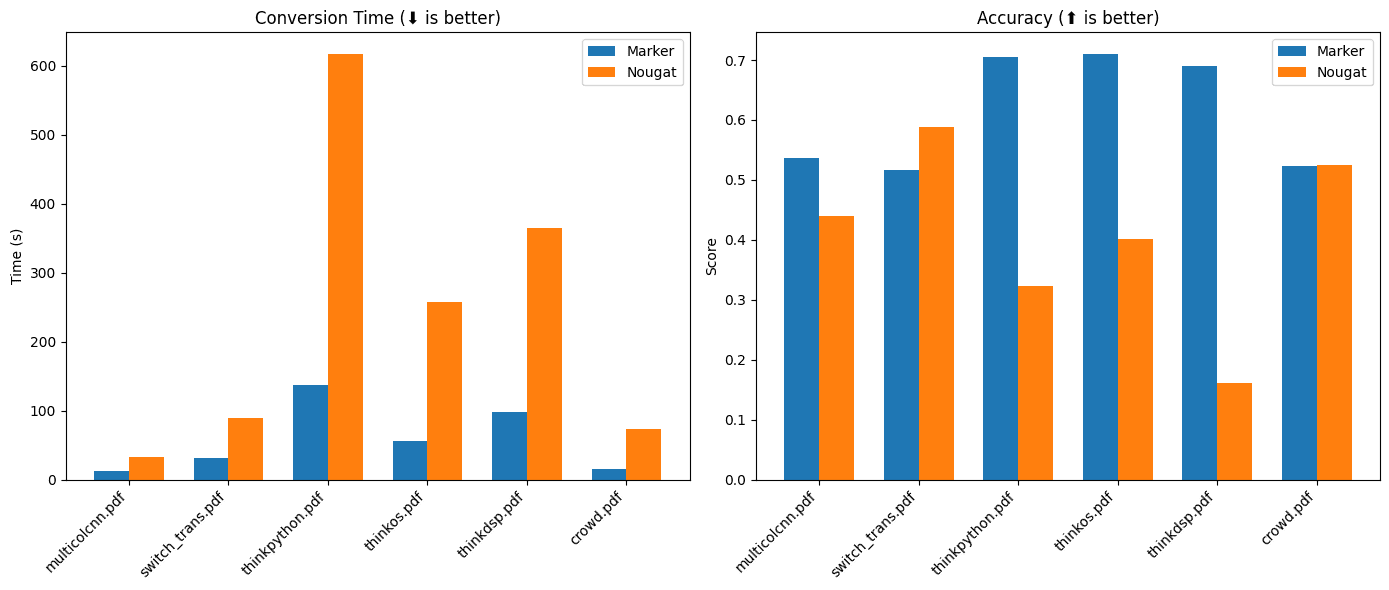
일반 소개 Chatlog는 WeChat의 로컬 데이터베이스에서 채팅 로그를 추출하고 쿼리하는 데 중점을 둔 오픈 소스 도구입니다. 이 도구는 WeChat 버전 3.x와 4.0을 지원하며, Windows와 macOS 시스템을 모두 포괄합니다. 사용자는 명령줄, 터미널 인터페이스 또는 H...
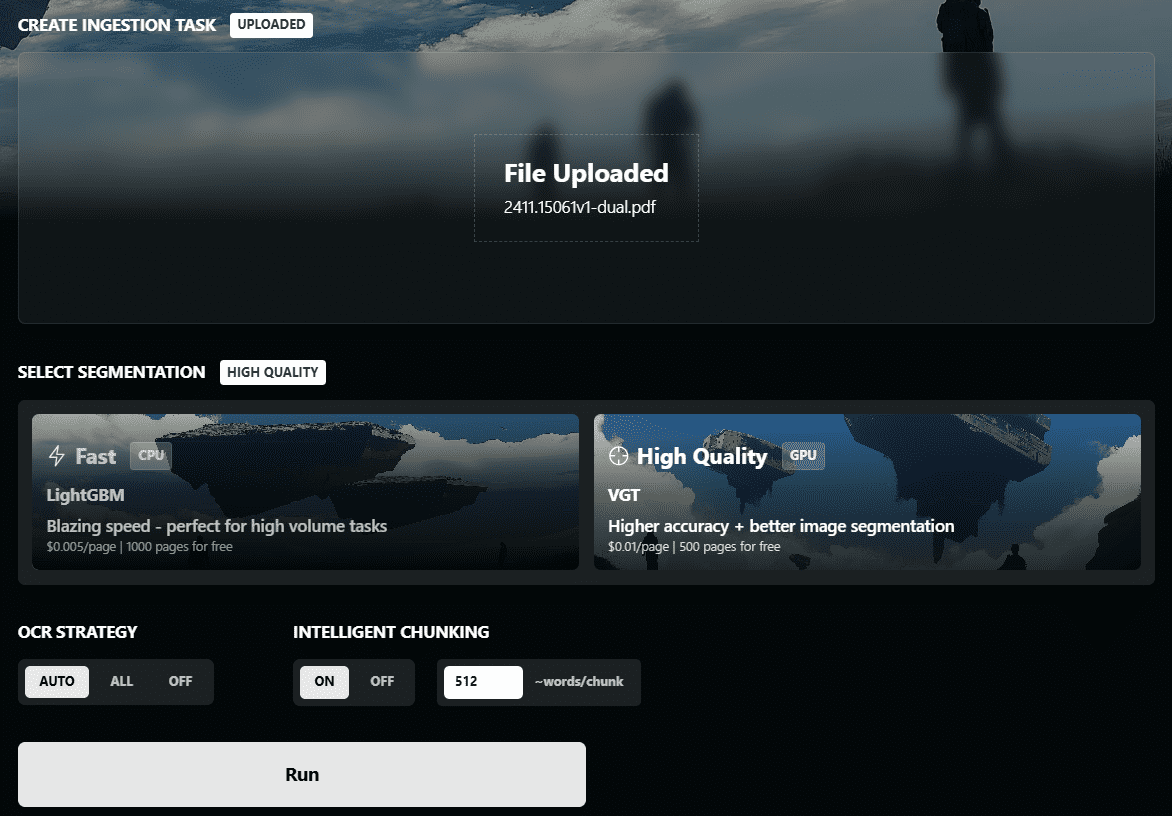
종합 소개 PDF 문서의 레이아웃을 자동으로 분석하고 페이지의 텍스트, 제목, 이미지, 표, 수식 및 기타 요소를 식별하며 올바른 순서를 결정합니다. 이 도구는 OCR 기능을 지원하며 스캔한 PDF를 검색 가능한 텍스트로 변환할 수 있습니다. Docker에서 실행되며 두 가지 모델을 제공합니다...
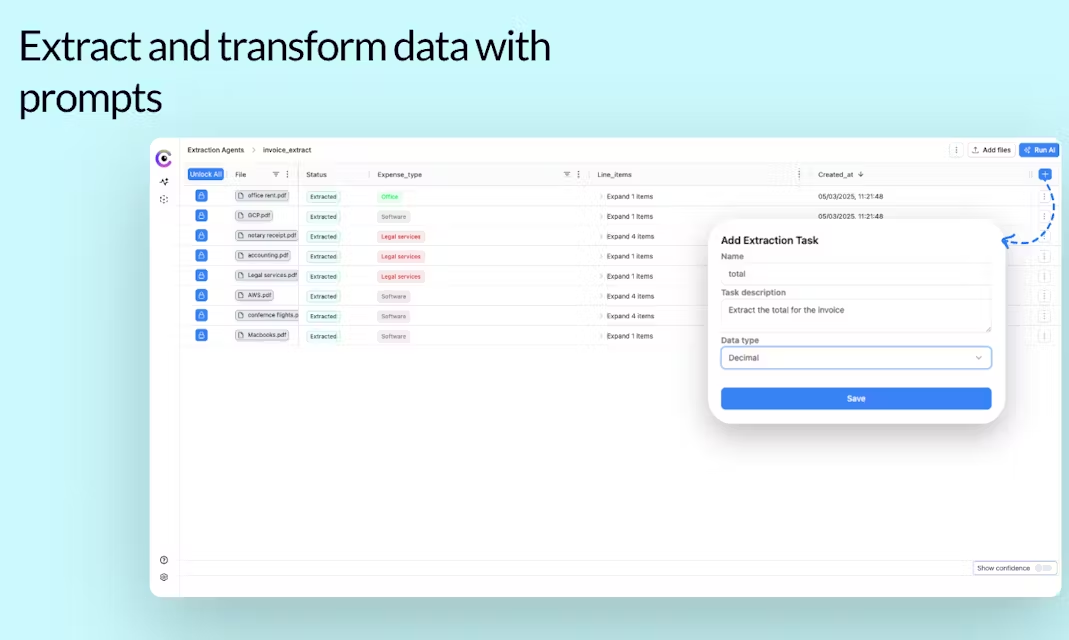
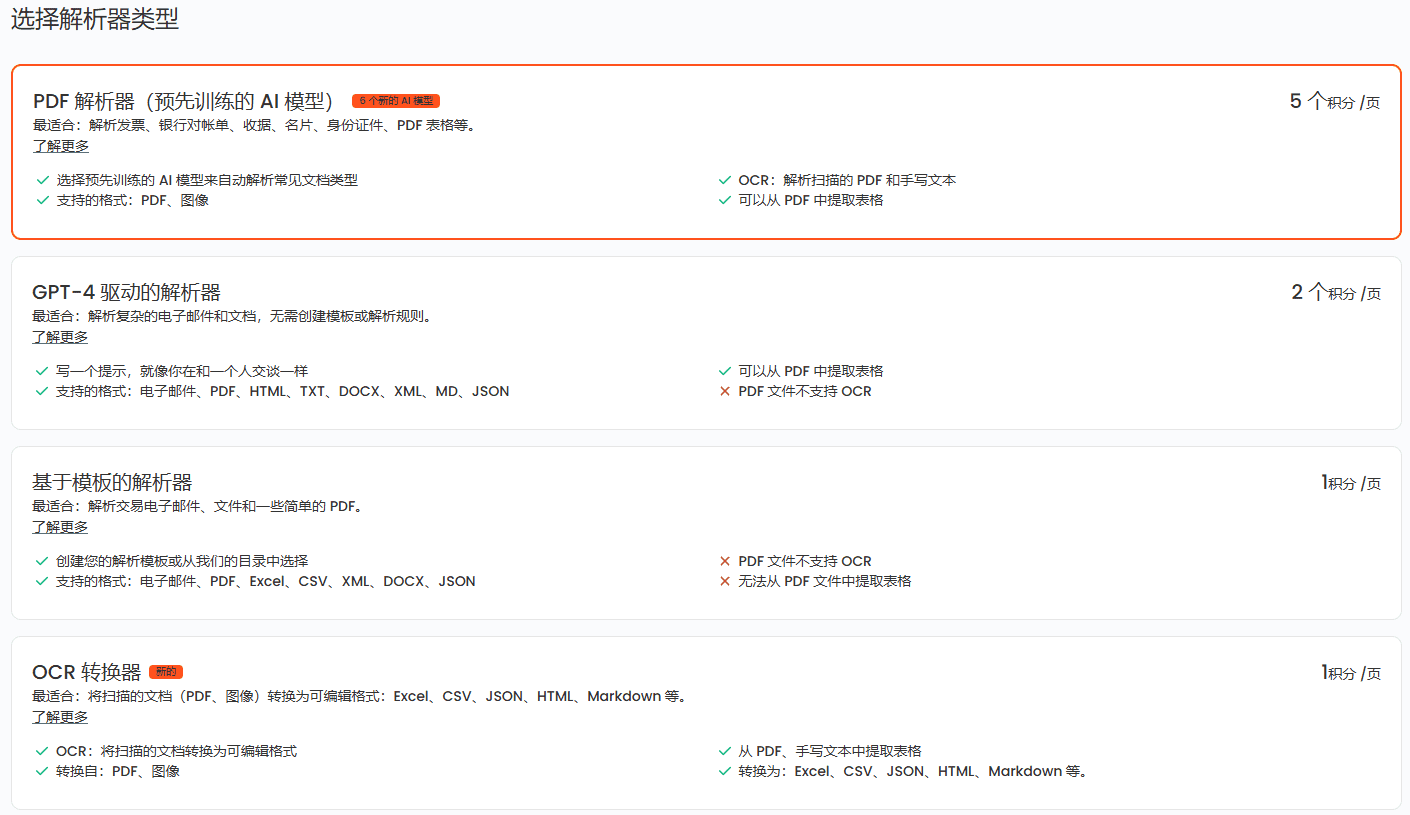
회사 소개 클라우드스퀴드는 2023년 독일 베를린에서 설립된 회사로, 인공지능으로 문서 처리를 간소화하는 데 주력하고 있습니다. 핵심 제품은 온라인 데이터 추출 플랫폼으로, 사용자가 PDF, 이미지, 오디오, 비디오 등의 문서를 업로드하고 추출해야 할 내용을 간단히 입력하기만 하면 됩니다.
