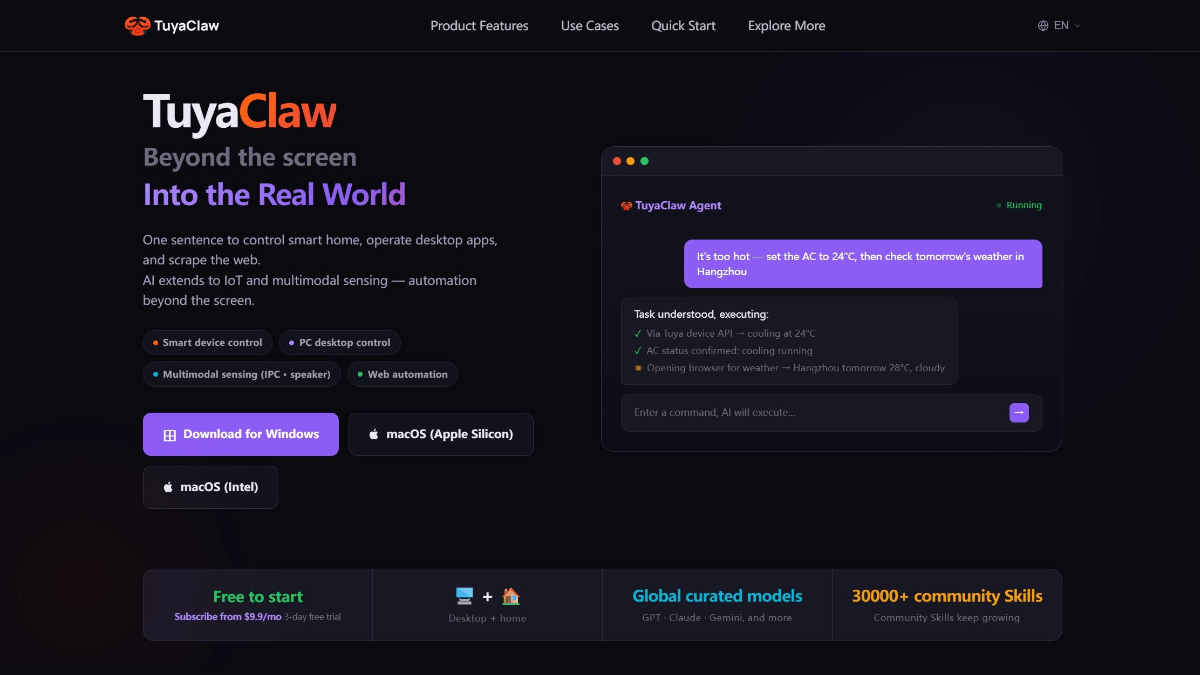

일반 소개
셰르파-onnx는 효율적인 오프라인 음성 인식 및 음성 합성 솔루션을 제공하기 위해 차세대 칼디 팀이 개발한 오픈 소스 프로젝트입니다. 안드로이드, iOS, 라즈베리파이 등 다양한 플랫폼을 지원하며 인터넷 연결 없이도 실시간 음성 처리가 가능합니다. 이 프로젝트는 ONNX 런타임 프레임워크를 기반으로 하며 다양한 임베디드 시스템과 모바일 기기를 위한 음성-텍스트 변환(ASR), 텍스트 음성 변환(TTS), 음성 활동 감지(VAD) 등의 기능을 제공합니다. 이 프로젝트는 오프라인 사용을 지원할 뿐만 아니라 WebSocket을 통한 서버와 클라이언트 통신도 지원합니다.

온라인 데모: https://huggingface.co/spaces/k2-fsa/generate-subtitles-for-videos
기능 목록
- 오프라인 음성 인식(ASR)인터넷 연결 없이도 여러 언어로 실시간 음성-텍스트 변환을 지원합니다.
- 오프라인 음성 합성(TTS)인터넷 없이도 고품질 텍스트 음성 변환 서비스를 제공합니다.
- 음성 활동 감지(VAD)다양한 음성 상호 작용 시나리오에 적합한 음성 활동의 실시간 감지.
- 멀티 플랫폼 지원Linux, macOS, Windows, Android, iOS 및 기타 여러 운영 체제에서 사용할 수 있습니다.
- 다국어 모델 지원인식 및 합성의 정확도를 높이기 위해 Zipformer, Paraformer 등과 같은 고급 음성 모델을 지원합니다.
- 낮은 리소스 소비최적화된 모델은 리소스가 제한된 기기에서 원활하게 실행될 수 있습니다.
도움말 사용
설치 프로세스
셰르파-onnx는 오픈 소스 프로젝트이므로 GitHub에서 소스 코드를 직접 다운로드하여 컴파일하거나 미리 컴파일된 바이너리를 바로 사용할 수 있습니다:
1.클론 창고::
git clone https://github.com/k2-fsa/sherpa-onnx.git
cd sherpa-onnx
- 소스 코드 컴파일::
- Linux 및 macOS 사용자의 경우:
mkdir build cd build cmake -DCMAKE_BUILD_TYPE=Release .. make -j4 - Windows 사용자의 경우 Visual Studio 또는 CMake에서 지원하는 다른 컴파일러를 사용해야 할 수 있습니다.
