
GPUStack을 사용한 Dify용 RAG 3팩의 신속한 배포

GPUStack 빅 모델 솔루션의 로컬 프라이빗 배포를 제공하기 위해 엔비디아, 애플 메탈, 화웨이 라이즈, 무어 스레드 등 다양한 이기종 GPU/NPU 리소스를 효율적으로 통합하고 활용할 수 있는 오픈소스 빅 모델 서비스 플랫폼입니다.
GPUStack은 다음을 지원할 수 있습니다. RAG 시스템에 필요한 세 가지 핵심 모델인 채팅 대화 모델(대규모 언어 모델), 임베딩 텍스트 임베딩 모델, 순위 재지정 모델은 3종 세트로 제공되며, RAG 시스템에 필요한 로컬 비공개 모델을 배포하는 것은 매우 간단하고 완벽한 작업입니다.
GPUStack 및 Dify를 설치하는 방법은 다음과 같습니다. Dify 를 사용하여 대화 모델, 임베딩 모델 및 리랭커 모델과 인터페이스할 수 있습니다.
GPUStack 설치
다음 명령을 사용하여 Linux 또는 macOS에서 온라인으로 설치하며, 설치 과정에서 sudo 비밀번호가 필요합니다: curl -sfL https://get.gpustack.ai | sh -
GitHub에 연결하여 일부 바이너리를 다운로드할 수 없는 경우 다음 명령을 사용하여 다음 명령을 사용하여 설치하세요. --tools-download-base-url 이 매개변수는 텐센트 클라우드 오브젝트 스토리지에서 다운로드하도록 지정합니다:curl -sfL https://get.gpustack.ai | sh - --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
Windows에서 관리자 권한으로 Powershell을 실행하고 다음 명령을 사용하여 온라인으로 설치합니다:Invoke-Expression (Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content
GitHub에 연결하여 일부 바이너리를 다운로드할 수 없는 경우 다음 명령을 사용하여 다음 명령을 사용하여 설치하세요. --tools-download-base-url 이 매개변수는 텐센트 클라우드 오브젝트 스토리지에서 다운로드하도록 지정합니다:Invoke-Expression "& { $((Invoke-WebRequest -Uri 'https://get.gpustack.ai' -UseBasicParsing).Content) } --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
다음 출력이 표시되면 GPUStack이 성공적으로 배포 및 시작된 것입니다:
[INFO] Install complete. GPUStack UI is available at http://localhost. Default username is 'admin'. To get the default password, run 'cat /var/lib/gpustack/initial_admin_password'. CLI "gpustack" is available from the command line. (You may need to open a new terminal or re-login for the PATH changes to take effect.)
그런 다음 스크립트 출력의 지침에 따라 GPUStack에 로그인하기 위한 초기 비밀번호를 얻은 후 다음 명령을 실행합니다:
Linux 또는 macOS에서:cat /var/lib/gpustack/initial_admin_password
Windows에서:Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustackinitial_admin_password") -Raw
브라우저에서 사용자 이름 admin과 비밀번호를 위에서 얻은 초기 비밀번호로 사용하여 GPUStack UI에 액세스합니다.
비밀번호를 재설정한 후 GPUStack을 입력합니다: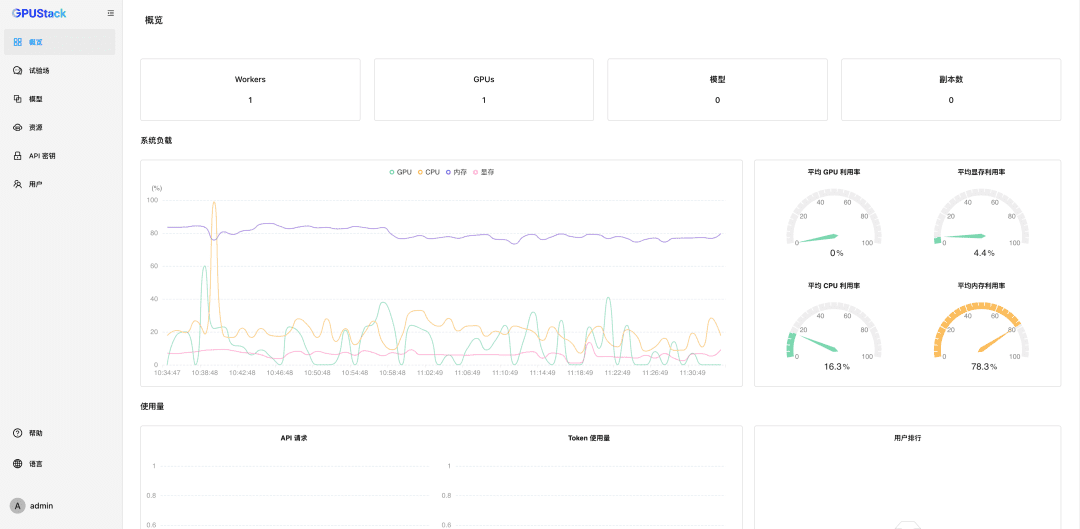
나노 관리 GPU 리소스
GPUStack은 Linux, Windows 및 macOS 디바이스의 GPU 리소스를 지원하며, 다음 단계에 따라 이러한 GPU 리소스를 관리합니다.
다른 노드를 인증해야 합니다. 토큰 GPUStack 클러스터에 가입하고 GPUStack 서버 노드에서 다음 명령을 실행하여 토큰을 얻습니다:
Linux 또는 macOS에서:cat /var/lib/gpustack/token
Windows에서:Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustacktoken") -Raw
토큰이 있으면 다른 노드에서 다음 명령을 실행하여 GPUStack에 워커를 추가하고 해당 노드의 GPU를 나노 관리합니다(http://YOUR_IP_ADDRESS 을 GPUStack 액세스 주소로, YOUR_TOKEN 을 워커 추가에 사용된 인증 토큰으로 바꿉니다):
Linux 또는 macOS에서:curl -sfL https://get.gpustack.ai | sh - --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
Windows에서:Invoke-Expression "& { $((Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content) } --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
위의 단계를 통해 GPUStack 환경을 만들고 여러 GPU 노드를 관리한 다음 프라이빗 빅 모델을 배포하는 데 사용할 수 있습니다.