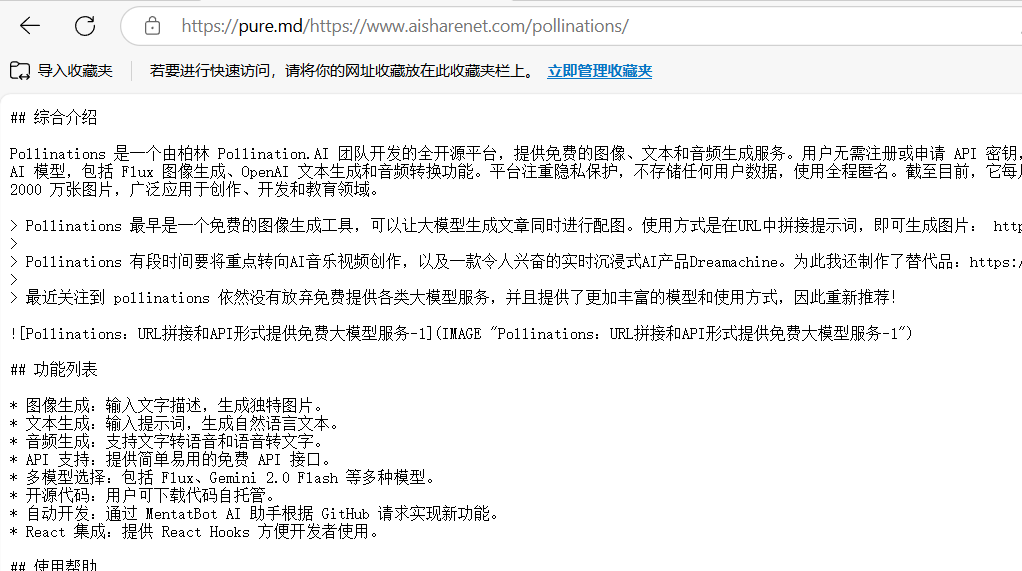
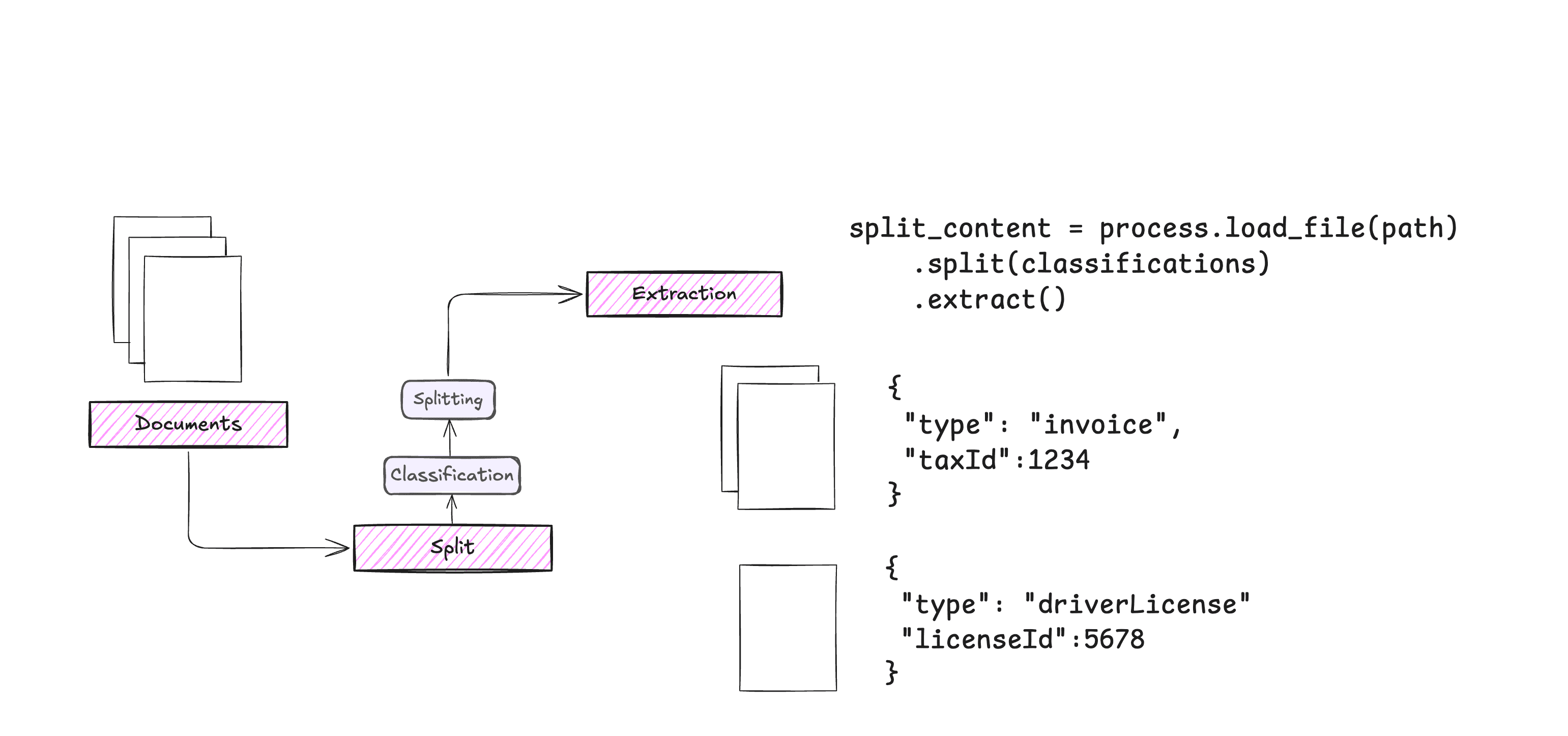
포괄적인 소개 Supametas.AI는 웹 페이지, 문서, 오디오 및 비디오의 혼란을 AI가 사용할 수 있는 구조화된 데이터로 정리하는 데 특화된 데이터 처리 플랫폼입니다. 웹 링크, API, 로컬 파일 등 여러 소스에서 데이터를 수집한 다음 JSON으로 출력하는 것을 지원합니다.
표 인식의 목표는 이미지에서 표를 구문 분석하여 표 구조와 셀 위치를 정확하게 식별하고 이를 구조화된 표 형식(예: HTML)으로 변환하는 것입니다. 오늘날의 정보화 시대에는 여전히 많은 양의 중요한 표 데이터가 비정형화된 상태로 존재합니다(예: 통계표 그림이 있는 스캔 문서...).
