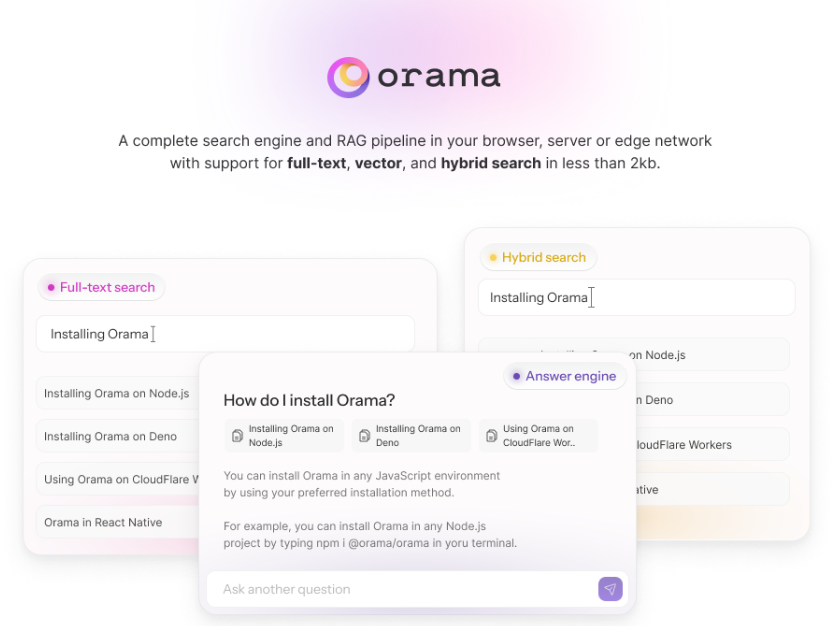

스탠인이란 무엇인가요?
스탠드인(Stand-In)은 텐센트 위챗 비전 팀이 개발한 가벼운 플러그 앤 플레이 방식의 신원 보존 동영상 생성 프레임워크입니다. 동영상 생성 시 특정 신원 특징을 보존하는 데 중점을 두고 기본 모델 1%의 추가 파라미터만 학습하면 얼굴 유사성과 자연스러움에서 탁월한 결과를 얻을 수 있으며, 신원 보존 텍스트-비디오 생성, 사람이 아닌 피사체 비디오 생성, 양식화된 비디오 생성, 얼굴 전환 비디오 및 포즈 가이드 비디오 생성 등 다양한 애플리케이션 시나리오를 지원합니다. 이 프레임워크는 효율적으로 학습되고 충실도가 높으며 플러그 앤 플레이 방식으로 확장성이 뛰어나고 LoRA와 같은 커뮤니티 모델과 호환되며 다양한 다운스트림 비디오 작업을 지원합니다.
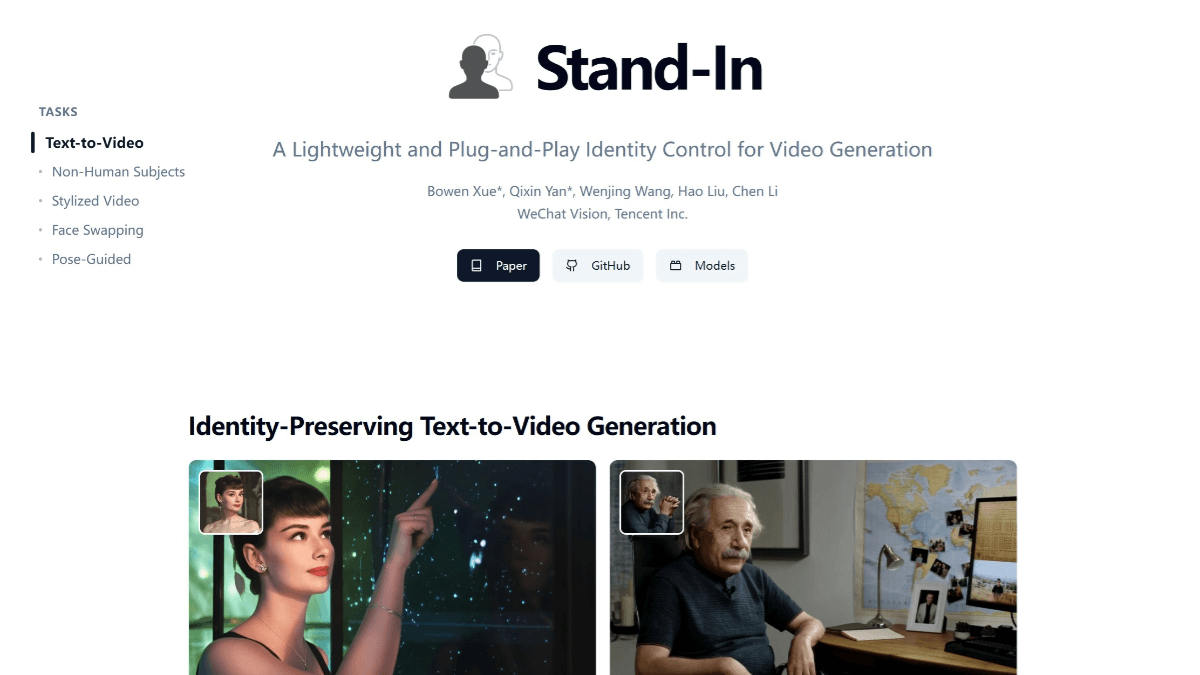
Stand-In의 기능 특징
- 효율적인 교육기본 모델 1%의 추가 파라미터만 학습하면 되므로 다른 방식에 비해 학습 비용이 대폭 절감됩니다.