프라이빗 매크로 모델 배포
GPUStack을 방문하여 모델 메뉴에서 모델을 배포하세요. GPUStack은 HuggingFace, 올라마 라이브러리, ModelScope 및 비공개 모델 저장소에서 모델을 배포하는 것을 지원하며, 국내 네트워크에는 ModelScope를 권장합니다.
GPUStack 지원 vLLM 및 llama-box 추론 백엔드에 비해 vLLM은 프로덕션 추론에 최적화되어 있으며 동시성 및 성능 측면에서 프로덕션 요구 사항에 더 적합하지만 vLLM은 Linux에서만 지원됩니다. llama-box는 유연하고 멀티 플랫폼 호환 가능한 추론 엔진으로 llama.cpp Linux, Windows, macOS 시스템을 지원하며 GPU 환경뿐만 아니라 대형 모델을 실행하기 위한 CPU 환경도 지원하므로 멀티 플랫폼 호환성이 필요한 시나리오에 더욱 적합합니다.
GPUStack은 모델을 배포할 때 모델 파일 유형에 따라 적절한 추론 백엔드를 자동으로 선택합니다. 모델이 GGUF 형식이면 llama-box를 백엔드로 사용하여 모델 서비스를 실행하고, 비-GGUF 형식이면 vLLM을 백엔드로 사용하여 모델 서비스를 실행합니다.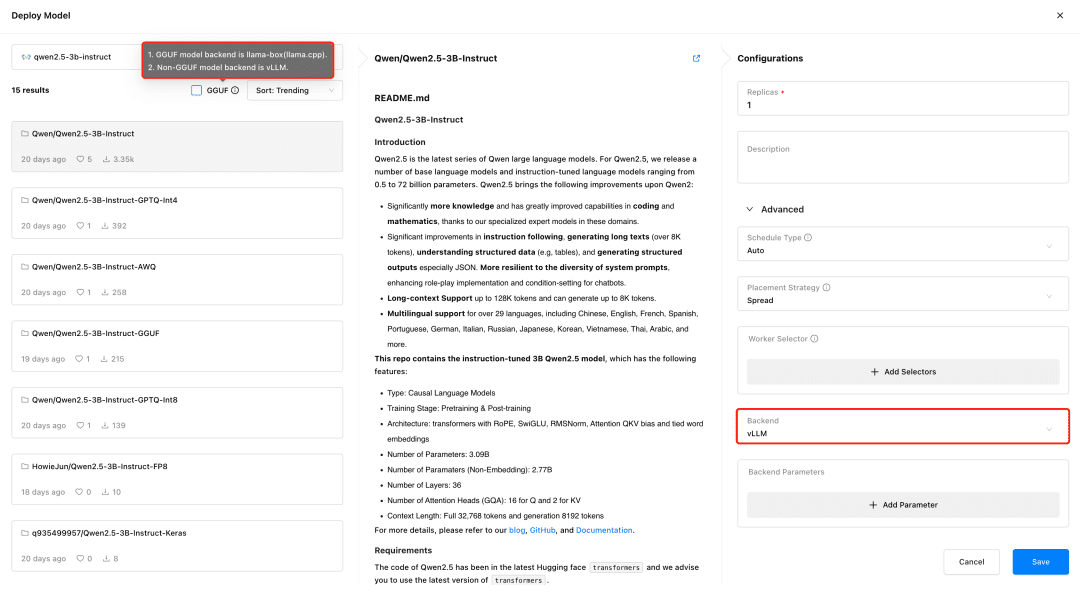
디파이 도킹에 필요한 텍스트 대화 모델, 임베딩 텍스트 임베딩 모델, 리랭커 모델을 배포하고, 배포 시 GGUF 형식을 확인하는 것을 잊지 마세요:
- Qwen/Qwen2.5-7B-Instruct-GGUF
- gpustack/bge-m3-GGUF
- gpustack/bge-reranker-v2-m3-GGUF
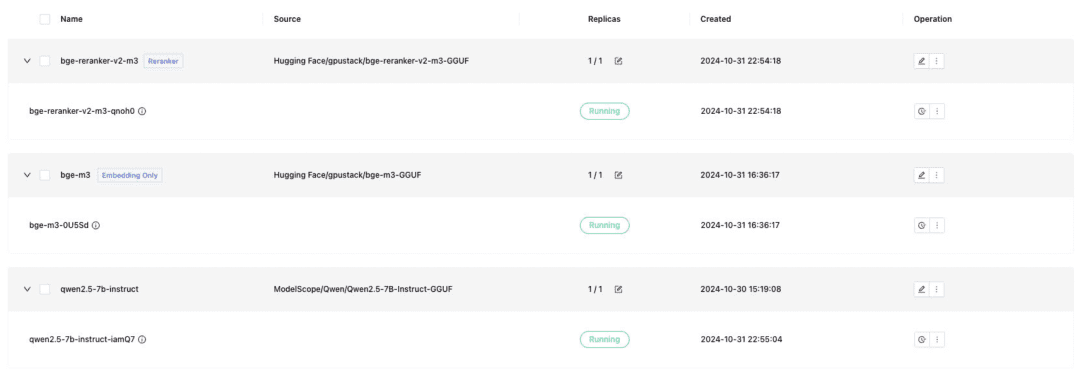
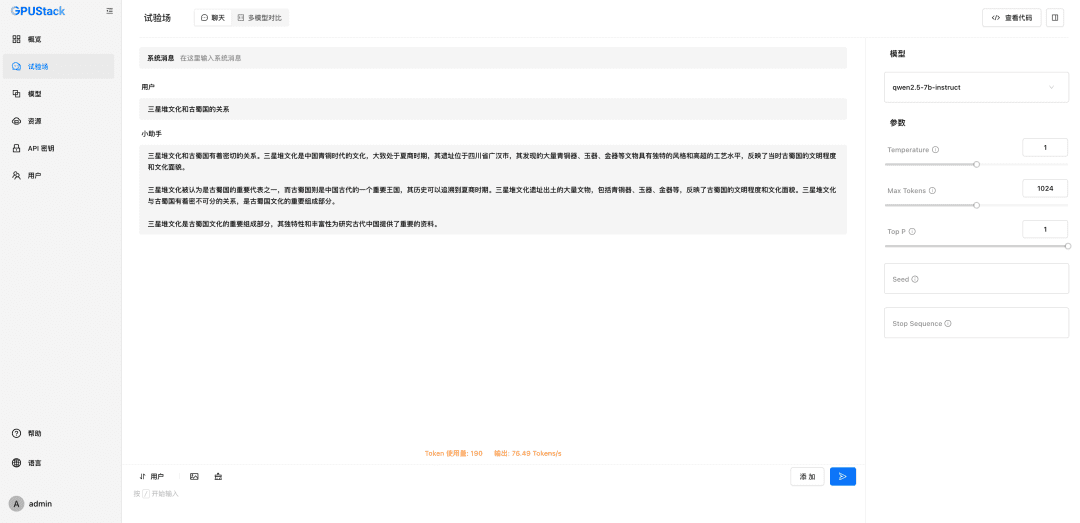
또한 GPUStack은 배포 시 vLLM 추론 백엔드를 사용해야 하는 VLM 멀티모달 모델도 지원합니다:
Qwen2-VL-2B-Instruct 

모델이 배포되면, RAG 시스템 또는 기타 생성 AI 애플리케이션은 GPUStack에서 제공하는 OpenAI / Jina 호환 API를 통해 GPUStack 배포 모델과 인터페이스할 수 있으며, 그 다음에는 Dify를 통해 GPUStack 배포 모델과 인터페이스할 수 있습니다.
통합 GPUStack 모델 수정
Dify 설치
Docker를 사용하여 Dify를 실행하려면 Docker 환경을 준비해야 하며, Dify와 GPUStack의 포트 80이 충돌하지 않도록 주의하고, 다른 호스트를 사용하거나 포트를 수정해야 합니다. 다음 명령을 실행하여 Dify를 설치합니다:git clone -b 0.10.1 https://github.com/langgenius/dify.git관리자 계정을 초기화하고 로그인하려면 Dify의 UI 인터페이스(http://localhost)를 방문하세요.