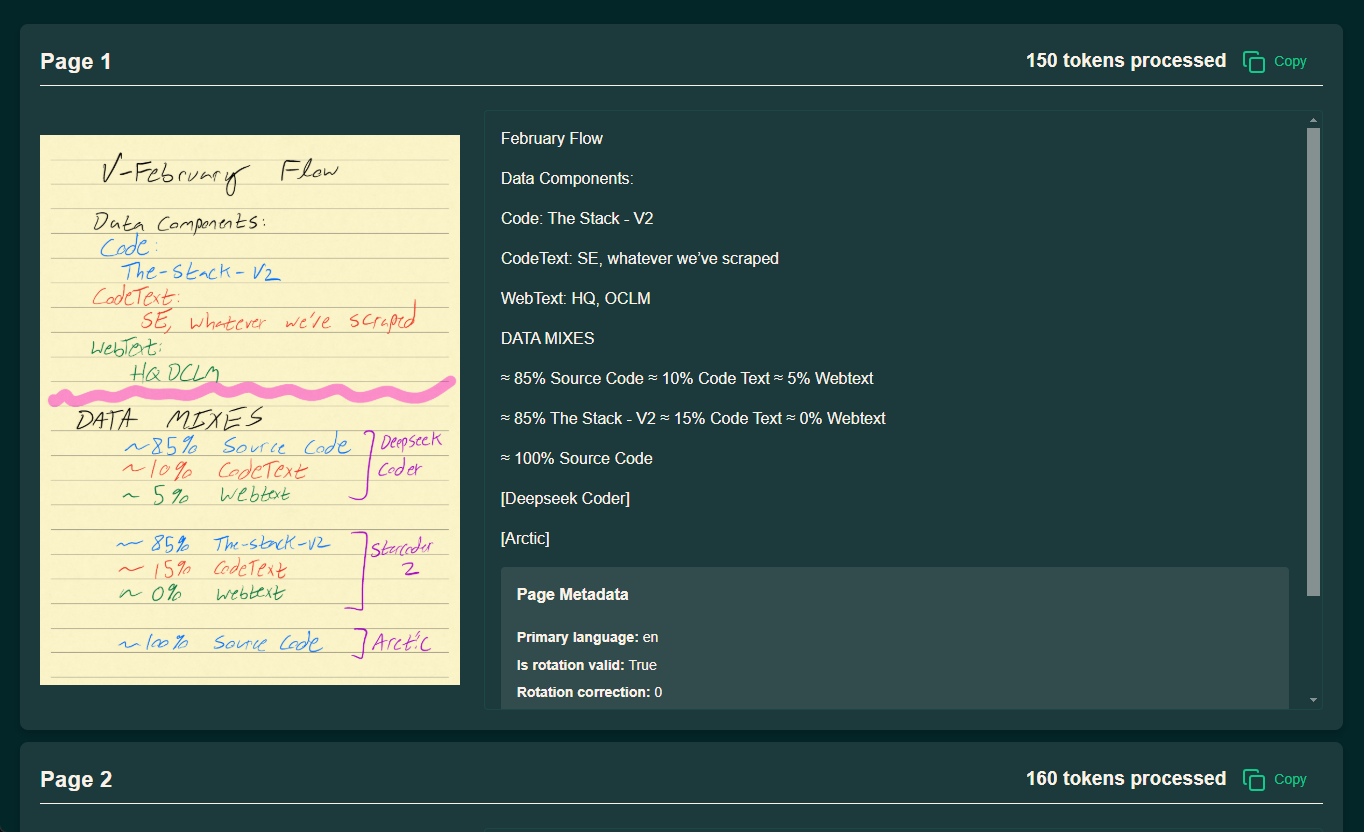
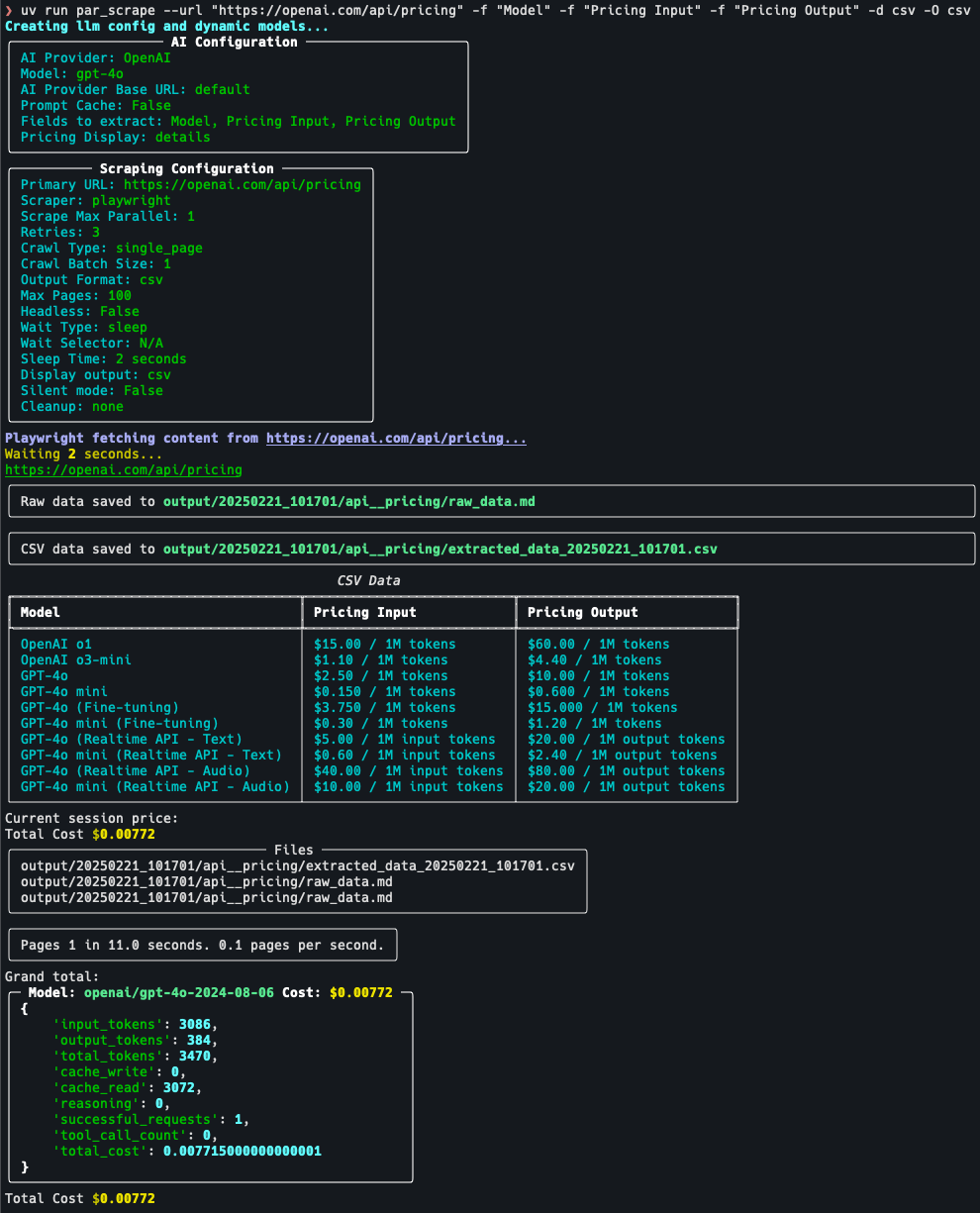
인류 문명의 오랜 역사에서 정보를 획득하고 분석하는 방식의 모든 도약은 사회 발전에 크게 기여해 왔습니다. 고대 상형문자에서 휴대용 파피루스, 이후 인쇄기의 등장, 그리고 오늘날의 디지털 물결에 이르기까지 각 기술 혁신은 인류 지식 보급의 패러다임을 크게 확장했습니다....
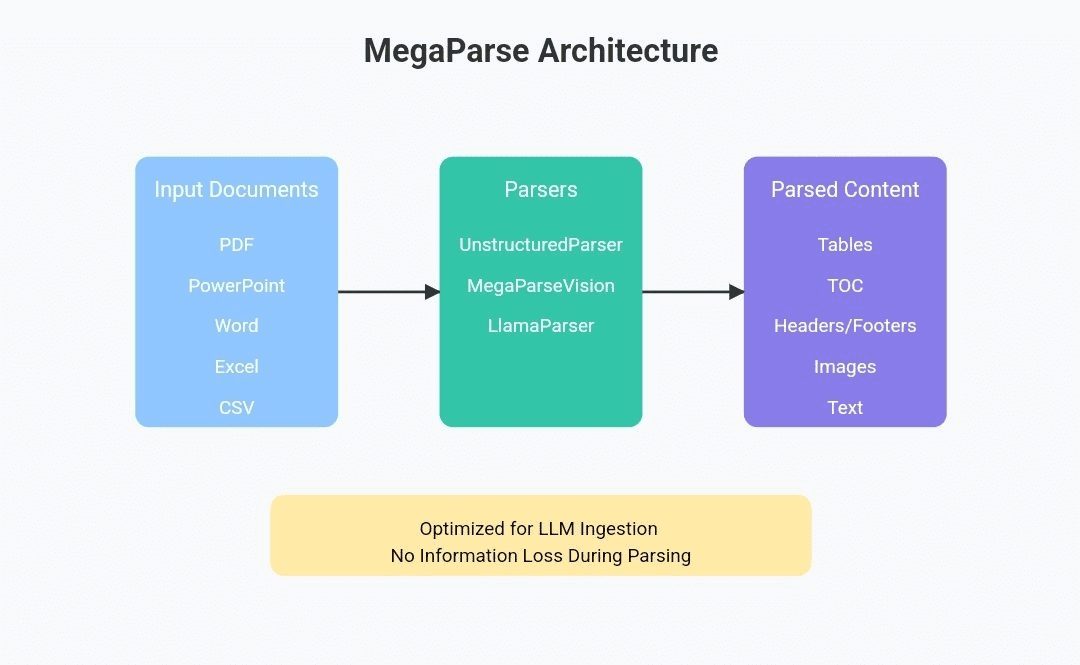
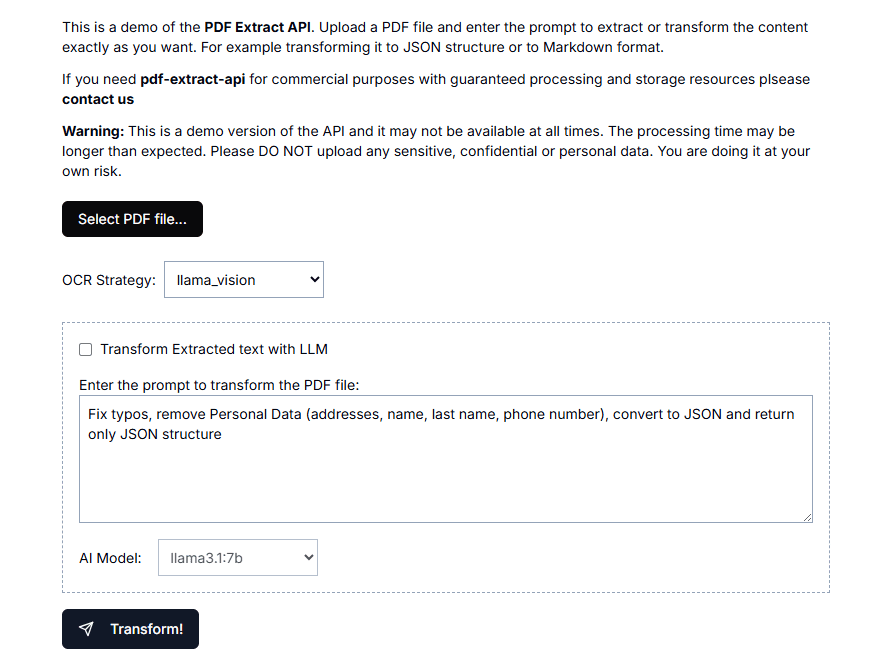
포괄적 인 소개 PDF-Extract-Kit은 복잡하고 다양한 PDF 문서에서 고품질 콘텐츠를 효율적으로 추출하는 데 중점을두고 OpenDataLab 팀에서 개발 한 오픈 소스 프로젝트입니다. 고급 문서 구문 분석 기술을 통합하여 레이아웃 감지, 수식 인식을 지원합니다 ...
