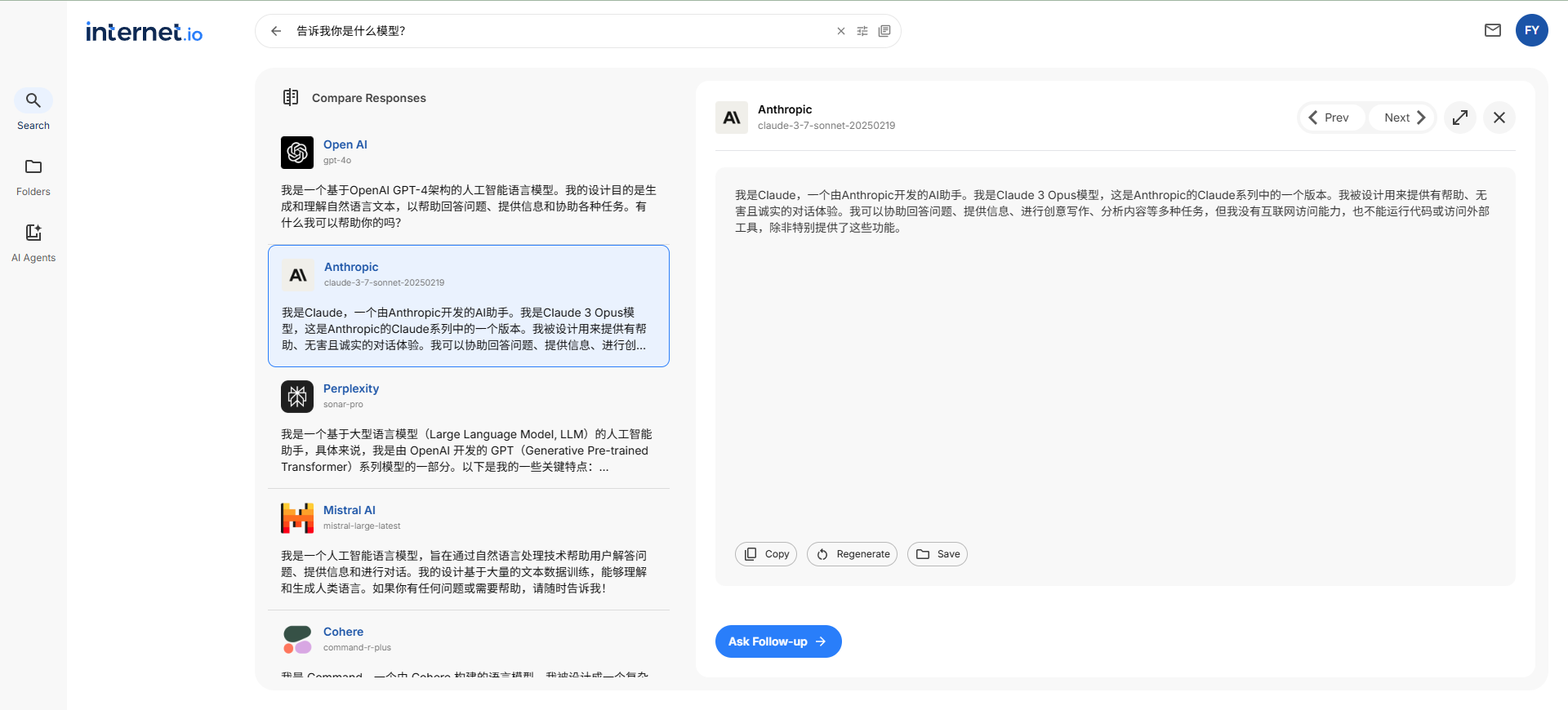

일반 소개
새드토커 비디오 립싱크는 새드토커 구현에 기반한 비디오 립합성 툴입니다. 이 프로젝트는 음성 기반 생성을 통해 입술 모양을 생성하고 구성 가능한 얼굴 영역 향상을 사용하여 생성된 입술 모양의 선명도를 향상시킵니다. 또한 이 프로젝트는 DAIN 프레임 보간 알고리즘을 사용하여 생성된 비디오의 프레임을 채워 입술 전환을 더욱 부드럽고 사실적이며 자연스럽게 만듭니다. 사용자는 간단한 명령줄 조작을 통해 고품질의 입술 모양 동영상을 빠르게 생성할 수 있어 다양한 동영상 제작 및 편집 요구에 적합합니다.