cd dify/docker/
cp .env.example .env
docker compose up -d
먼저 채팅 대화 모델을 통합하려면 먼저 Dify의 오른쪽 상단에서 "설정 - 모델 제공자"를 선택하고 목록에서 GPUStack 유형을 찾은 다음 모델 추가를 선택합니다:
GPUStack에 배포된 LLM 모델 이름(예: qwen2.5-7b-instruct), GPUStack의 액세스 주소(예: http://192.168.0.111) 및 생성된 API 키, 모델 설정 8192 및 최대 컨텍스트 길이를 입력합니다. 토큰 2048: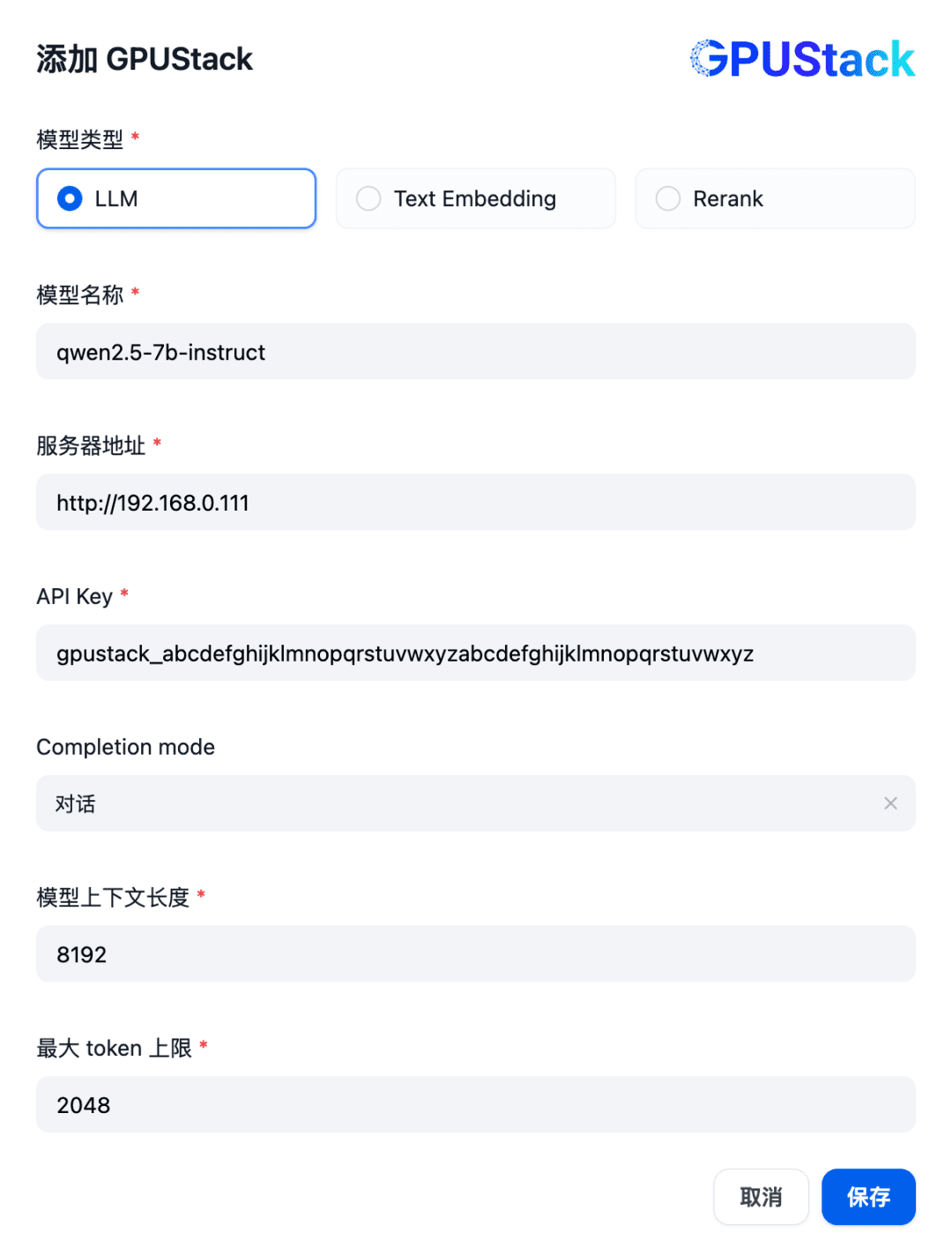
다음으로 임베딩 모델을 추가하고 모델 제공자 상단에서 GPUStack 유형을 선택한 다음 모델 추가를 선택합니다: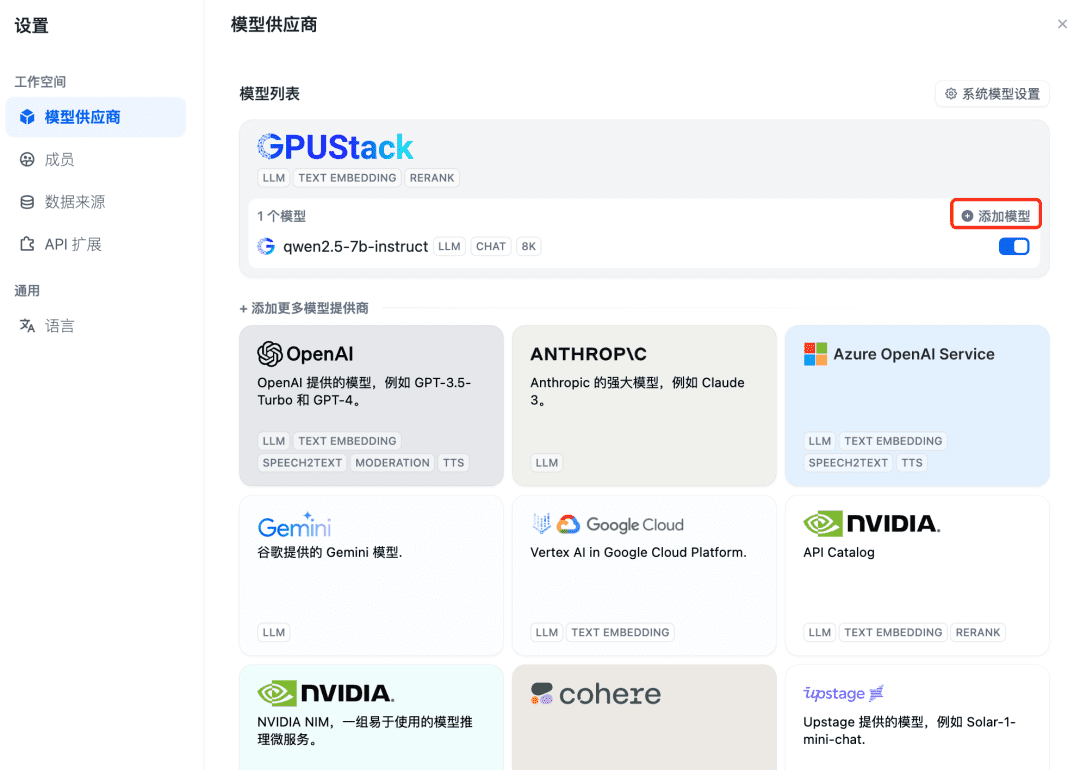
텍스트 임베딩 유형의 모델을 추가하고, GPUStack에 배포된 임베딩 모델의 이름(예: bge-m3), GPUStack의 액세스 주소(예: http://192.168.0.111) 및 생성된 API 키, 모델 설정에 대한 컨텍스트 길이 8192를 입력합니다: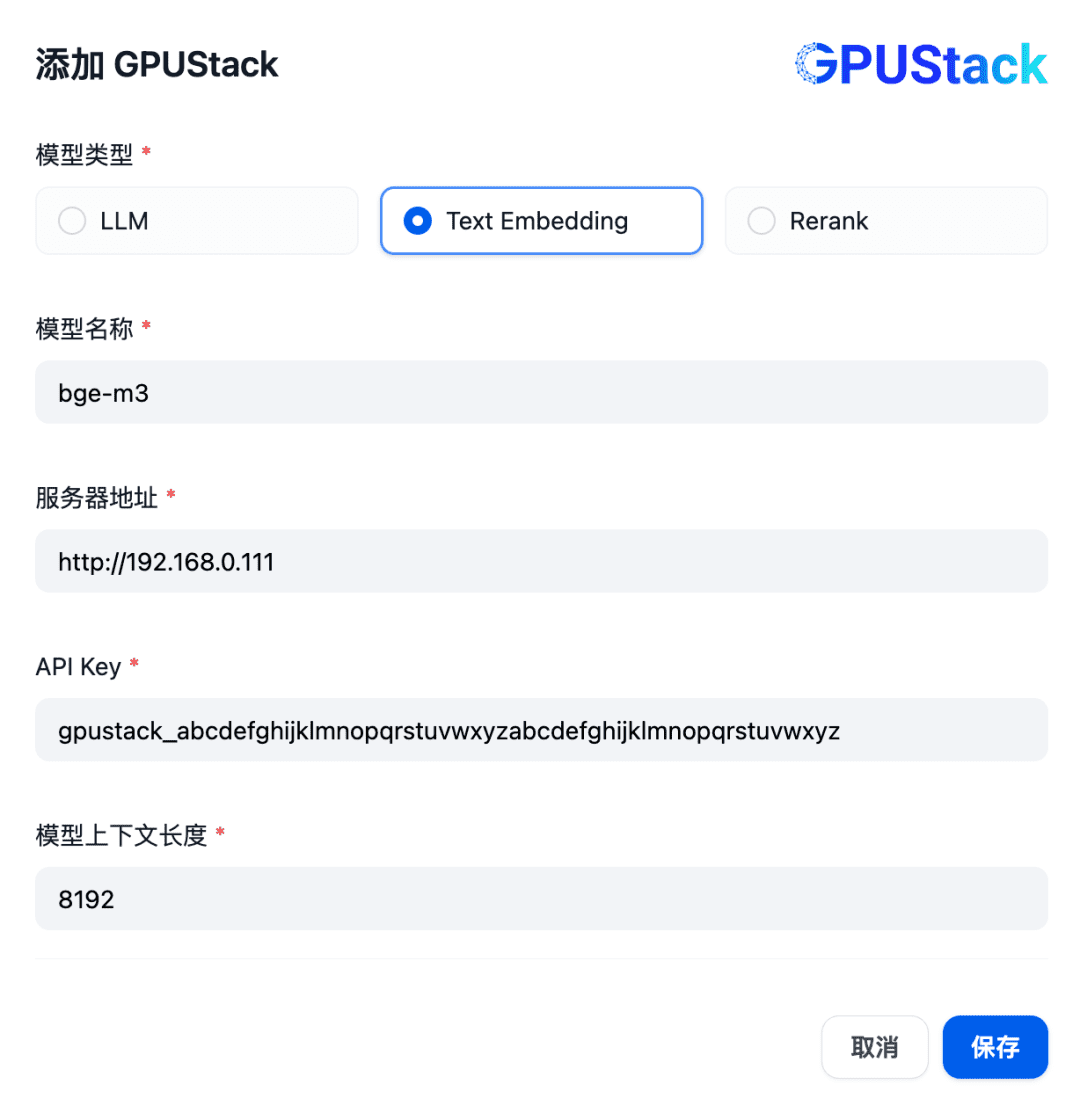