종합 소개 Crawl4LLM은 칭화대학교와 카네기멜론대학교가 공동으로 개발한 오픈 소스 프로젝트로, 대규모 모델(LLM)의 사전 학습을 위한 웹 크롤링의 효율성을 최적화하는 데 중점을 두고 있습니다. 고품질 웹 데이터를 지능적으로 선별하여 비효율적인 크롤링을 크게 줄이며, 원래 크롤링해야 하는 1...
종합 소개 zChunk는 제로엔트로피에서 개발한 새로운 청킹 전략으로, 일반적인 의미론적 청킹을 위한 솔루션을 제공하는 것을 목표로 합니다. 이 전략은 청크 생성을 유도하여 문서의 청크 프로세스를 최적화하고 정보 검색을 높은 수준으로 유지하도록 보장하는 Llama-70B 모델을 기반으로 합니다.
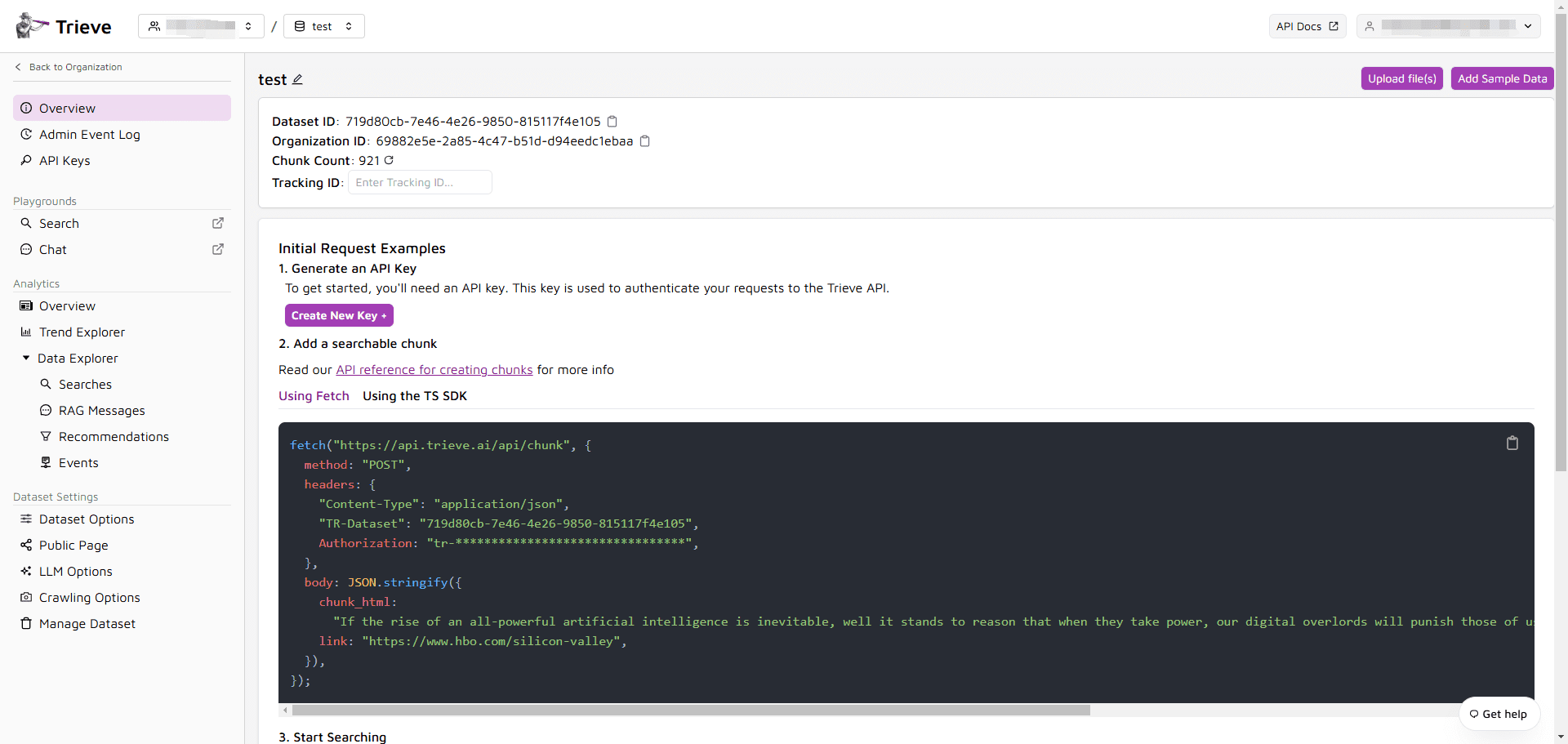
개요 Pulse는 문서 처리 및 데이터 추출에 중점을 둔 지능형 플랫폼으로, 기업과 개발자가 다양하고 복잡한 문서를 효율적으로 파싱하고 처리할 수 있도록 설계되었습니다. 고급 컴퓨터 비전과 멀티모달 처리 기술을 통해 Pulse는 텍스트, 이미지, 표 등에서 데이터를 정확하게 추출할 수 있습니다.
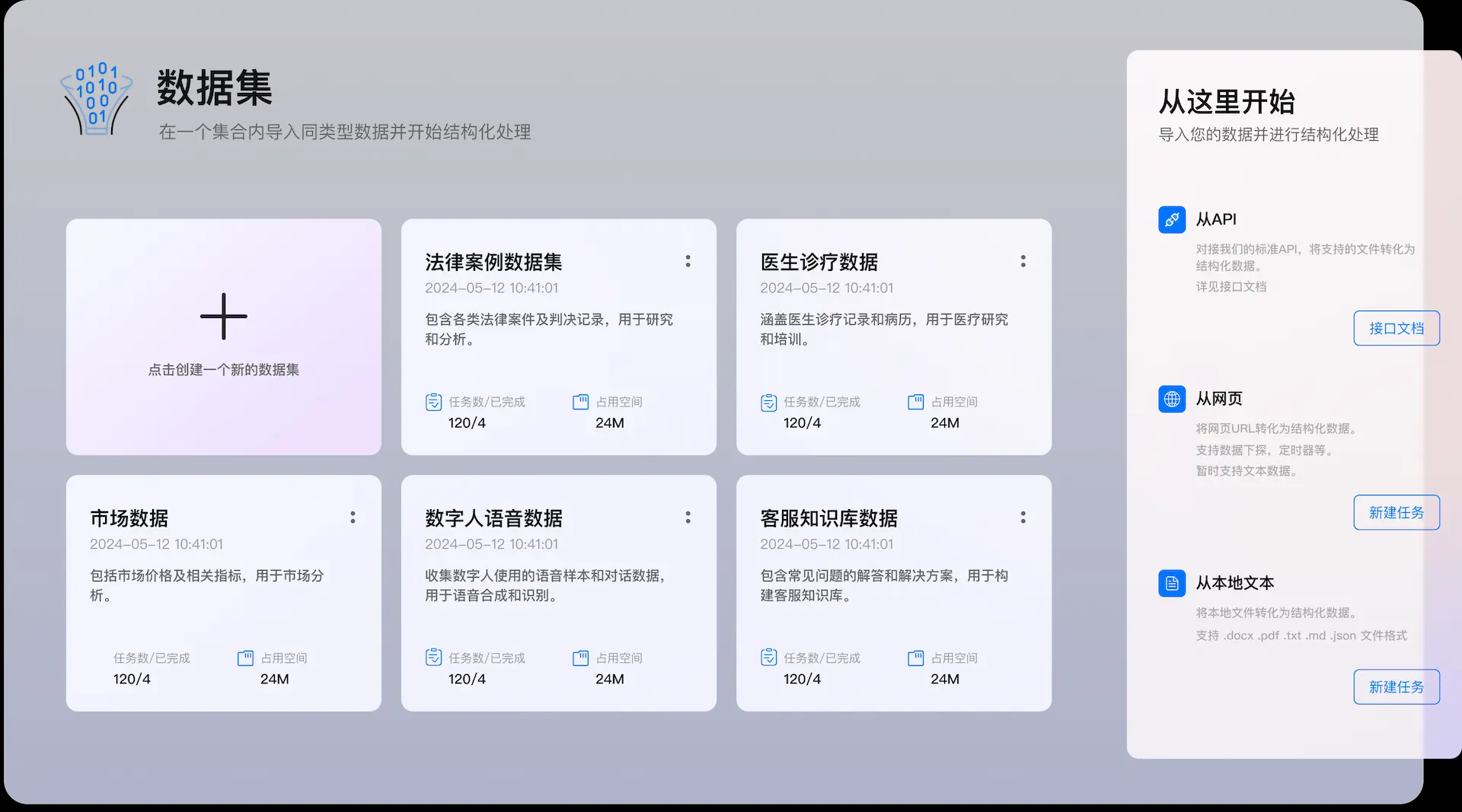
종합 소개 UnDatas.IO는 비정형 데이터 구문 분석 및 처리에 중점을 둔 플랫폼입니다. 고급 기술을 활용하여 문서 레이아웃을 자동으로 인식하고 표, 이미지, 수식, 텍스트를 분류하여 데이터 처리 프로세스를 크게 간소화합니다. 이 플랫폼은 데이터 정렬에 많은 시간을 절약해줄 뿐만 아니라...
