
스텝-오디오-AQAA란 무엇인가요?
Step-Audio-AQAA는 StepFun 팀이 개발한 오디오 질의-오디오 응답(AQAA) 작업을 위한 엔드투엔드 대규모 오디오 언어 모델입니다. 기존의 자동 음성 인식(ASR) 및 텍스트 음성 변환(TTS) 모듈에 의존하지 않고 오디오 입력을 직접 처리하여 자연스럽고 정확한 음성 응답을 생성하는 기능은 시스템 아키텍처를 단순화하고 계단식 오류를 제거하며, Step-Audio-AQAA의 학습 프로세스에는 다중 모드 사전 학습, 감독 미세 조정(SFT), 직접 선호도 최적화(DPO) 및 모델 병합이 포함됩니다. 이러한 방법을 통해 모델은 음성 감정 제어, 역할 연기, 논리적 추론과 같은 복잡한 작업에서 우수한 성능을 발휘합니다. StepEval-Audio-360 벤치마크에서 Step-Audio-AQAA는 여러 주요 측면에서 기존 LALM 모델보다 뛰어난 성능을 보이며 엔드투엔드 음성 상호 작용에 대한 강력한 잠재력을 입증했습니다.
스텝-오디오-AQAA 주요 기능
- 오디오 입력 직접 처리기존의 자동 음성 인식(ASR) 및 텍스트 음성 변환(TTS) 모듈에 의존하지 않고 원시 오디오 입력에서 직접 음성 응답을 생성합니다.
- 원활한 음성 상호 작용음성 대 음성 상호작용을 지원하여 사용자가 음성으로 질문하면 모델이 음성으로 직접 답변하여 자연스럽고 매끄러운 상호작용이 가능합니다.
- 감정 톤 조정행복, 슬픔 또는 진지함과 같은 감정을 표현하는 등 문장 수준에서 감정적인 말투를 조정할 수 있도록 지원합니다.
- 음성 제어사용자는 필요에 따라 음성 응답 속도를 조정하여 시나리오의 요구 사항에 더 잘 대응할 수 있습니다.
- 톤 및 피치 제어사용자 명령에 따라 음성의 톤과 높낮이를 조정하여 다양한 역할이나 시나리오에 맞게 조정할 수 있습니다.
- 다국어 상호 작용다양한 사용자의 언어 요구 사항을 충족하기 위해 중국어, 영어, 일본어 및 기타 언어를 지원합니다.
- 방언 지원특정 지역에서 모델의 적용 가능성을 높이기 위해 사천어 및 광둥어와 같은 중국어 방언을 포함합니다.
- 음성 인식 감정 제어문맥과 사용자 명령에 따라 특정 감정을 담은 음성 응답을 생성할 수 있습니다.
- 롤플레잉(게임)고객 서비스, 선생님, 친구 등 대화에서 특정 역할을 연기하고 역할의 특성에 맞는 음성 응답을 생성하는 기능을 지원합니다.
- 논리적 추론 및 지식 퀴즈복잡한 논리적 추론 작업과 지식 퀴즈를 처리하여 정확한 음성 응답을 생성할 수 있습니다.
- 고품질 음성 출력뉴럴 보코더를 통해 자연스럽고 부드러운 고음질 음성 파형을 생성하여 사용자 경험을 향상시킵니다.
- 음성 일관성긴 문장이나 단락을 작성할 때 말의 일관성과 일관성을 유지하고, 끊어지거나 갑작스러운 말의 변화를 피하세요.
- 인터리브 텍스트 및 음성 출력텍스트 및 음성 인터리빙 출력을 지원하여 사용자가 필요에 따라 음성 또는 텍스트 응답을 선택할 수 있습니다.
- 멀티모달 입력 이해음성 및 텍스트가 포함된 혼합 입력을 이해하여 적절한 음성 응답을 생성할 수 있습니다.