새드토커 원본

새드토커 기능 향상
기능 목록
- 음성 기반 립 생성오디오 파일을 통해 동영상에서 입술 움직임을 구동합니다.
- 얼굴 부위 향상입술 또는 얼굴 전체 영역의 화질을 개선하여 동영상 선명도를 향상할 수 있습니다.
- DAIN 프레임 삽입딥러닝 알고리즘을 사용하여 동영상의 프레임을 패치하여 동영상 부드러움을 개선합니다.
- 다양한 향상 옵션보정 없음, 입술 보정, 얼굴 전체 보정 등 세 가지 모드를 지원합니다.
- 사전 교육 모델사용자가 빠르게 시작할 수 있도록 사전 학습된 다양한 모델을 제공합니다.
- 간단한 명령줄 조작명령줄 매개변수를 통해 쉽게 구성하고 실행할 수 있습니다.
도움말 사용
환경 준비
- 필요한 종속성을 설치합니다:
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
conda install ffmpeg
pip install -r requirements.txt
- 프레임 채우기에 DAIN 모델을 사용해야 하는 경우 패들 또한 설치해야 합니다:
python -m pip install paddlepaddle-gpu==2.3.2.post112 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
프로젝트 구조
checkpoints사전 학습된 모델 저장dian_outputDAIN 프레임 삽입 출력 저장examples샘플 오디오 및 비디오 파일results결과 생성src: 소스 코드sync_show합성 효과 데모third_part: 타사 라이브러리inference.py: 추론 스크립트README.md프로젝트 설명 문서
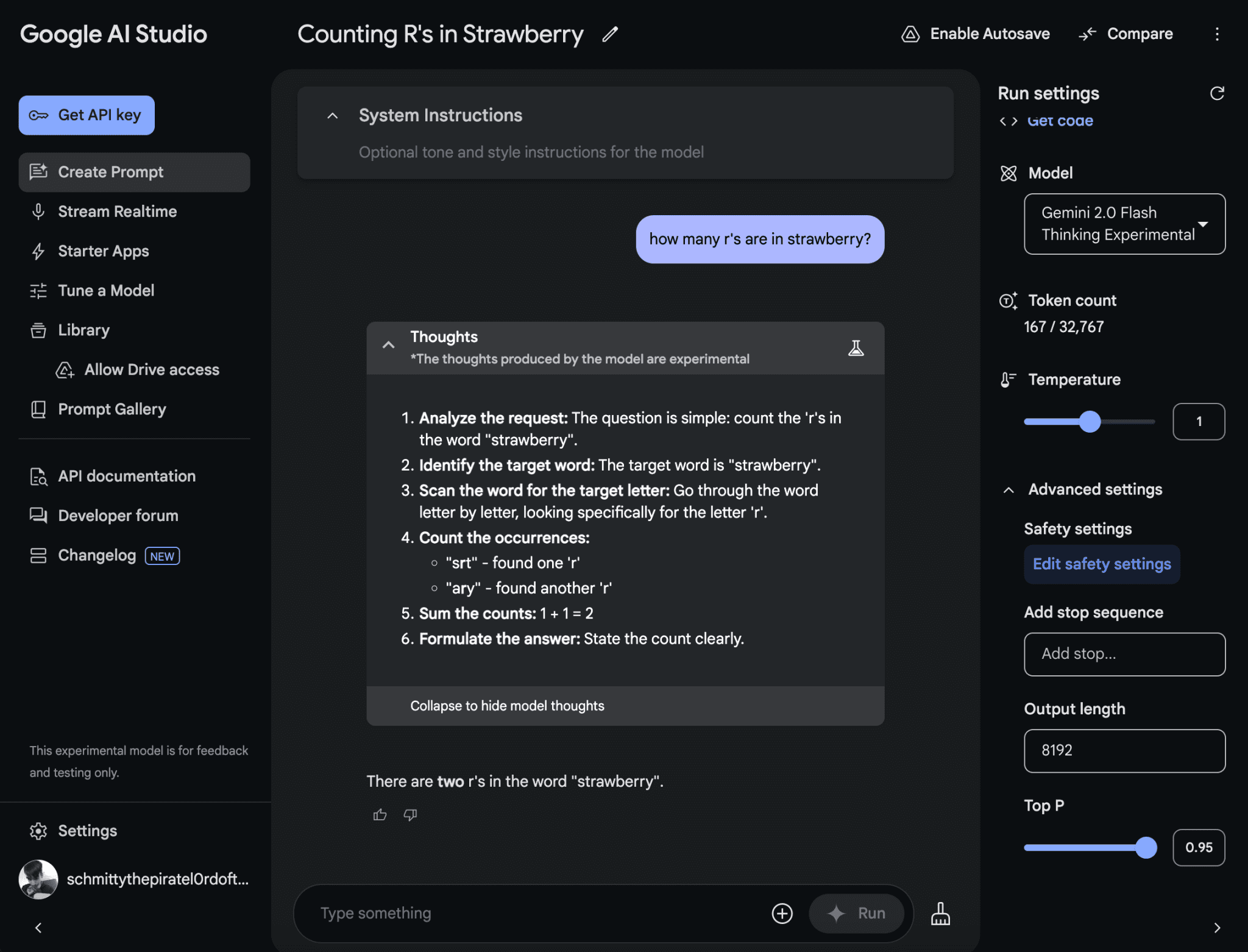
모델링된 추론
모델 추론에는 다음 명령을 사용합니다:
python inference.py --driven_audio <audio.wav> --source_video <video.mp4> --enhancer <none, lip, face> --use_DAIN --time_step 0.5
--driven_audio오디오 파일 입력--source_video비디오 파일 입력--enhancer: 향상된 모드(없음, 입술, 얼굴)--use_DAIN: DAIN 프레임 사용 여부--time_step보간 프레임 속도(기본값 0.5, 즉 25fps -> 50fps)
합성 효과
생성된 동영상 효과는 ./sync_show 카탈로그:
original.mp4: 원본 동영상sync_none.mp4: 인핸스먼트 없는 합성 효과none_dain_50fps.mp4DAIN 모델만 사용하여 25fps에서 50fps 추가하기lip_dain_50fps.mp4입술 영역 개선 + DAIN 모델 개선으로 25fps에서 50fps 추가face_dain_50fps.mp4전체 얼굴 영역 + DAIN 모델을 개선하여 25fps에서 50fps 추가
사전 교육 모델
사전 학습된 모델 다운로드 경로:
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...