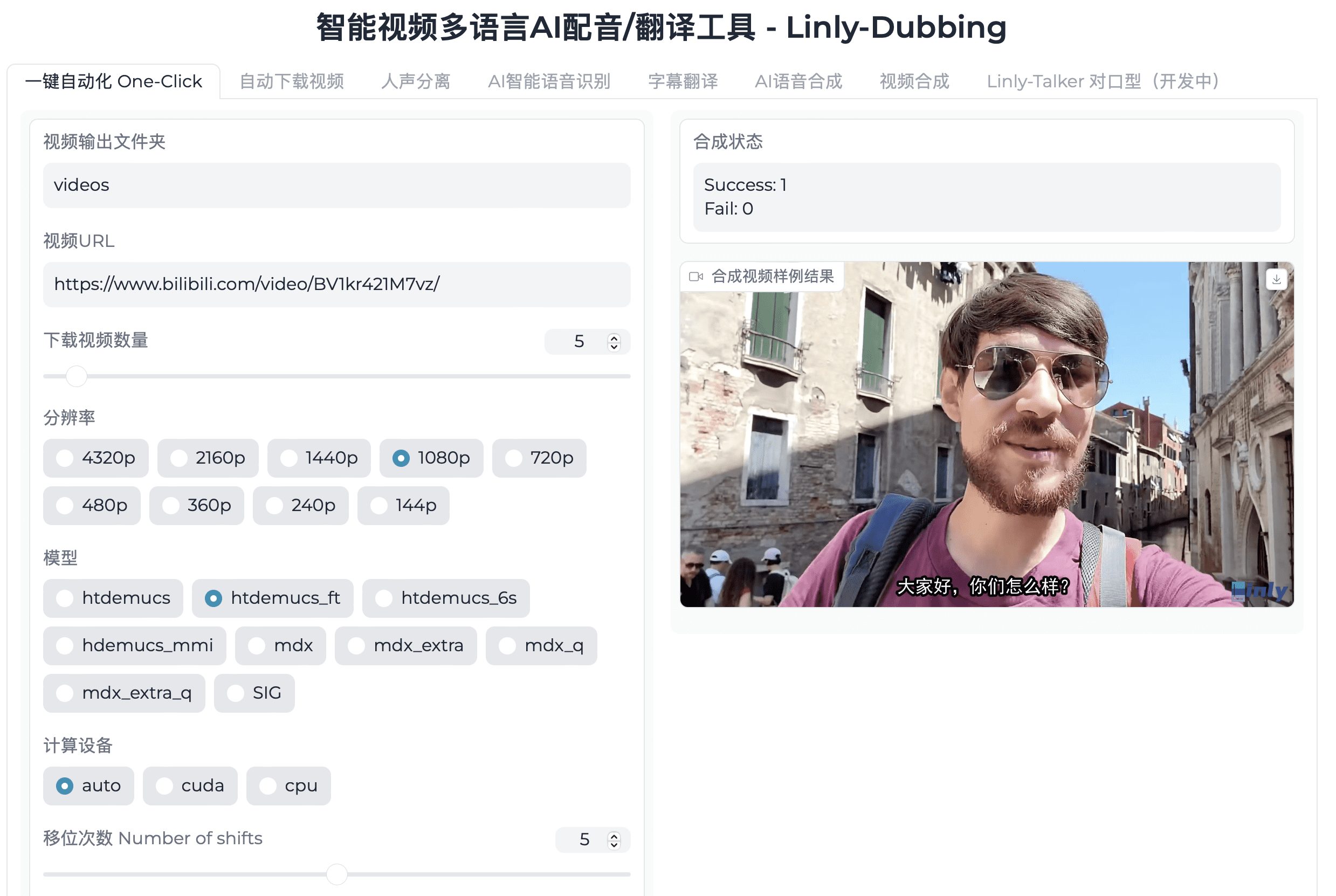

스텝오디오 2 미니란?
스텝 오디오 2 mini는 스텝스타의 오픈 소스 엔드투엔드 음성 매크로 모델입니다. 기존 음성 모델 구조를 탈피하고 진정한 엔드투엔드 멀티모달 아키텍처를 채택하여 원본 오디오 입력을 음성 응답 출력으로 직접 변환하여 지연 시간을 단축하고, 언어학적 정보 및 비음성 신호를 이해할 수 있습니다. 이 모델은 연쇄 추론과 강화 학습의 공동 최적화를 도입하여 감정과 억양에 대한 세밀한 이해와 반응을 제공하고 웹 검색과 같은 외부 도구를 지원하며 착시 문제를 효과적으로 해결하고 다중 장면 확장 기능을 향상시킵니다.

