
일반 소개
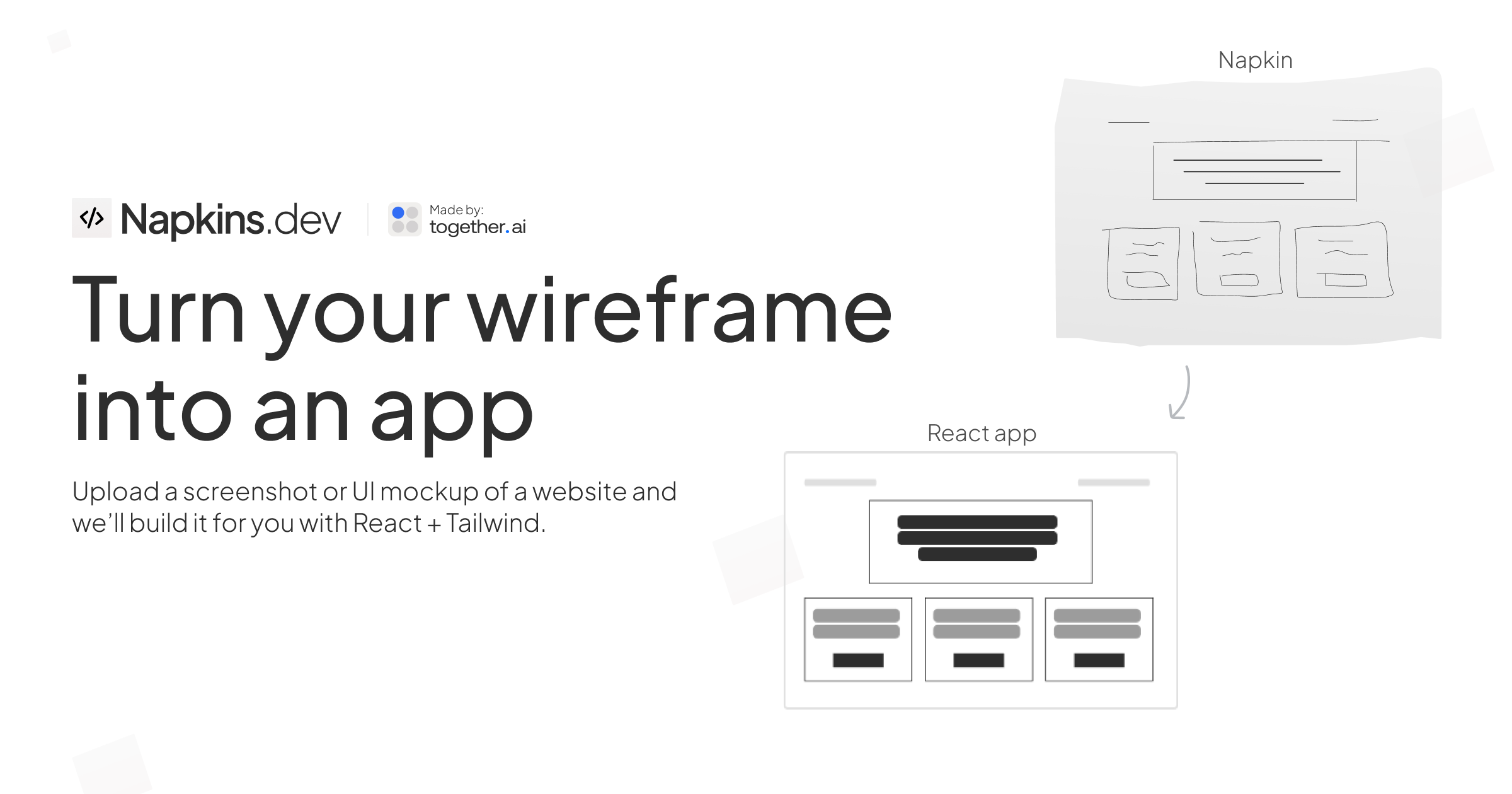
StreamingT2V는 텍스트 설명을 기반으로 일관성 있고 동적이며 확장 가능한 긴 동영상을 생성하는 데 중점을 두고 픽사트 AI 연구팀에서 개발한 공개 프로젝트입니다. 이 기술은 고급 자동 회귀 접근 방식을 사용하여 설명 텍스트와 거의 일치하는 시간적으로 일관된 비디오를 보장하고 높은 프레임 품질의 이미지를 유지합니다. 최대 1200fps, 최대 2분 길이의 동영상을 생성할 수 있으며, 더 긴 시간으로 확장할 수 있는 잠재력을 가지고 있습니다. 이 기술의 효과는 특정 Text2Video 모델에 의해 제한되지 않습니다. 즉, 모델을 개선하면 동영상 품질이 더욱 향상됩니다.

기능 목록
최대 1200fps, 최대 2분 길이의 동영상 생성을 지원합니다.
비디오 및 고프레임 품질의 이미지의 시간적 일관성 유지
텍스트 설명과 밀접하게 일치하는 동적 동영상 생성
여러 기본 모델 애플리케이션을 지원하여 생성된 비디오의 품질을 향상시킵니다.
텍스트-비디오 및 이미지-비디오 변환 지원
Gradio 온라인 데모 제공
도움말 사용
프로젝트 리포지토리를 복제하고 필요한 환경을 설치합니다.
무게추를 다운로드하여 올바른 카탈로그에 배치하세요.
텍스트-비디오 또는 이미지-비디오 변환을 위한 샘플 코드를 실행합니다.
자세한 결과 및 데모는 프로젝트 페이지에서 확인하세요.
추론 시간
기본 모델로서의 모델스코프T2V
| 프레임 속도 | 더 빨라진 미리보기 추론 시간(256×256) | 최종 결과에 대한 추론 시간(720×720) |
|---|---|---|
| 24프레임 | 40초. | 165초. |
| 56 프레임 | 75초 | 360초 |
| 80 프레임 | 110초. | 525초. |
| 240 프레임 | 340초. | 1610초(약 27분) |
| 600 프레임 | 860초. | 5128초(약 85분) |
| 1200 프레임. | 1710초(약 28분) | 10225초(약 170분) |
AnimateDiff를 기본 모델로
| 프레임 속도 | 더 빨라진 미리보기 추론 시간(256×256) | 최종 결과에 대한 추론 시간(720×720) |
|---|---|---|
| 24프레임 | 50초. | 180초. |
| 56 프레임 | 85초. | 370초. |
| 80 프레임 | 120초. | 535초. |
| 240 프레임 | 350초. | 1620초(약 27분) |
| 600 프레임 | 870초. | 5138초(~85분) |
| 1200 프레임. | 1720초(약 28분) | 10235초(약 170분) |
SVD기본 모델
| 프레임 속도 | 더 빨라진 미리보기 추론 시간(256×256) | 최종 결과에 대한 추론 시간(720×720) |
|---|---|---|
| 24프레임 | 80초. | 210초. |
| 56 프레임 | 115초. | 400초. |
| 80 프레임 | 150초. | 565초. |
| 240 프레임 | 380초. | 1650초(약 27분) |
| 600 프레임 | 900초. | 5168초(~86분) |
| 1200 프레임. | 1750초(약 29분) | 10265초(~171분) |
모든 측정은 NVIDIA A100(80GB) GPU를 사용하여 수행되었습니다. 프레임 수가 80개를 초과하면 랜덤 블렌딩을 사용했습니다. 무작위 혼합의 경우chunk_size의 값과overlap_size는 각각 112와 32로 설정되어 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서

댓글 없음...