다음으로, Rerank 모델을 추가하려면 GPUStack 유형을 선택하고, 모델 추가를 선택하고, Rerank 유형의 모델을 추가하고, GPUStack에 배포된 Rerank 모델의 이름(예: bge-reranker-v2-m3), GPUStack의 액세스 주소(예: http://192.168. 0.111), 생성된 API 키, 그리고 모델 설정에 대한 컨텍스트 길이 8192입니다: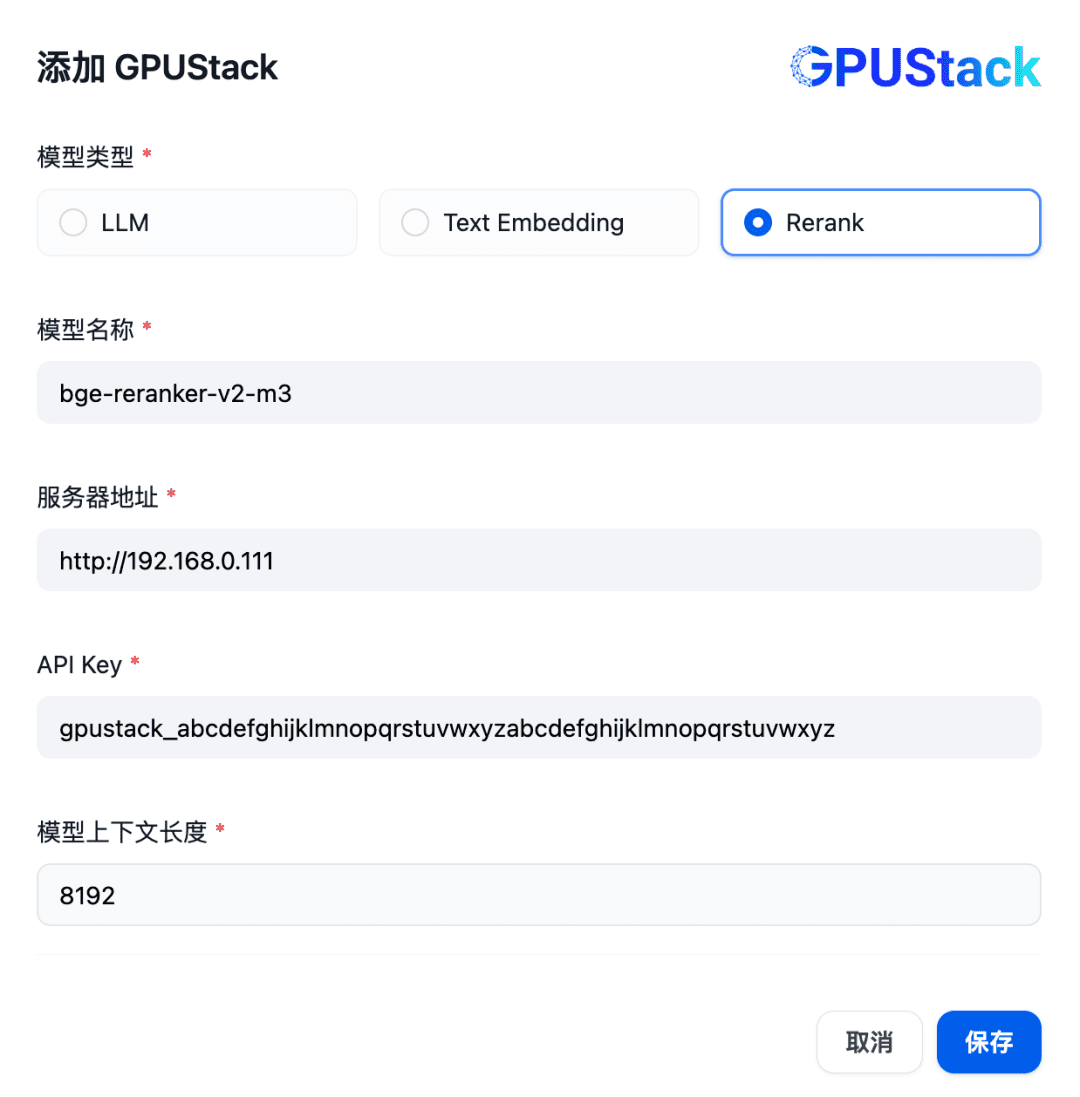
추가 후 새로고침한 다음 모델 공급자에서 위에 추가된 세 가지 모델에 대해 시스템 모델이 구성되었는지 확인합니다: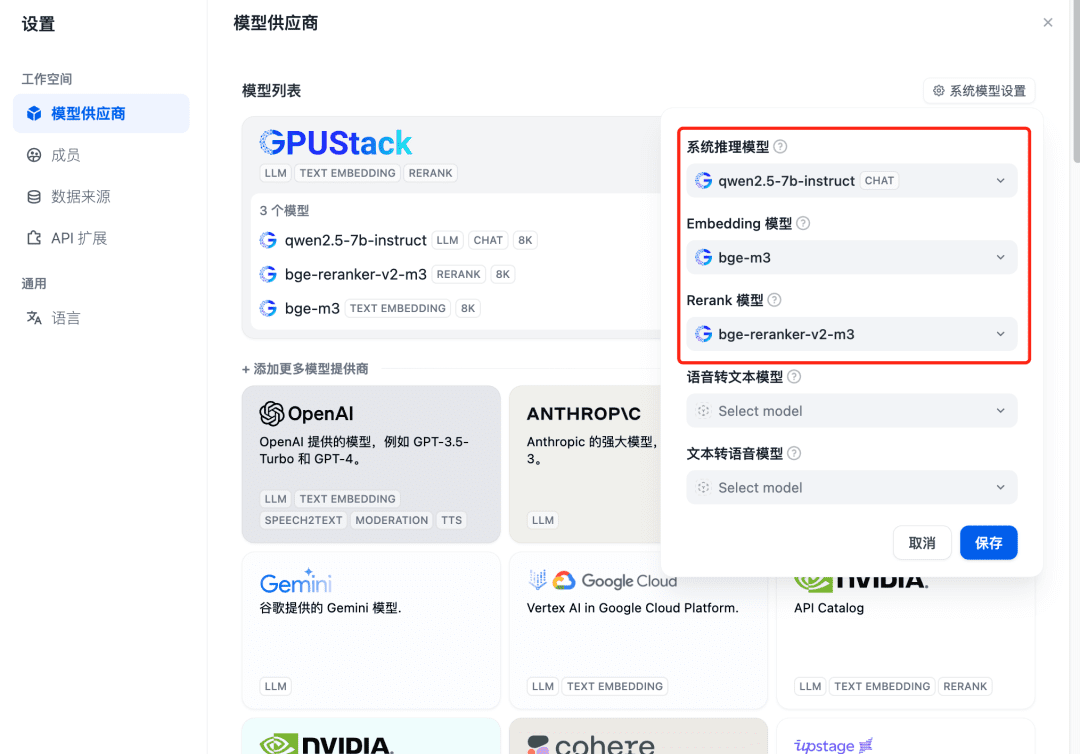
RAG 시스템에서 모델 사용 Dfiy의 지식창고를 선택하고, 지식창고 만들기를 선택하고, 텍스트 파일을 가져오고, 모델 포함 옵션을 확인하고, 검색 설정에 권장 하이브리드 검색을 사용하고, 모델 재순위를 설정합니다: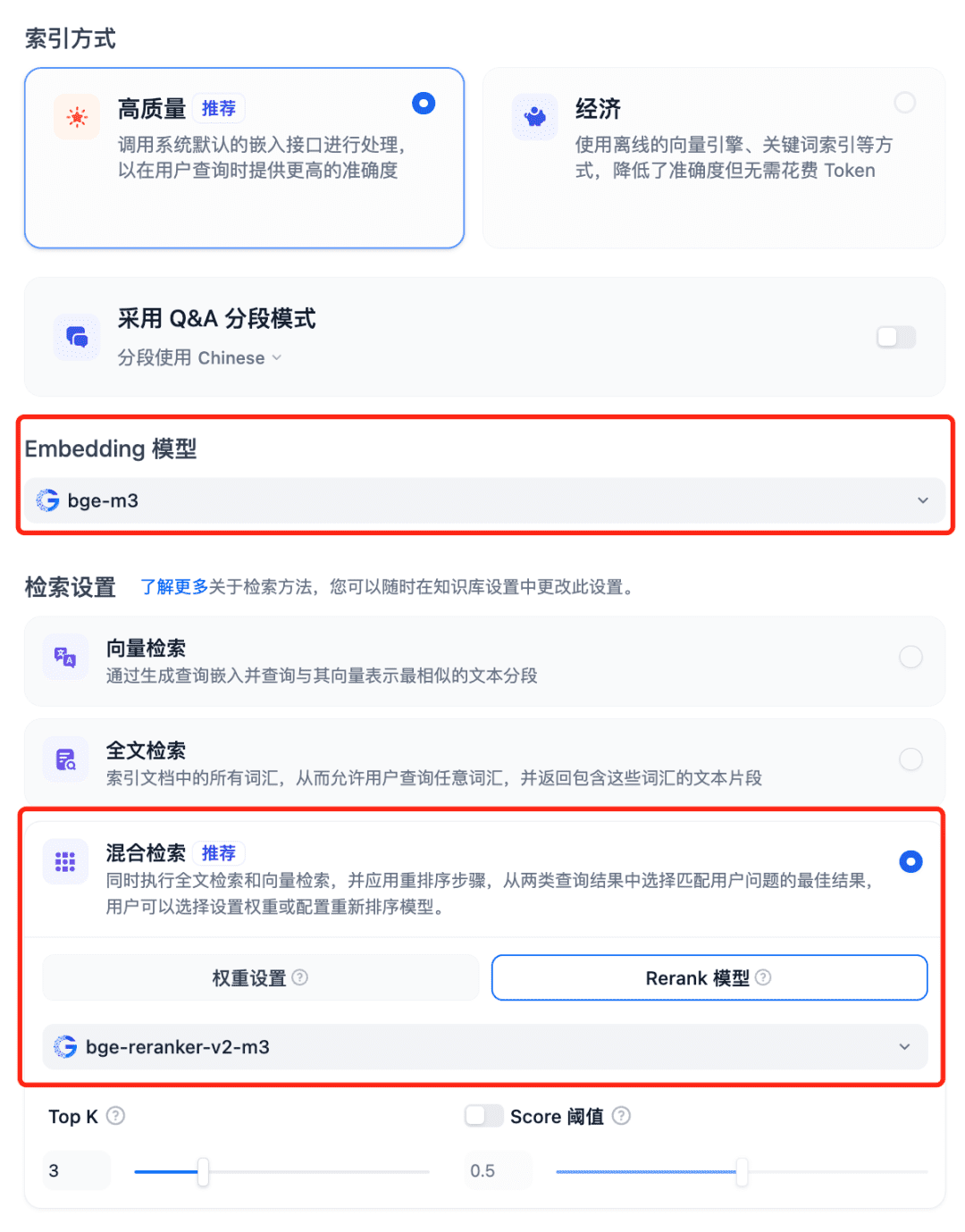
문서를 저장하고 벡터화 프로세스를 시작합니다. 벡터화가 완료되면 지식창고를 사용할 준비가 된 것입니다.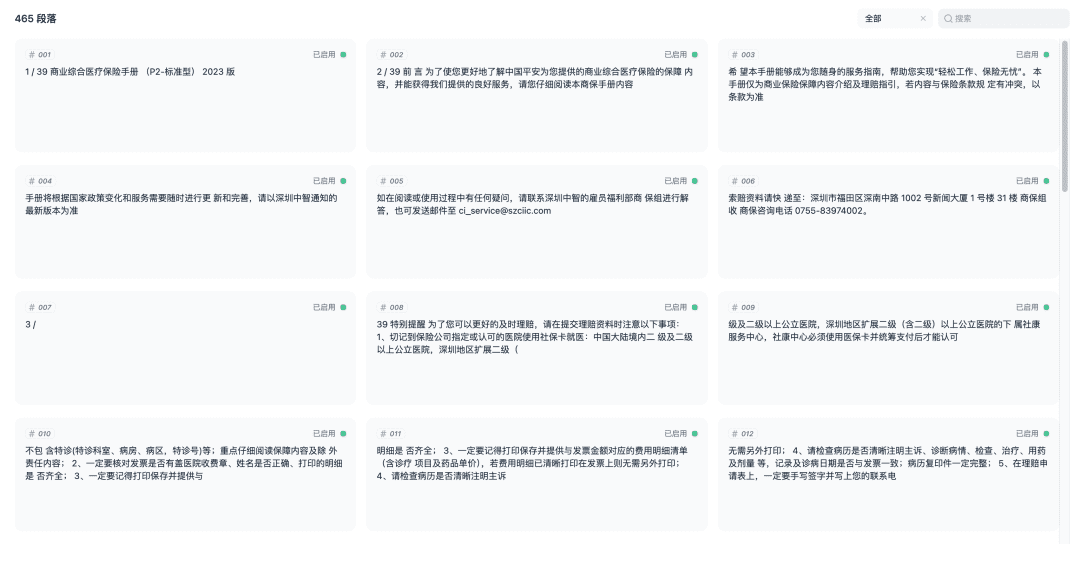
