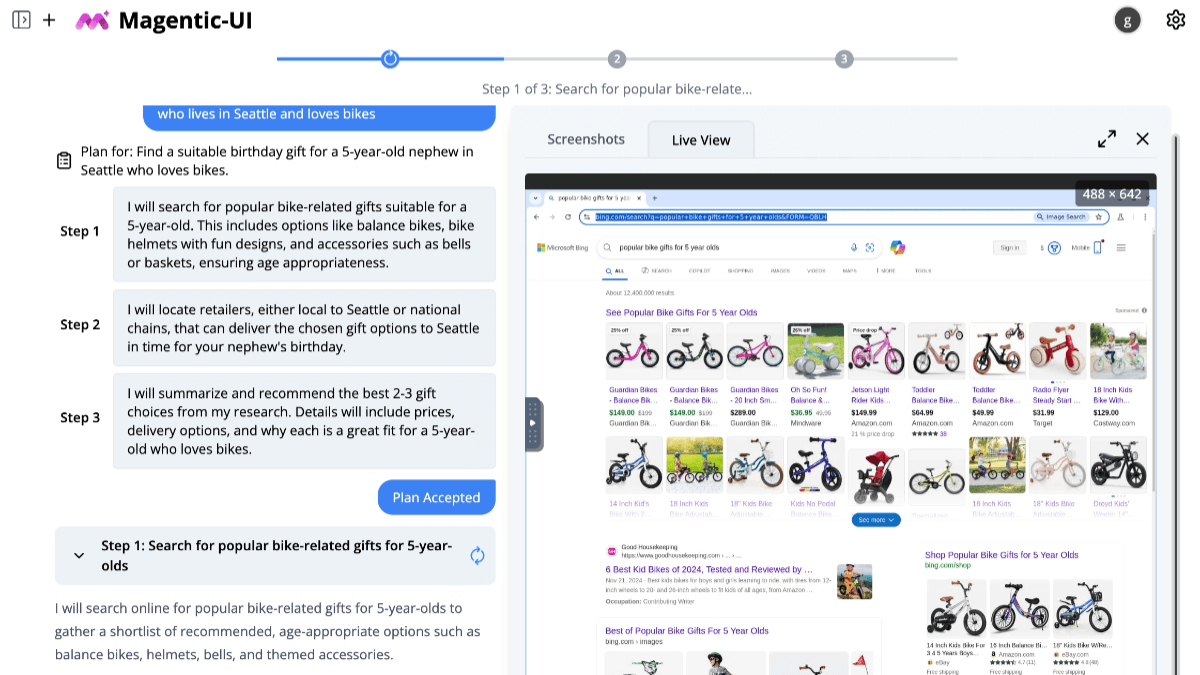

일반 소개
스몰도클링은 ds4sd 팀이 IBM과 협력하여 개발한 시각 언어 모델(VLM)로, 스몰VLM-256M을 기반으로 하며 허깅 페이스 플랫폼에서 호스팅됩니다. 이 모델은 매개변수가 256M에 불과한 세계에서 가장 작은 VLM으로, 핵심 기능은 이미지에서 텍스트를 추출하고 레이아웃, 코드, 수식 및 다이어그램을 인식하여 DocTags 형식의 구조화된 문서를 생성하는 것입니다. smolDocling은 일반 기기에서 높은 효율성과 낮은 리소스 소비로 실행할 수 있습니다. 개발팀은 더 많은 사람들이 문서 작업을 처리할 수 있도록 이 모델을 오픈소스를 통해 공유하고 있습니다. 문서 변환에 중점을 둔 SmolVLM 제품군의 일부로, 복잡한 문서를 빠르게 처리해야 하는 사용자에게 적합합니다.


기능 목록
- 텍스트 추출(OCR)이미지에서 텍스트를 인식 및 추출하고 다국어를 지원합니다.
- 레이아웃 식별: 그림에서 문서의 구조(예: 제목, 단락, 표의 위치)를 분석합니다.
- 코드 인식코드 블록을 추출하고 들여쓰기와 서식을 유지합니다.
- 공식 인식수학 공식을 감지하고 편집 가능한 텍스트로 변환합니다.
- 차트 인식: 이미지의 차트 내용을 구문 분석하여 데이터를 추출합니다.
- 양식 처리표의 구조를 식별하고 행과 열 정보를 유지합니다.
- 문서 태그 출력나중에 쉽게 사용할 수 있도록 처리 결과를 균일한 라벨링 형식으로 변환합니다.
- 고해상도 이미지 처리고해상도 이미지 입력을 지원하여 인식 정확도를 향상시킵니다.
도움말 사용
스몰도클링의 사용은 설치와 운영의 두 부분으로 나뉩니다. 다음은 사용자가 빠르게 시작할 수 있도록 도와주는 자세한 단계입니다.
설치 프로세스
- 환경 준비하기
- 컴퓨터에 Python 3.8 이상이 설치되어 있는지 확인하세요.
- 터미널에 다음 명령을 입력하여 종속성 라이브러리를 설치합니다:
pip install torch transformers docling_core - GPU가 있는 경우 더 빠르게 실행하려면 CUDA를 지원하는 PyTorch를 설치하는 것이 좋습니다. 방법론을 확인하세요:
import torch print("GPU可用:" if torch.cuda.is_available() else "使用CPU")
- 모델 로드
- 스몰도클링은 수동으로 다운로드할 필요가 없으며, 코드를 통해 허깅페이스에서 바로 사용할 수 있습니다.