- 높은 충실도얼굴 유사도 및 영상 자연스러움에서 탁월한 성능을 발휘하여 영상 품질 저하 없이 신원을 효과적으로 보존합니다.
- 플러그 앤 플레이복잡한 조정 없이 기존 텍스트-비디오(T2V) 모델에 쉽게 통합할 수 있습니다.
- 뛰어난 확장성LoRA와 같은 커뮤니티 모델과 호환되며, 양식화된 비디오 생성, 비디오 얼굴 교체 등 다양한 다운스트림 비디오 작업을 지원합니다.
- 다양한 애플리케이션 시나리오신원 보존을 위한 텍스트-비디오 생성, 사람이 아닌 피사체를 위한 비디오 생성, 포즈 가이드 비디오 생성 등 다양한 활용 시나리오를 지원합니다.
Stand-In의 핵심 강점
- 효율성기본 모델 1%의 추가 파라미터만 학습하면 되므로 학습 비용과 시간을 크게 줄일 수 있습니다.
- 높은 충실도얼굴 유사성 및 동영상 자연스러움이 뛰어나며, 동영상 생성 품질을 보장하면서 신원 특징을 정확하게 보존합니다.
- 손쉬운 통합플러그 앤 플레이 방식으로 복잡한 조정 없이 기존 텍스트-비디오(T2V) 모델에 원활하게 통합할 수 있습니다.
- 호환성LoRA와 같은 커뮤니티 모델과 호환성이 높고, 여러 다운스트림 비디오 작업을 지원하며, 확장성이 뛰어납니다.
- 다양한 애플리케이션 시나리오신원 보존을 위한 텍스트-비디오 생성, 사람이 아닌 피사체를 위한 비디오 생성, 양식화된 비디오 생성, 비디오 얼굴 바꾸기, 포즈 가이드 비디오 생성 등 다양한 시나리오를 다룹니다.
공식 대리인 웹사이트는 무엇인가요?
- 프로젝트 웹사이트:: https://www.stand-in.tech/
- GitHub 리포지토리:: https://github.com/WeChatCV/Stand-In
- 허깅페이스 모델 라이브러리:: https://huggingface.co/BowenXue/Stand-In
- arXiv 기술 논문:: https://arxiv.org/pdf/2508.07901
스탠드인의 대상
- 동영상 콘텐츠 제작자Stand-In으로 고품질의 개인 맞춤형 동영상 콘텐츠를 빠르게 생성하여 촬영 및 포스트 프로덕션에 드는 시간과 비용을 절약하세요.
- 영화 및 텔레비전 특수 효과 프로듀서Stand-In은 아이덴티티 교체 또는 특수 효과 합성이 필요할 때 효율적이고 자연스럽게 아이덴티티를 보존하는 영상을 생성하여 제작 효율성을 높입니다.
- 광고 및 마케팅 실무자타겟 오디언스와 유사한 사람들의 동영상을 생성하여 더욱 관련성 있고 설득력 있는 타겟 광고 동영상을 만드는 데 사용할 수 있습니다.
- 게임 개발자게임 플레이 애니메이션이나 동영상 프로모션에서 스탠드인을 사용하면 게임 캐릭터의 정체성과 일치하는 동영상 콘텐츠를 빠르게 생성하여 게임의 몰입도를 높일 수 있습니다.
- 연구자 및 교육자연구 프로젝트 또는 교육용 동영상 제작에서 교육을 지원하거나 연구 결과를 발표하기 위해 아이덴티티별 데모 동영상을 생성하는 데 사용할 수 있습니다.
- 소셜 미디어 운영자소셜 미디어 플랫폼에서 브랜드 이미지 또는 특정 주제에 맞는 동영상 콘텐츠를 빠르게 생성하여 홍보 및 사용자 상호작용을 유도할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...