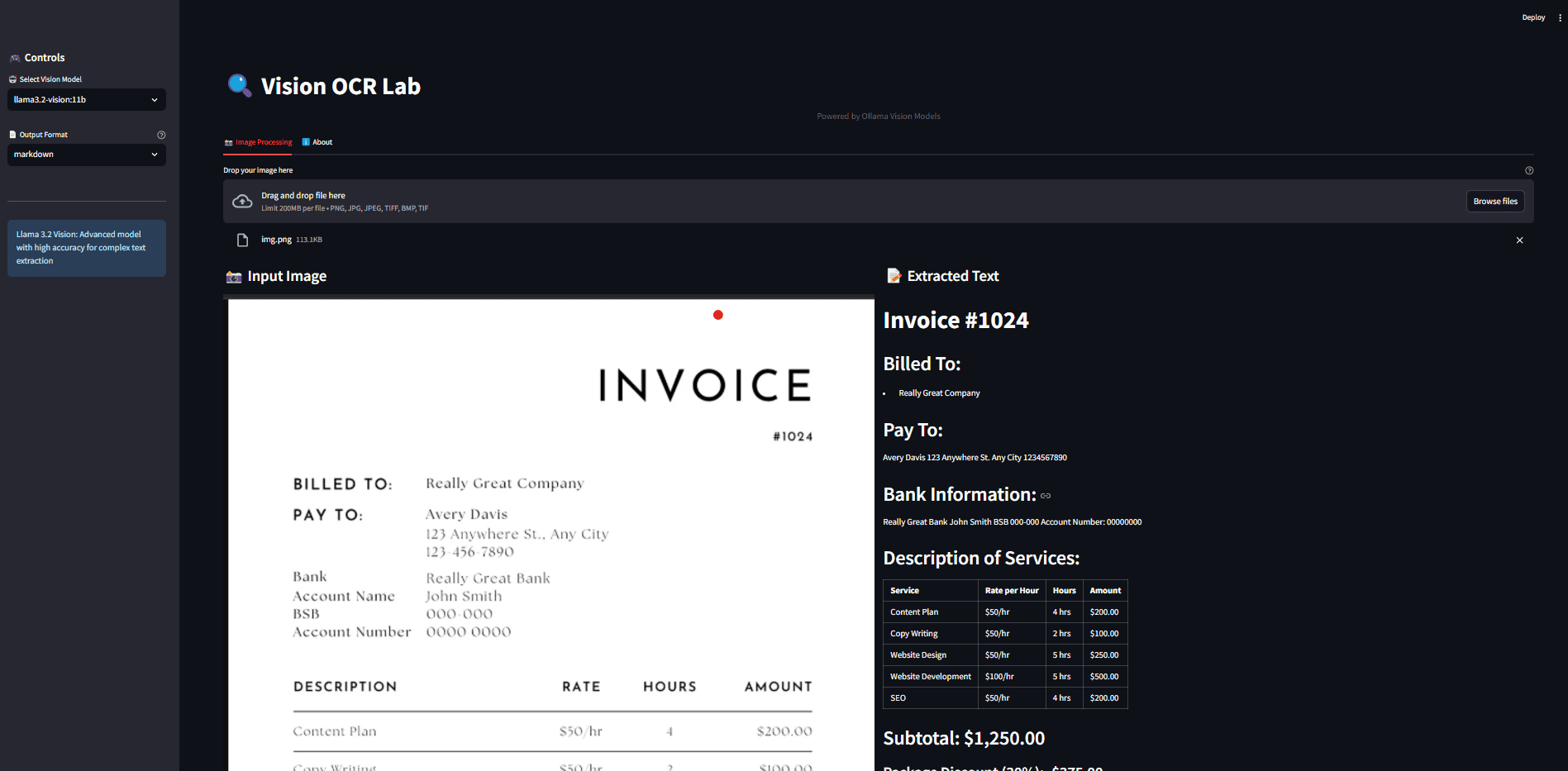
일반 소개 Zerox는 시각적 모델을 통해 PDF, DOCX, 이미지 및 기타 문서를 마크다운 형식으로 변환하도록 설계된 오픈 소스 프로젝트입니다. 이 프로젝트는 getomni-ai 팀에 의해 개발되었으며 간단하고 효율적인 OCR(광학 문자 인식) 솔루션을 제공합니다.Ze ...
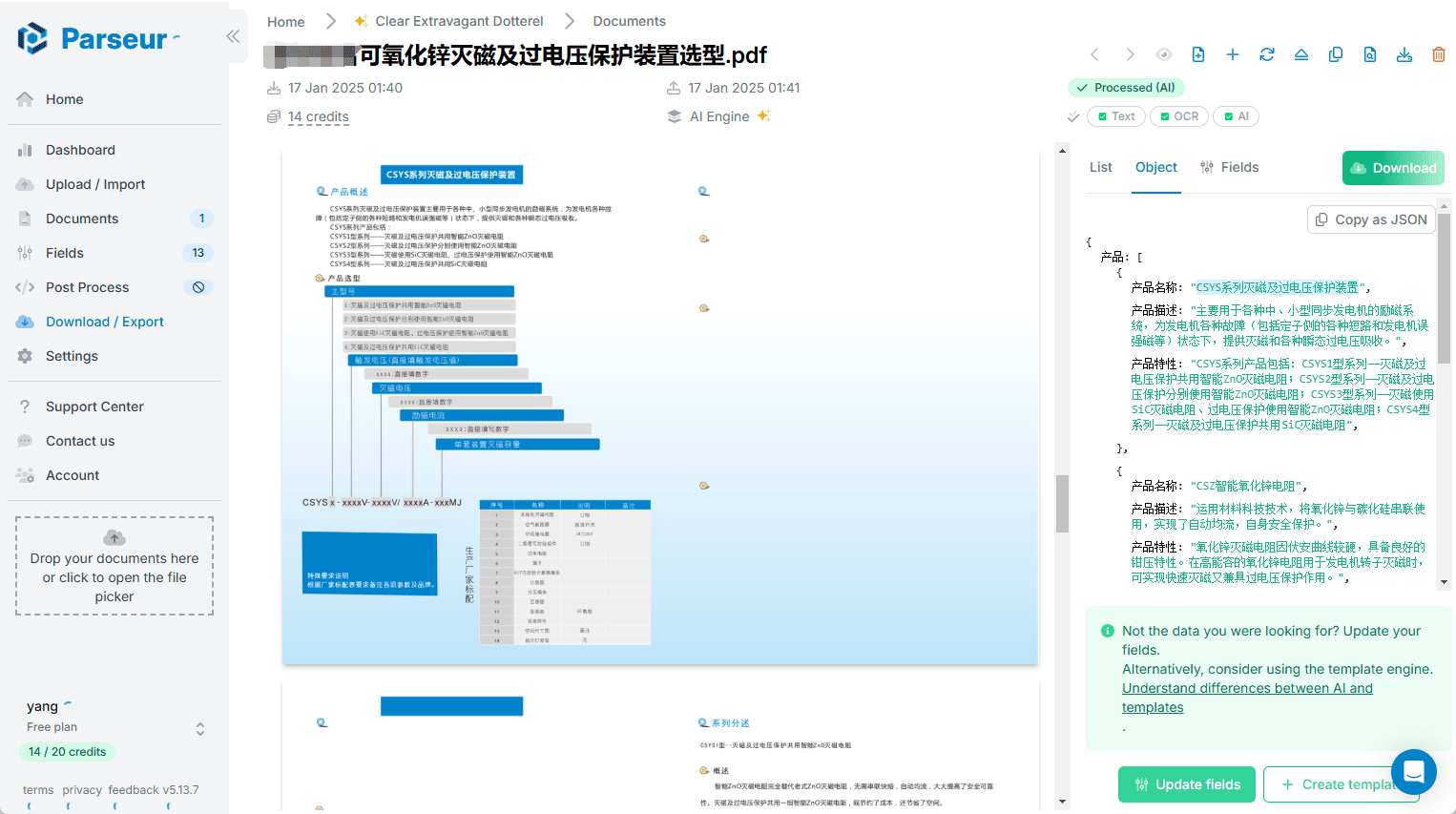
일반 설명 Parseur는 사용자가 PDF, 이메일 및 기타 문서에서 텍스트 데이터를 자동으로 추출할 수 있도록 설계된 선도적인 AI 데이터 추출 소프트웨어입니다. Parseur를 사용하면 비정형 데이터를 정형 데이터로 쉽게 변환하여 다양한 애플리케이션으로 전송할 수 있습니다.
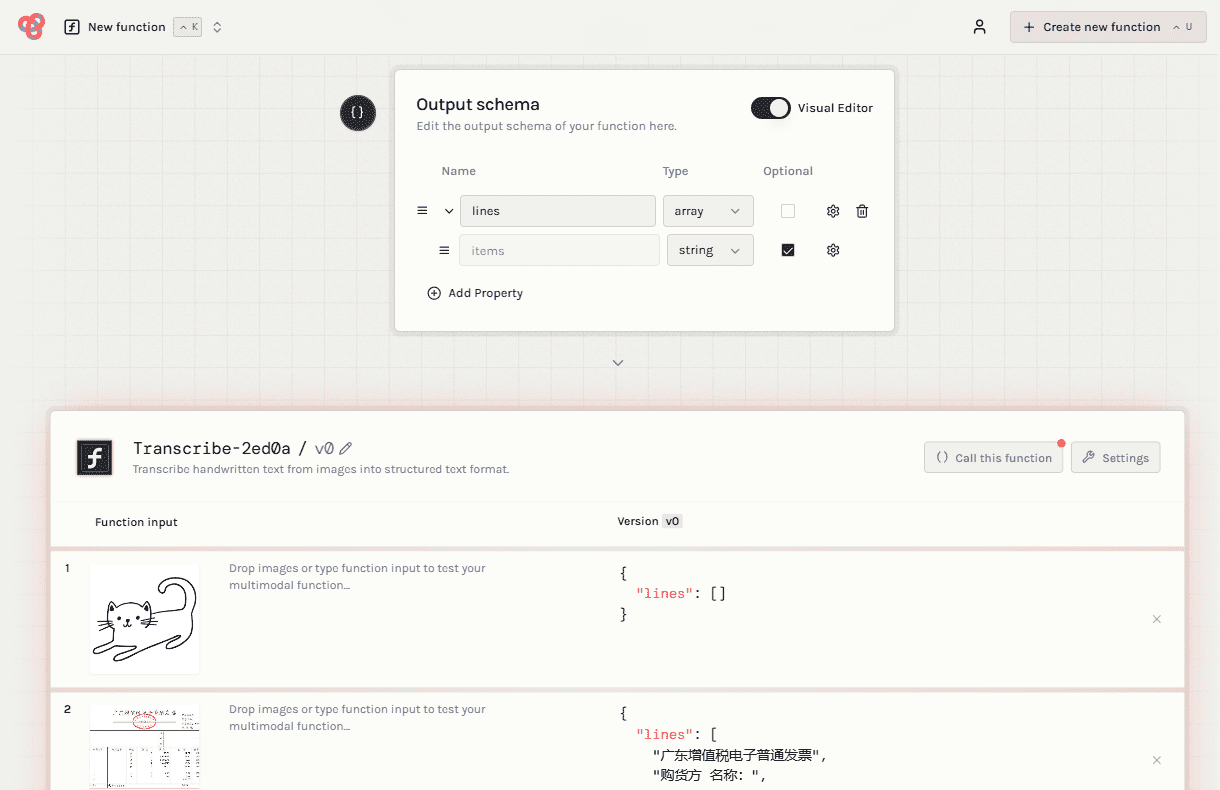
종합 소개 Weco AI Functions는 사용자가 AI 함수를 빠르게 빌드하고 배포할 수 있도록 설계된 강력한 플랫폼입니다. 사용자는 작업을 간단히 설명하기만 하면 A/B 테스트와 관찰 모니터링을 통해 구조화된 출력 패턴을 생성할 수 있습니다. 이 플랫폼은 노코드 프로토타이핑을 지원합니다...