리콜 테스트를 통해 지식창고의 리콜 효과를 확인할 수 있으며, 더 나은 리콜 결과를 얻기 위해 더 많은 관련 문서를 리콜하도록 리랭크 모델을 개선할 수 있습니다: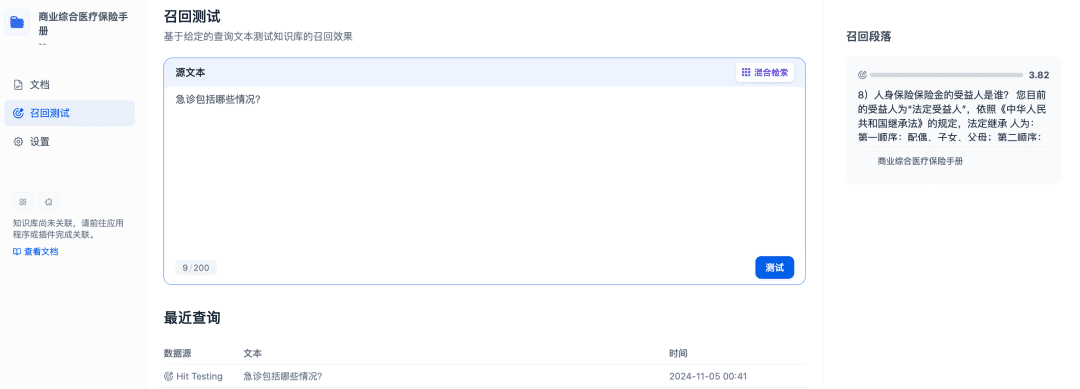
다음으로 채팅방에서 채팅 도우미 앱을 만듭니다:
관련 지식창고가 사용하려는 컨텍스트에 추가되며, 이때 채팅 모델, 임베딩 모델, 리랭크 모델 등이 함께 작동하여 RAG 애플리케이션을 지원하며, 임베딩 모델은 벡터화를 담당하고 리콜의 내용을 미세 조정하며 채팅 모델은 질문의 내용 및 리콜의 컨텍스트에 따라 답변을 담당하게 됩니다: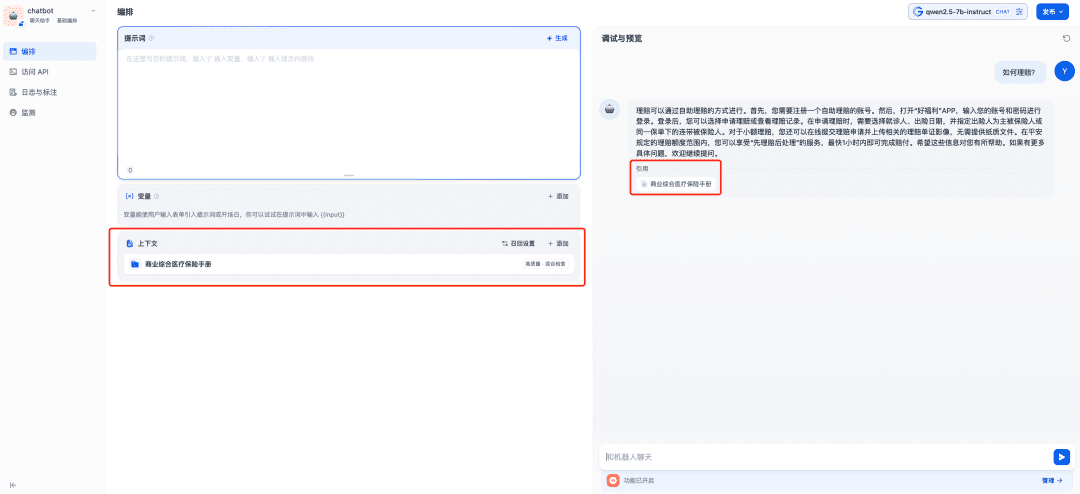
위는 Dify를 사용하여 GPUStack 모델과 인터페이스하는 예시입니다. 다른 RAG 시스템도 OpenAI/지나 호환 API를 통해 GPUStack과 인터페이스할 수 있으며, RAG 시스템을 지원하기 위해 GPUStack 플랫폼에서 배포한 다양한 채팅, 임베딩 및 리랭커 모델을 활용할 수 있습니다.
다음은 GPUStack 기능에 대한 간략한 설명입니다.
GPUStack 기능
- 이기종 GPU 지원: 이기종 GPU 리소스 지원, 현재 Nvidia, Apple Metal, Huawei Rise 및 무어 스레드 및 기타 유형의 GPU/NPU를 지원합니다.
