

SRPO란?
SRPO(Semantic Relative Preference Optimization)는 텐센트 혼합 요소에서 도입한 텍스트-이미지 생성 모델로, 텍스트 조건부 신호를 통해 보상 메커니즘을 최적화하여 보상의 온라인 조정을 달성하고 오프라인 미세 조정에 대한 의존도를 줄이며, SRPO는 직접 정렬 기술을 도입하여 이후 단계에서 과도한 최적화를 방지하고 훈련의 효율성을 개선합니다. 효율성을 개선합니다. 이 모델은 생성된 이미지의 사실성과 미적 품질을 크게 향상시킬 수 있으며 디지털 아트 제작, 광고 및 마케팅, 게임 개발, 영화 및 TV 제작, VR/AR 분야에서 널리 사용되어 크리에이터에게 효율적이고 유연한 이미지 생성 솔루션을 제공합니다.
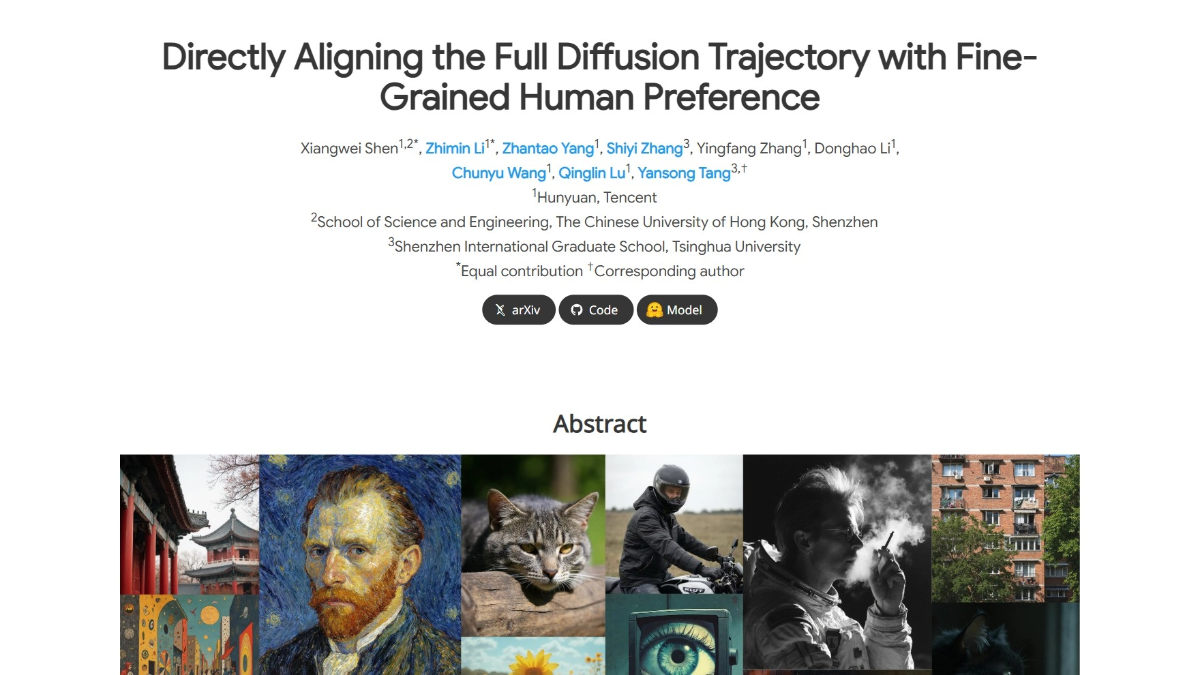
SRPO의 기능적 특징
- 이미지 품질 개선확산 모델을 최적화함으로써 SRPO는 더욱 사실적이고 디테일한 이미지를 생성하여 이미지의 사실성과 미적 품질을 크게 향상시킬 수 있습니다.
- 동적 보상 조정텍스트 프롬프트를 기반으로 사용자가 실시간으로 보상 신호를 조정할 수 있도록 지원하여 오프라인에서 미세 조정할 필요가 없으며 이미지 스타일과 기본 설정을 동적으로 변경할 수 있습니다.
- 적응력 향상이 모델은 다양한 조명 조건, 스타일 또는 디테일 수준에 대한 최적화와 같은 다양한 작업 요구 사항에 더 잘 적응하며 유연성이 뛰어납니다.
- 효율적인 교육확산 과정의 초기 단계를 최적화함으로써 SRPO는 단기간에 교육 및 최적화를 완료하여 교육 효율성을 크게 개선하고 시간과 리소스를 절약할 수 있습니다.
SRPO의 핵심 강점
- 온라인 보상 조정긍정 및 부정 큐 단어를 통해 보상 신호를 동적으로 조정하면 오프라인 보상 미세 조정에 대한 의존도가 줄어들고 모델 유연성이 향상됩니다.
- 이미지 생성 품질 향상이 모델은 확산 모델의 초기 시간 단계를 최적화하여 이미지의 사실성, 디테일 및 미적 품질을 크게 향상시킵니다.
- 보상형 해킹 방지상대적 선호 메커니즘과 부정적 보상 신호로 보상 해킹을 효과적으로 억제하고 훈련 안정성을 높입니다.
- 유연성 및 확장성텍스트 기반 조건부 신호 : 다양한 작업에 맞게 이미지 스타일을 조정할 수 있는 간단한 텍스트 프롬프트가 포함된 텍스트 기반 조건부 신호입니다.
SRPO의 공식 웹사이트는 무엇인가요?
- 프로젝트 웹사이트:: https://tencent.github.io/srpo-project-page/
- GitHub 리포지토리:: https://github.com/Tencent-Hunyuan/SRPO
- 허깅페이스 모델 라이브러리:: https://huggingface.co/tencent/SRPO
- arXiv 기술 논문:: https://arxiv.org/pdf/2509.06942v2
SRPO의 대상
- 디지털 아티스트 및 디자이너모델을 사용하여 고품질 디지털 아트웍을 빠르게 생성하고 반복하며, 텍스트 프롬프트를 통해 이미지 스타일을 유연하게 조정하고, 아이디어를 효율적으로 시각화할 수 있습니다.
- 광고 및 마케팅 직원모델을 사용하여 브랜드 스타일에 맞는 이미지를 생성하고, 다양한 디자인 옵션을 빠르게 제작하고, 크리에이티브 효율성을 높이고, 디자인 비용을 절감할 수 있습니다.
- 게임 개발자고품질 게임 텍스처, 캐릭터 및 장면 배경을 생성하여 개발 프로세스를 가속화하고 게임 비주얼을 향상시킵니다.
- 영화 제작자모델을 사용하여 사실적인 특수 효과 장면과 캐릭터를 생성하고, 후반 작업 비용을 절감하며, 영화 및 TV 프로덕션의 시각적 품질을 개선하세요.
- VR 및 AR 개발자고품질 가상 환경과 오브젝트로 모델링하여 VR 및 AR 애플리케이션의 몰입감과 사실감을 향상시킵니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서

댓글 없음...