포괄적인 소개 NV Ingest(NVIDIA Ingest)는 수십만 개의 복잡하고 지저분한 비정형 PDF 및 기타 엔터프라이즈 문서를 구문 분석하도록 설계된 조기 액세스 마이크로서비스 제품군입니다. 이러한 문서를 메타데이터 및 텍스트로 변환하여 검색에 포함할 수 있습니다.
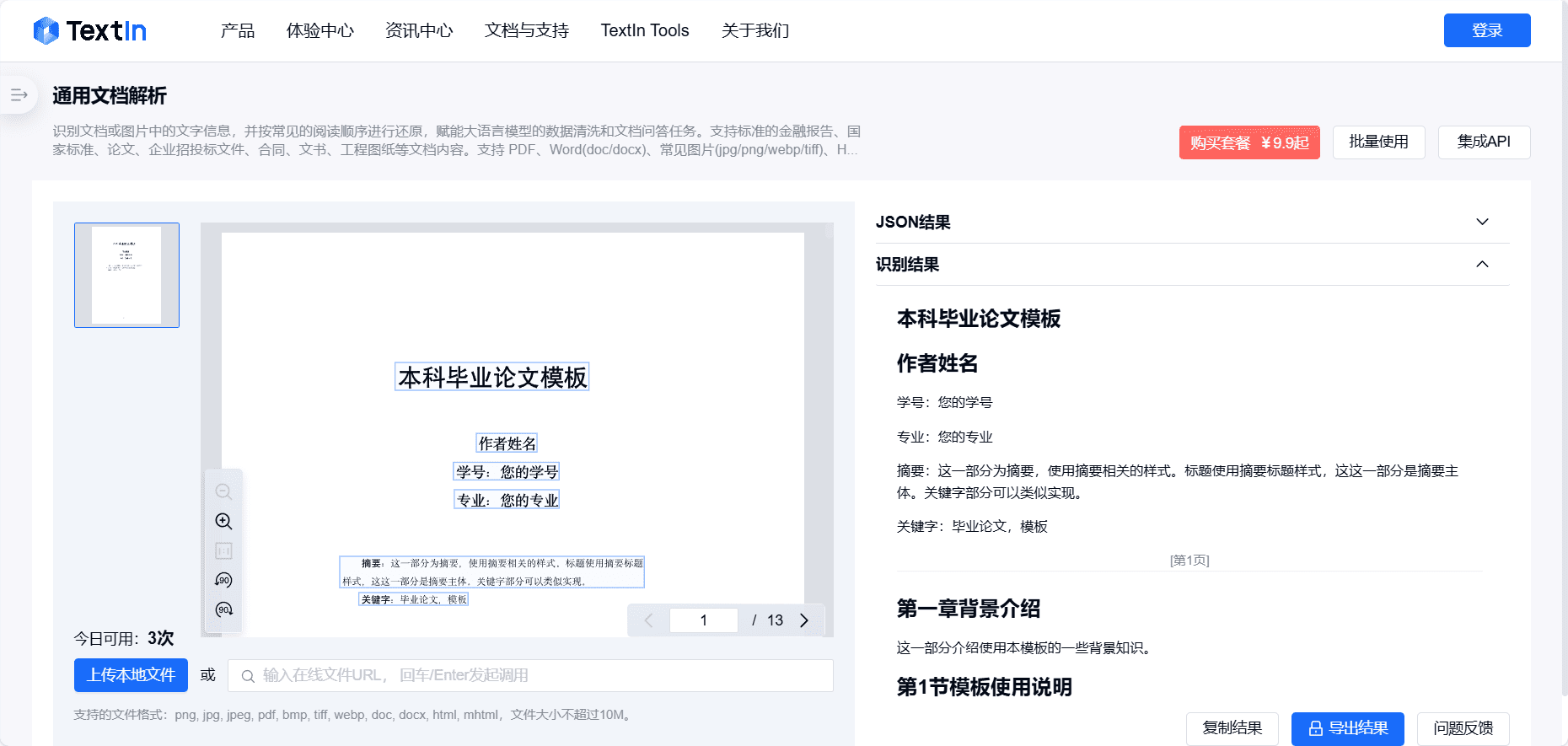
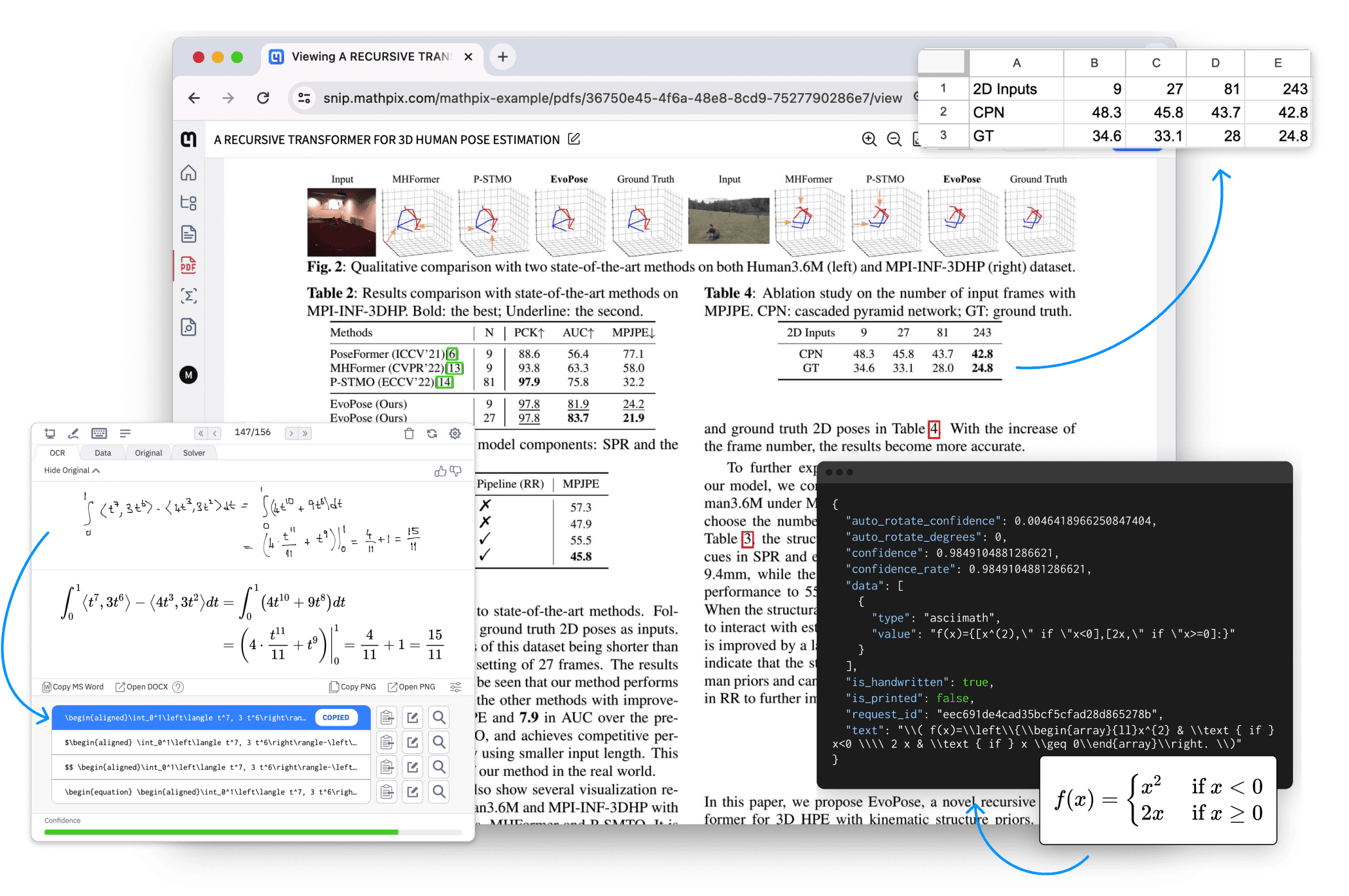
종합 소개 Doc2X는 강력한 문서 이미지 수식 인식 및 변환 도구로, 효율적이고 지능적인 문서 처리 솔루션을 제공하기 위해 최선을 다하고 있습니다. 학술 연구 논문, 교과서, 기업 문서, 재무 보고서 등 어떤 문서든 Doc2X는 PDF 표를 정확하게 식별할 수 있으며...