- 다중 추론 백엔드 지원: 프로덕션 성능과 멀티플랫폼 호환성 요구 사항을 모두 고려하여 vLLM 및 llama-box(llama.cpp) 추론 백엔드가 지원됩니다.
- 멀티 플랫폼 지원: Linux, Windows 및 macOS 플랫폼을 지원하며, amd64 및 arm64 아키텍처를 모두 포괄합니다.
- 다중 모델 유형 지원: LLM 텍스트 모델, VLM 멀티모달 모델, 임베딩 텍스트 임베딩 모델, 리랭커 재주문 모델 등 다양한 유형의 모델을 지원합니다.
- 다중 모델 저장소 지원: HuggingFace, Ollama 라이브러리, ModelScope 및 비공개 모델 저장소의 모델 배포를 지원합니다.
- 다양한 자동/수동 스케줄링 정책: 압축 스케줄링, 분산 스케줄링, 지정된 작업자 태그 스케줄링, 지정된 GPU 스케줄링 등 다양한 스케줄링 정책을 지원합니다.
- 분산 추론: 단일 GPU로 대규모 모델을 실행할 수 없는 경우, GPUStack의 분산 추론 기능을 사용하여 여러 호스트의 여러 GPU에서 모델을 자동으로 실행할 수 있습니다.
- CPU 추론: GPU가 없거나 GPU 리소스가 부족한 경우, GPUStack은 CPU 리소스를 사용하여 대규모 모델을 실행할 수 있으며, GPU&CPU 하이브리드 추론과 순수 CPU 추론의 두 가지 CPU 추론 모드를 지원합니다.