- 네트워크가 열려 있고 처음 실행할 때 모델 파일이 자동으로 다운로드되는지 확인합니다.
사용 단계
- 사진 준비
- 스캔한 문서나 스크린샷 등 텍스트가 포함된 이미지를 찾습니다.
- 코드와 함께 이미지를 로드합니다:
from transformers.image_utils import load_image image = load_image("你的图片路径.jpg")
- 모델 및 프로세서 초기화하기
- 스몰도클링의 프로세서와 모델을 로드합니다:
from transformers import AutoProcessor, AutoModelForVision2Seq DEVICE = "cuda" if torch.cuda.is_available() else "cpu" processor = AutoProcessor.from_pretrained("ds4sd/SmolDocling-256M-preview") model = AutoModelForVision2Seq.from_pretrained( "ds4sd/SmolDocling-256M-preview", torch_dtype=torch.bfloat16 ).to(DEVICE)
- 스몰도클링의 프로세서와 모델을 로드합니다:
- 문서 태그 생성
- 입력을 설정하고 모델을 실행합니다:
messages = [{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": "Convert this page to docling."}]}] prompt = processor.apply_chat_template(messages, add_generation_prompt=True) inputs = processor(text=prompt, images=[image], return_tensors="pt").to(DEVICE) generated_ids = model.generate(**inputs, max_new_tokens=8192) doctags = processor.batch_decode(generated_ids[:, inputs.input_ids.shape[1]:], skip_special_tokens=False)[0].lstrip() print(doctags)
- 입력을 설정하고 모델을 실행합니다:
- 공통 포맷으로 변환
- 문서 태그를 마크다운 또는 다른 형식으로 변환합니다:
from docling_core.types.doc import DoclingDocument doc = DoclingDocument(name="我的文档") doc.load_from_doctags(doctags) print(doc.export_to_markdown())
- 문서 태그를 마크다운 또는 다른 형식으로 변환합니다:
- 고급 사용법(선택 사항)
- 여러 페이지로 구성된 문서 처리여러 이미지를 반복해서 처리한 다음 문서 태그를 병합합니다.
- 성능 최적화: 설정
torch_dtype=torch.bfloat16메모리 절약, GPU 사용자는 다음을 활성화할 수 있습니다.flash_attention_2가속:model = AutoModelForVision2Seq.from_pretrained( "ds4sd/SmolDocling-256M-preview", torch_dtype=torch.bfloat16, _attn_implementation="flash_attention_2" if DEVICE == "cuda" else "eager" ).to(DEVICE)
운영 기술
- 사진 요구 사항이미지가 선명하고 텍스트를 읽을 수 있어야 하며 해상도가 높을수록 좋습니다.
- 조정 매개변수결과가 불완전한 경우 다음을 추가합니다.
max_new_tokens(기본값 8192). - 배치 파일여러 이미지를 목록으로 전달할 수 있습니다.
images=[image1, image2]. - 시운전 방법출력 중간 결과 확인(예: 인쇄)
inputs입력이 올바른지 확인합니다.
주의
- 처음 실행할 때는 인터넷 액세스가 필요하며, 그 이후에는 오프라인에서 사용할 수 있습니다.
- 너무 큰 사진은 메모리 부족을 초래할 수 있으므로 잘라서 처리하는 것이 좋습니다.
- 오류가 발생하면 Python 버전과 종속 라이브러리가 올바르게 설치되었는지 확인하세요.
위의 단계를 통해 사용자는 SmolDocling으로 이미지를 구조화된 문서로 변환할 수 있습니다. 전체 프로세스는 간단하며 초보자와 전문 사용자에게 적합합니다.
애플리케이션 시나리오
- 학술 연구
스캔한 문서를 텍스트로 변환하고 수식과 표를 추출하여 쉽게 편집하고 인용할 수 있습니다. - 프로그래밍 문서
코드가 포함된 수동 이미지를 마크다운으로 변환하여 개발자를 위해 코드 서식을 보존합니다. - 사무 자동화
계약서, 보고서 등의 스캔 사본을 처리하고 레이아웃과 내용을 인식하여 효율성을 개선하세요. - 교육 지원
교과서 이미지를 편집 가능한 문서로 전환하여 교사와 학생이 노트를 정리할 수 있도록 도와주세요.
QA
- 스몰도클링과 스몰VLM의 차이점은 무엇인가요?
스몰도클링은 문서 처리와 문서 태그 형식 출력에 중점을 둔 최적화된 버전의 스몰VLM-256M을 기반으로 하는 반면, 스몰VLM은 보다 일반적이며 이미지 설명과 같은 작업을 지원합니다. - 어떤 운영 체제가 지원되나요?
Windows, Mac, Linux가 지원되며 Python 및 종속 라이브러리가 설치된 상태에서 실행할 수 있습니다. - 처리가 빠른가요?
이미지 처리에는 일반 컴퓨터에서는 몇 초밖에 걸리지 않으며, GPU 사용자의 경우 일반적으로 1초 미만으로 더 빠릅니다. - 손으로 쓴 텍스트를 처리할 수 있나요?
예. 그러나 결과는 필기의 선명도에 따라 달라지며 최상의 결과를 얻으려면 인쇄된 텍스트 이미지를 사용하는 것이 좋습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...