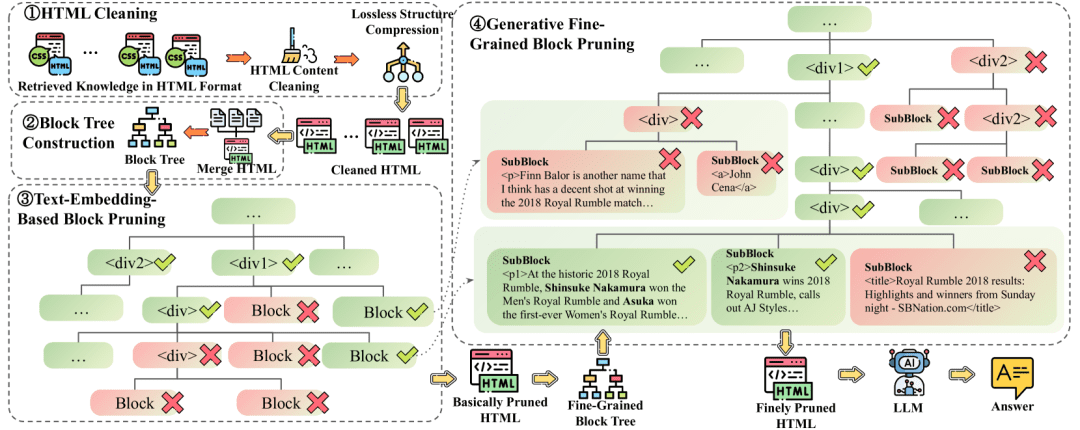
종합 소개 HtmlRAG는 검색 증강 생성(RAG) 시스템에서 HTML 문서 처리를 개선하는 데 초점을 맞춘 혁신적인 오픈 소스 프로젝트입니다. 이 프로젝트는 RAG 시스템에서 HTML 서식을 사용하는 것이 일반 텍스트보다 더 효율적이라고 주장하는 새로운 접근 방식을 제시합니다. 이 프로젝트에는 완전한 ...
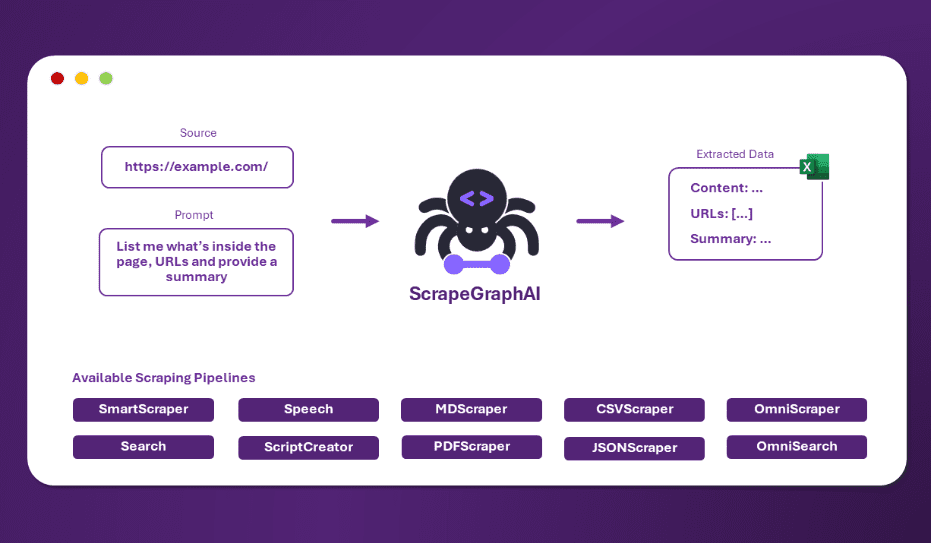
포괄적인 소개 ScrapeGraphAI는 대규모 언어 모델링(LLM)과 직접 그래프 로직을 영리하게 결합하여 웹사이트와 로컬 문서를 위한 스크래핑 파이프라인을 생성하는 혁신적인 Python 웹 스크래핑 라이브러리입니다. 이 도구를 독특하게 만드는 것은 완벽한 수준의 단순성과 강력함입니다...
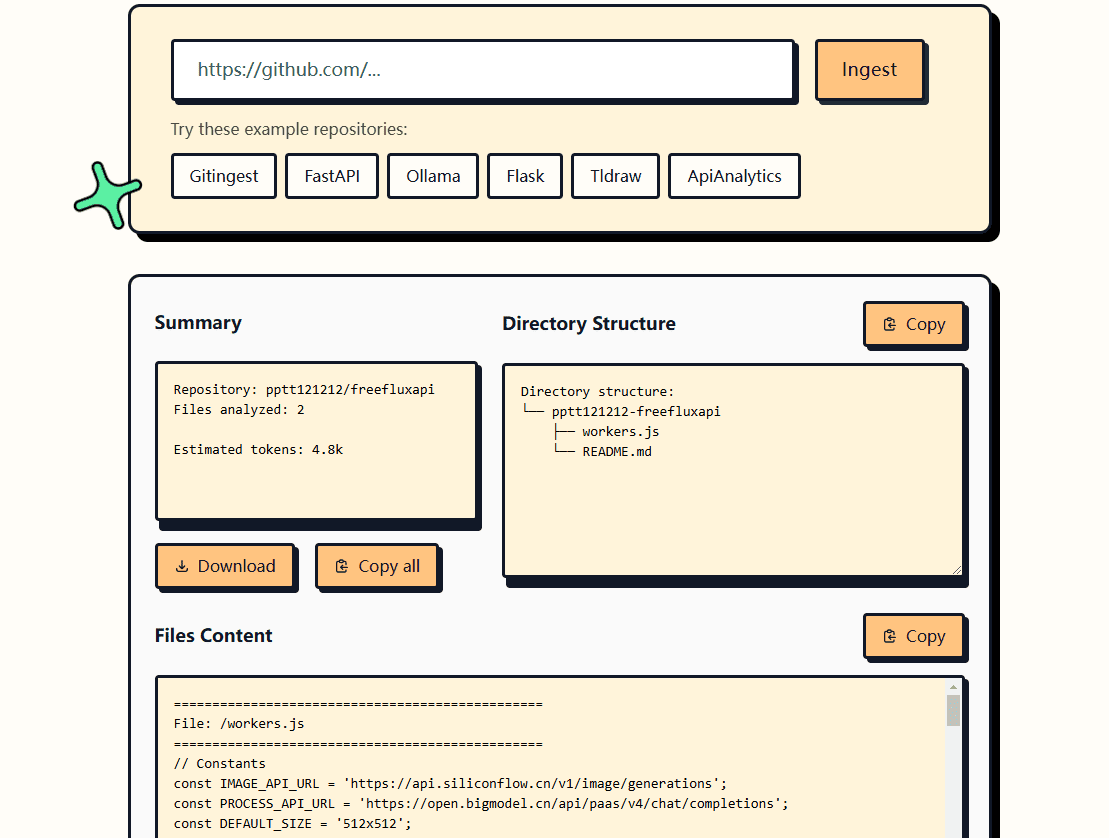
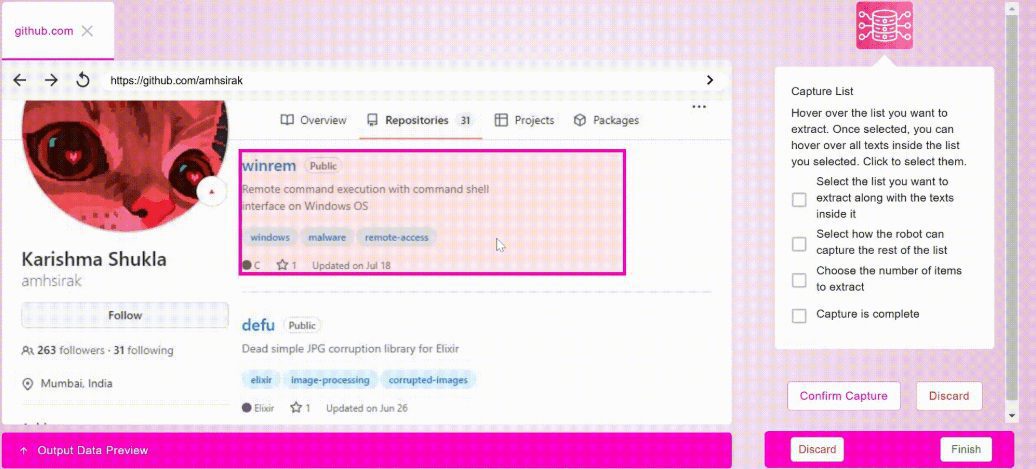
종합 소개 Maxun은 오픈 소스 노코드 웹 데이터 추출 플랫폼으로, 사용자가 몇 분 안에 로봇을 훈련시켜 웹 데이터를 자동으로 크롤링하고 이를 API 또는 스프레드시트로 변환할 수 있습니다. 이 플랫폼은 페이징과 스크롤을 지원하고, 웹사이트 레이아웃 변경에 적응하며, 강력한 데이터 크롤링 기능을 제공합니다.