- 다중 모델 비교: GPUStack in 놀이터 여러 모델의 Q&A 콘텐츠와 성능 데이터를 동시에 비교하여 다양한 모델, 다양한 가중치, 다양한 프롬프트 파라미터, 다양한 양자화, 다양한 GPU, 다양한 추론 백엔드의 모델 제공 효과를 평가할 수 있는 다중 모델 비교 보기가 제공됩니다.
- GPU 및 LLM 옵저버블: 포괄적인 성능, 활용도, 상태 모니터링 및 사용 데이터 메트릭을 제공하여 GPU 및 LLM 활용도를 평가합니다.
GPUStack은 프라이빗 대규모 서비스형 모델 플랫폼을 구축하는 데 필요한 모든 엔터프라이즈급 기능을 제공합니다. 오픈 소스 프로젝트이므로 설치와 설정이 매우 간단하여 즉시 프라이빗 대규모 서비스형 모델 플랫폼을 구축할 수 있습니다.
요약
위는 Dify를 사용하여 GPUStack을 설치하고 GPUStack 모델을 통합하기 위한 구성 자습서이며, 프로젝트의 오픈 소스 주소는 https://github.com/gpustack/gpustack 입니다.
장벽이 낮고 사용하기 쉬우며 즉시 사용 가능한 GPUStack오픈 소스 플랫폼이를 통해 기업은 이기종 GPU 리소스를 빠르게 통합 및 활용하고 단기간에 엔터프라이즈급 프라이빗 대규모 서비스형 모델 플랫폼을 신속하게 구축할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...