스텝오디오 2 미니 기능
- 엔드투엔드 오디오 처리원시 오디오 입력부터 음성 응답 출력까지, 텍스트의 중간 전사 과정이 필요 없어 보다 직접적이고 효율적으로 처리할 수 있습니다.
- 멀티모달 이해음성, 감정, 억양과 같은 비언어적 정보뿐만 아니라 비음성 신호를 이해하여 보다 자연스러운 상호 작용이 가능합니다.
- 강력한 음성 인식여러 언어와 방언의 음성 인식에서 뛰어난 성능과 높은 정확도를 제공합니다.
- 음성 번역 기능다국어 번역을 지원하여 사용자가 언어 장벽을 넘어 소통할 수 있도록 도와줍니다.
- 감성 및 의태어 구문 분석말의 감정적, 비유적 특징을 분석하여 상호작용을 더욱 감성적으로 만드는 능력입니다.
- 음성 대화 기능유창한 음성 커뮤니케이션을 통한 뛰어난 구두 대화 능력.
- 툴링 기능네트워크 검색과 같은 작업을 지원하여 최신 정보에 실시간으로 액세스하고 정확한 답변을 제공할 수 있습니다.
- 오디오 지식 향상외부 도구를 통해 지식 기반을 강화하여 팬텀 문제를 해결하고 멀티시나리오 애플리케이션을 개선합니다.
Step-Audio 2 mini의 핵심 이점
- 진정한 엔드투엔드 아키텍처오디오 입력에서 오디오 출력으로 바로 연결하여 중간 텍스트 변환 링크를 제거하여 지연 시간을 줄이고 효율성을 개선합니다.
- 멀티모달 이해음성 콘텐츠를 이해할 뿐만 아니라 감정, 억양과 같은 비언어적 정보도 감지하여 더욱 자연스럽고 지능적인 상호 작용을 가능하게 합니다.
- 뛰어난 음성 인식 정확도낮은 오류율과 높은 적응력으로 여러 언어와 방언의 음성 인식 성능이 뛰어납니다.
- 강력한 음성 번역 기능높은 번역 정확도로 여러 언어의 실시간 상호 번역을 지원하여 언어 간 커뮤니케이션을 촉진합니다.
- 감성 및 의태어 구문 분석말의 감정적, 언어적 특징을 정확하게 분석하여 대화를 더욱 인간적으로 만드는 능력입니다.
- 실시간 도구 호출 기능네트워크 검색 및 기타 통화와 같은 외부 도구를 지원하여 최신 정보에 실시간으로 액세스하고 보다 정확한 답변을 얻을 수 있습니다.
- 오픈 소스 및 간편한 사용이 모델은 오픈 소스로 개발자가 쉽게 다운로드하여 사용하고 2차 개발을 할 수 있으며 확장성이 뛰어납니다.
스텝오디오 2 미니의 공식 웹사이트는 무엇인가요?
- GitHub 리포지토리:: https://github.com/stepfun-ai/Step-Audio2
- 포옹하는 얼굴 모델 라이브러리:: https://huggingface.co/stepfun-ai/Step-Audio-2-mini
- 경험 주소:: https://realtime-console.stepfun.com
스텝오디오 2 미니는 누구를 위한 제품인가요?
- 개발자오픈 소스 기능을 2차 개발에 사용할 수 있으며, 다양한 애플리케이션에 통합하여 기능을 확장할 수 있습니다.
- 비즈니스 사용자서비스 효율성 향상을 위해 지능형 고객 서비스, 음성 비서 및 기타 서비스가 필요한 기업에 적합합니다.
- 교육자언어 교육, 온라인 교육 및 학생들에게 개인화된 학습 경험을 제공하는 데 사용할 수 있습니다.
- 콘텐츠 크리에이터팟캐스트 및 오디오북과 같은 오디오 콘텐츠를 생성하여 창의력을 발휘할 수 있도록 지원합니다.
- 일반 사용자스마트 홈 제어, 정보 조회 등 편리한 음성 인터랙션 서비스를 즐기세요.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서

댓글 없음...