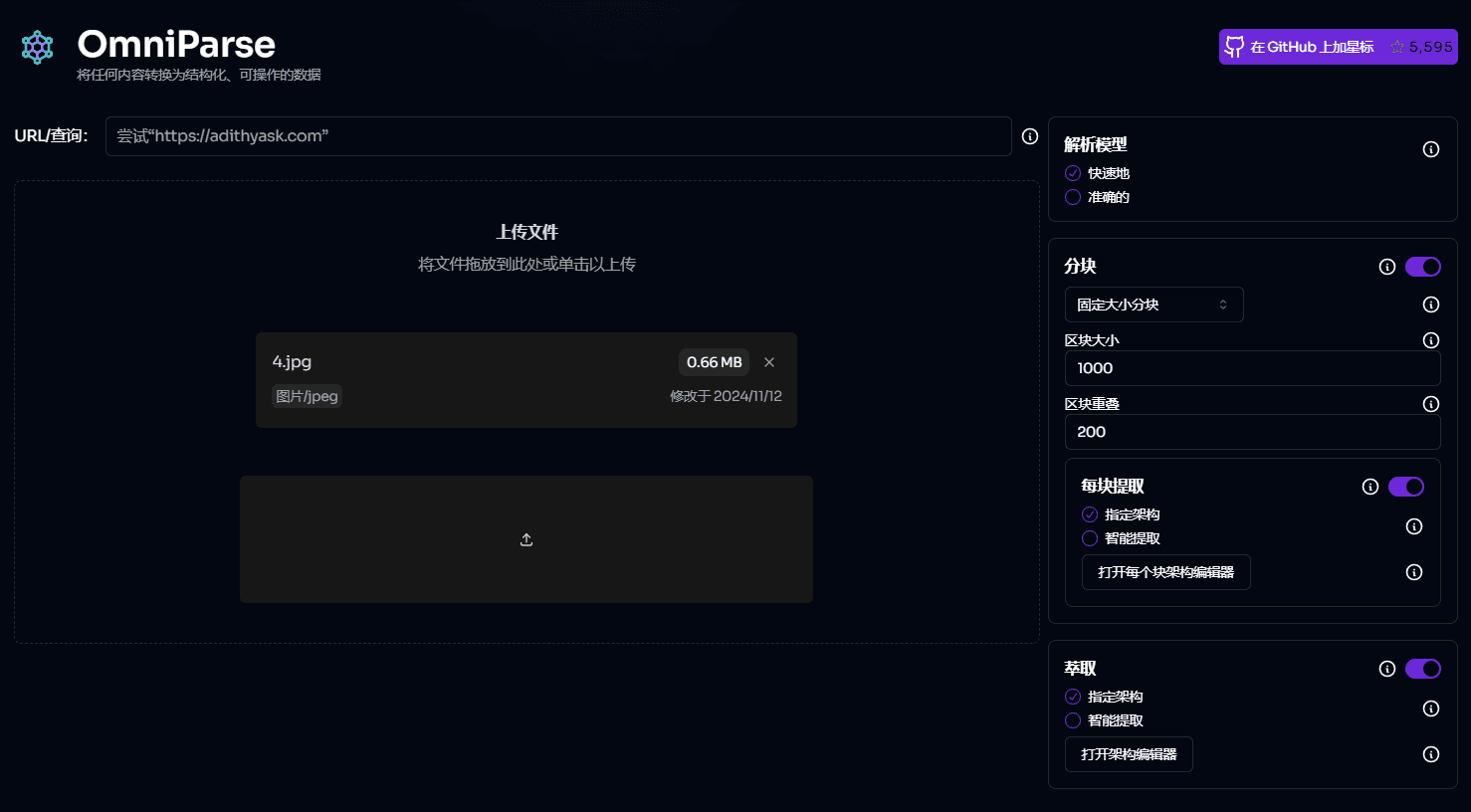
일반 소개 OmniParse는 모든 비정형 데이터를 GenAI(생성 인공 지능) 프레임워크에 최적화된 정형화된 실행 가능한 데이터로 변환하도록 설계된 강력한 데이터 구문 분석 및 최적화 플랫폼입니다. 문서, 표, 이미지, 동영상, 오디오 파일 등 어떤 종류의 데이터를 작업하든 상관없습니다.
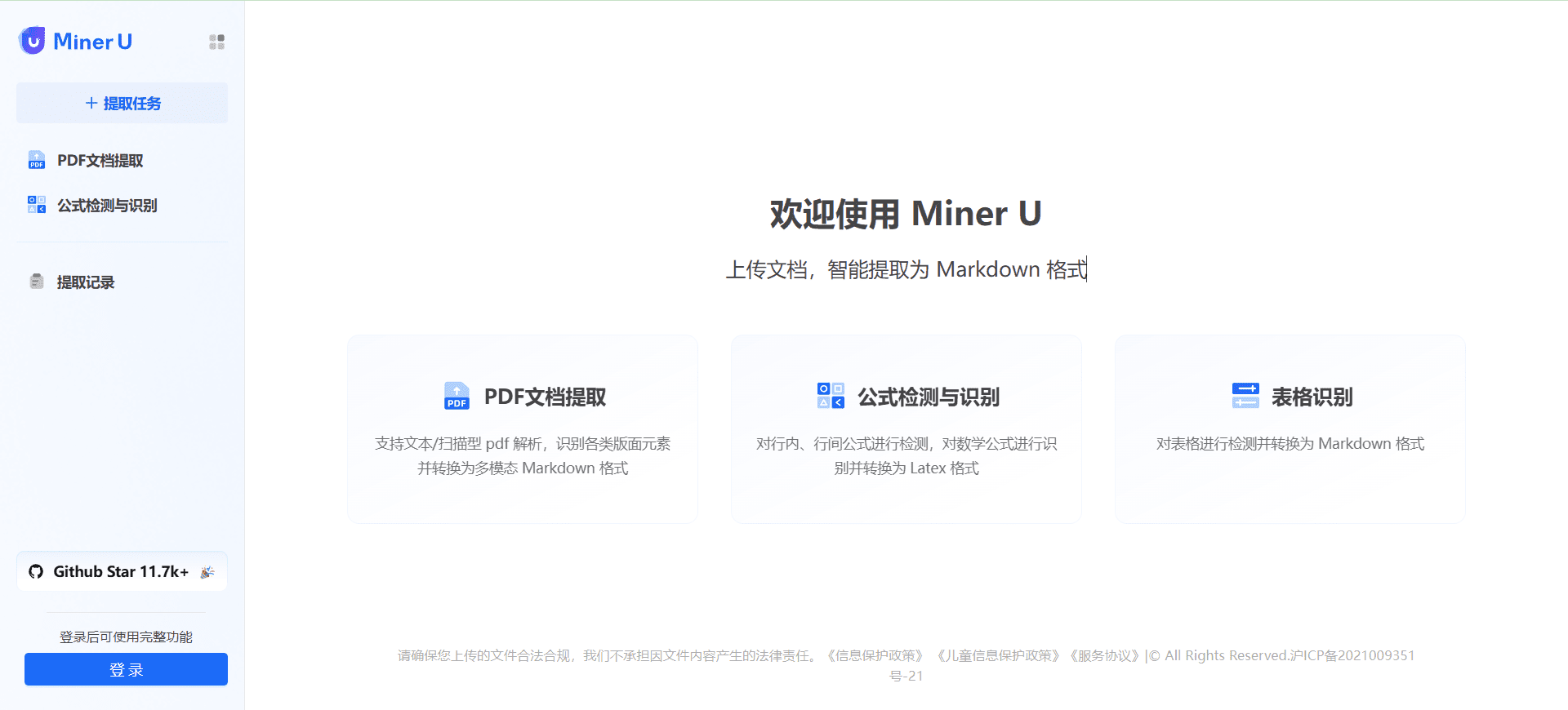
개요 MinerU는 상하이 인공 지능 연구소의 OpenDataLab 팀이 개발한 오픈 소스 데이터 추출 도구로, 복잡한 PDF 문서, 웹 페이지 및 전자책에서 콘텐츠를 효율적으로 추출하는 데 중점을 두고 있습니다. 이미지, 수식, 표 및 기타 요소가 포함된 멀티모달 PDF를 추출할 수 있습니다.
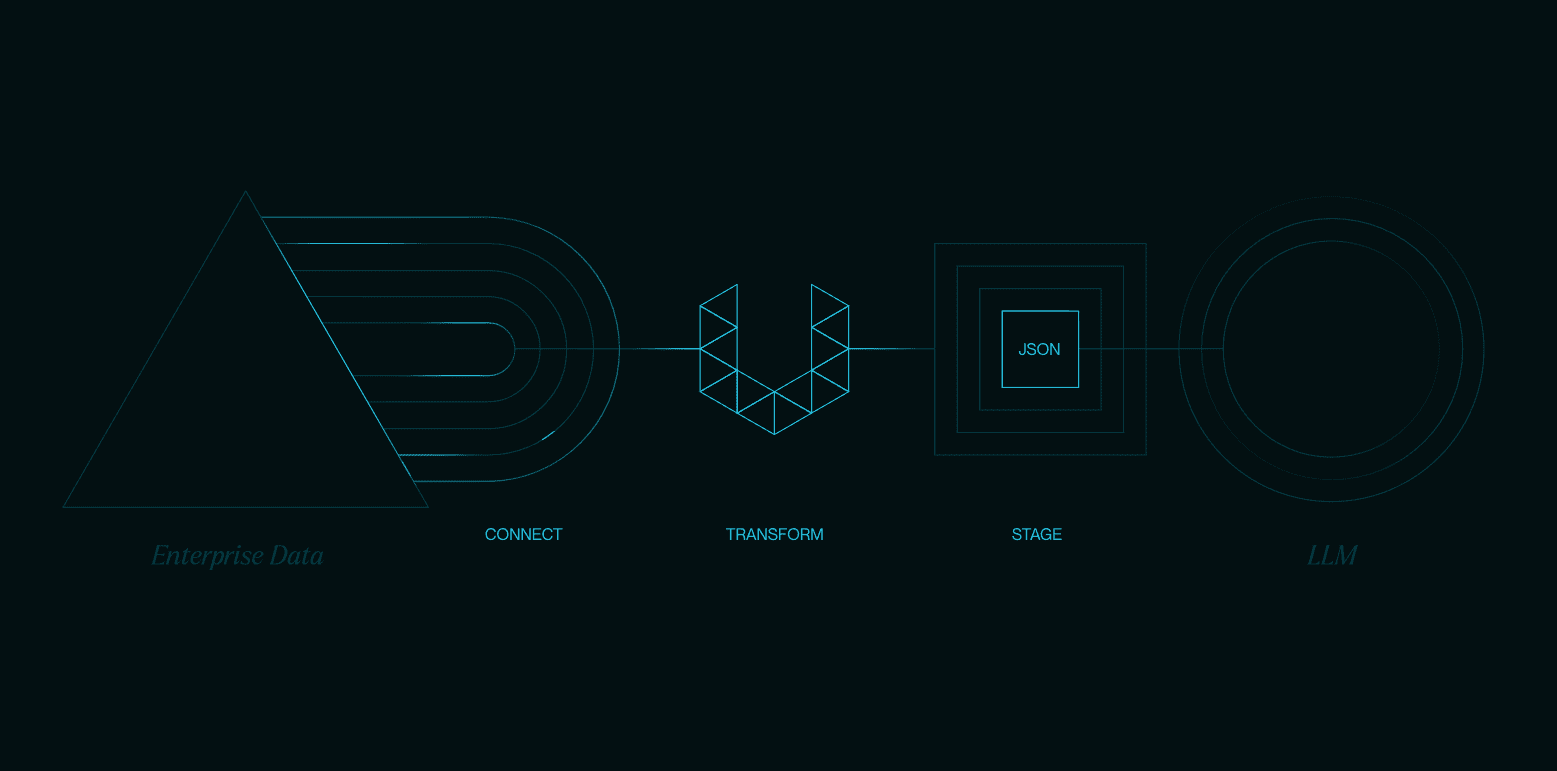
포괄적인 소개 Unstructured-IO는 PDF, HTML, Word 문서 등과 같은 이미지 및 텍스트 문서를 처리하고 전처리하기 위한 오픈 소스 구성 요소 세트를 제공합니다. 주요 목표는 데이터 처리 워크플로우를 단순화하고 최적화하는 것으로, 특히 대규모 언어 모델(LL...