Step-Audio-AQAA의 프로젝트 주소
- 허깅페이스 모델 라이브러리:: https://huggingface.co/stepfun-ai/Step-Audio-AQAA
- arXiv 기술 논문:: https://arxiv.org/pdf/2506.08967
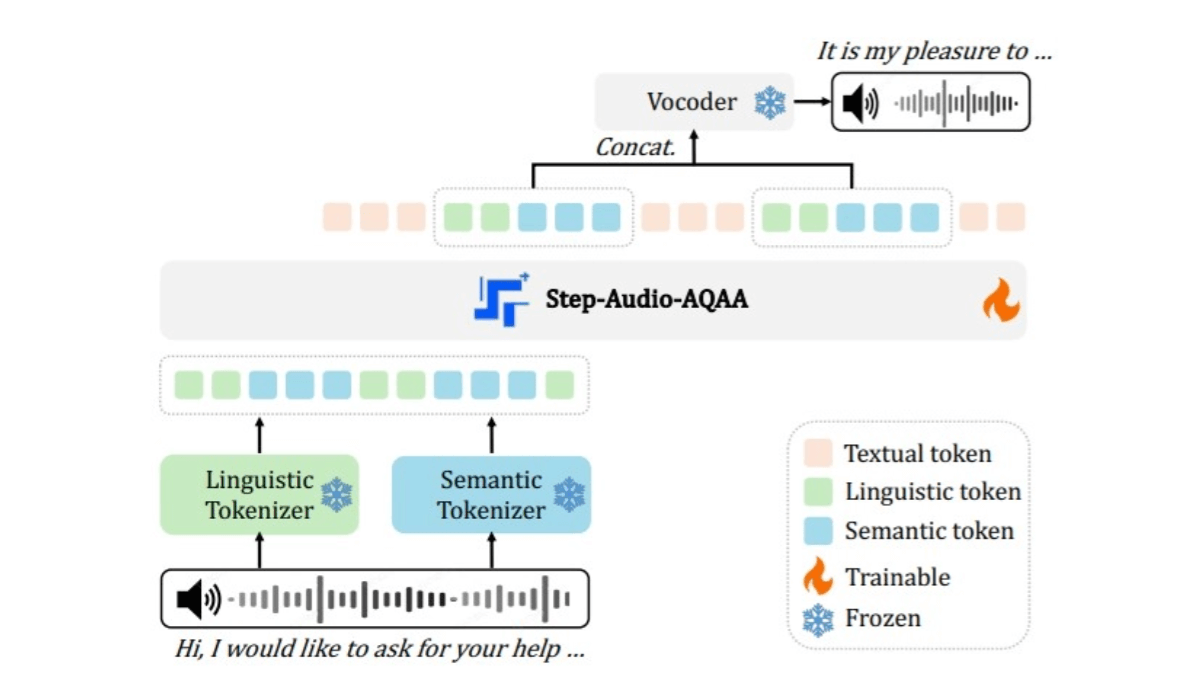
스텝-오디오-AQAA의 기술 원리
- 듀얼 코드북 오디오 분배기: 입력 오디오 신호를 구조화된 토큰 시퀀스로 변환합니다. 언어 사전은 코드북 크기 1024로 16.7Hz로 샘플링된 음성의 음소와 언어적 속성을 추출하고, 의미 사전은 코드북 크기 4096으로 25Hz로 샘플링된 음성의 감정, 억양 등 음향적 특징을 포착하는 두 가지 사전으로 구성되어 있어 음성 정보의 복잡성을 더 잘 포착할 수 있는 방식입니다.
- 백본 LLM사전 학습된 1,300억 개의 파라미터 멀티모달 LLM(스텝-옴니)을 사용하여 텍스트, 음성, 이미지의 세 가지 모달리티를 학습한 데이터입니다. 바이코드 텍스트 오디오 토큰은 균일한 벡터 공간에 여러 개의 트랜스포머 블록을 사용하여 심층적인 의미 이해와 특징 추출을 수행합니다.
- 뉴럴 보코더생성된 오디오 토큰을 자연스러운 고품질 음성 파형으로 합성합니다. ResNet-1D 레이어 및 트랜스포머 블록과 결합된 U-Net 아키텍처는 개별 오디오 토큰을 연속적인 음성 파형으로 효율적으로 변환합니다.
스텝-오디오-AQAA의 핵심 이점
- 엔드투엔드 오디오 상호 작용Step-Audio-AQAA는 원시 오디오 입력에서 직접 자연스럽고 부드러운 음성 응답을 생성하므로 기존의 자동 음성 인식(ASR) 및 텍스트 음성 변환(TTS) 모듈에 의존할 필요가 없습니다. 엔드투엔드 설계로 기존 솔루션의 ASR 또는 TTS 오류로 인한 결과 왜곡을 방지합니다.
- 다국어 지원중국어(사천어, 광둥어 포함), 영어, 일본어 등 여러 언어를 지원하여 다양한 사용자의 언어 요구 사항을 충족할 수 있습니다.
- 세분화된 음성 기능 제어Step-Audio-AQAA를 사용하면 감정 억양, 말 속도 등과 같은 세분화된 음성 기능을 제어하여 더욱 반응이 빠른 음성 응답을 생성할 수 있습니다. 특히 음성 감정 제어에 탁월합니다.
스텝-오디오-AQAA는 누구를 위한 서비스인가요?
- 지능형 음성 어시스턴트 사용자일상적인 작업(예: 정보 확인, 미리 알림 설정, 음악 재생 등)에 음성 대화 장치(예: 스마트 스피커, 스마트 비서)를 사용하고자 하는 사용자.
- 게임 애호가몰입감 있는 게임 경험을 위해 게임 내 NPC와 상호작용하는 것을 좋아하는 게이머.
- 교육 사용자음성 상호작용(예: 언어 학습, 지식 퀴즈 등)을 통해 학습하고자 하는 학생과 학부모를 위한 서비스입니다.
- 고령자 및 어린이텍스트 입력에 익숙하지 않은 사용자에게는 음성 상호작용이 더 편리하고 자연스럽습니다.
- 오디오북 제작자오디오북, 라디오 플레이 등 고품질의 음성 콘텐츠를 제작해야 하는 크리에이터.
- 동영상 제작자동영상 콘텐츠(예: 짧은 동영상, 라이브 스트리밍) 제작 시 음성 상호작용 또는 음성 생성 기능이 필요한 크리에이터.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서

댓글 없음...