- Linux 및 macOS 사용자의 경우:
- 미리 컴파일된 파일 다운로드::
- GitHub 릴리스 페이지(예: https://github.com/k2-fsa/sherpa-onnx/releases)를 방문하여 운영 체제에 맞게 미리 컴파일된 버전을 선택하여 다운로드하세요.
사용법
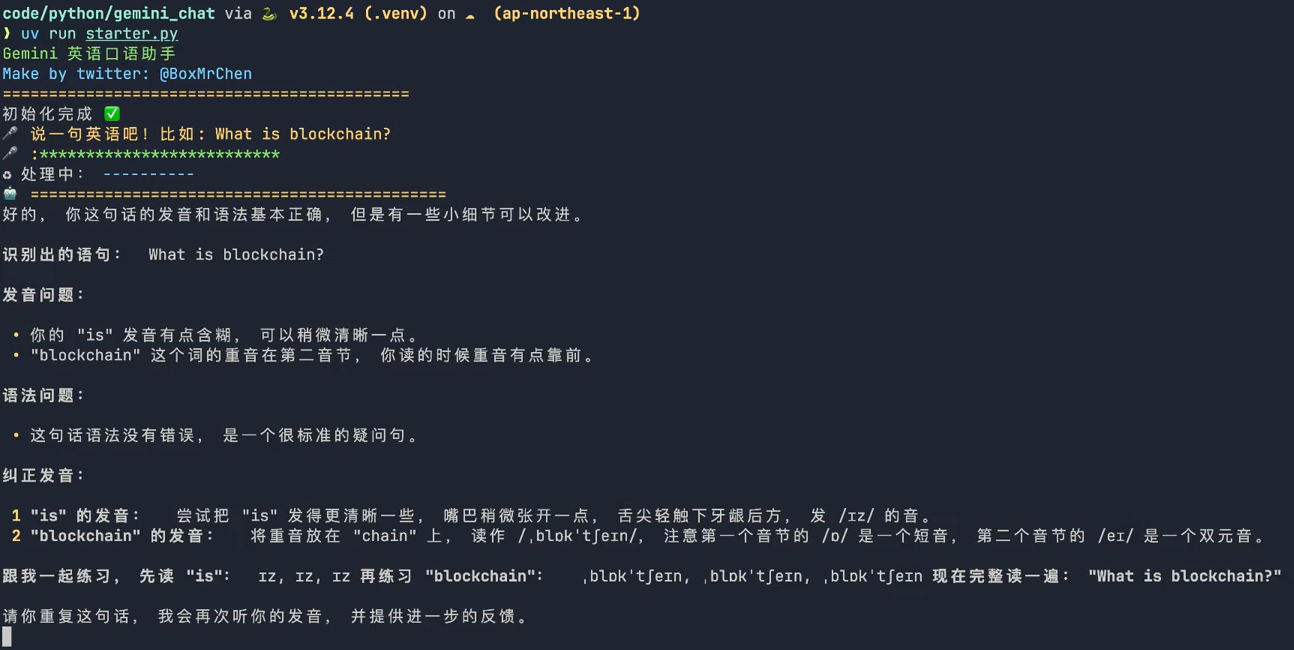
음성 인식(ASR) 예시::
- 명령줄 모드::
사전 학습된 모델 다운로드(예 셰르파-온넥스-스트리밍-집포머-이중언어-ZH-EN):wget https://github.com/k2-fsa/sherpa-onnx/releases/download/asr-models/sherpa-onnx-streaming-zipformer-bilingual-zh-en.tar.bz2 tar xvf sherpa-onnx-streaming-zipformer-bilingual-zh-en.tar.bz2그런 다음 실행합니다:
./build/bin/sherpa-onnx --tokens=sherpa-onnx-streaming-zipformer-bilingual-zh-en/tokens.txt --encoder=sherpa-onnx-streaming-zipformer-bilingual-zh-en/encoder.onnx --decoder=sherpa-onnx-streaming-zipformer-bilingual-zh-en/decoder.onnx your_audio.wav - 실시간 인식::
마이크를 사용한 실시간 음성 인식:./build/bin/sherpa-onnx-microphone --tokens=sherpa-onnx-streaming-zipformer-bilingual-zh-en/tokens.txt --encoder=sherpa-onnx-streaming-zipformer-bilingual-zh-en/encoder.onnx --decoder=sherpa-onnx-streaming-zipformer-bilingual-zh-en/decoder.onnx
음성 합성(TTS) 예제::
- 사전 학습된 TTS 모델(예: VITS 모델)을 다운로드합니다:
wget https://github.com/k2-fsa/sherpa-onnx/releases/download/tts-models/sherpa-onnx-tts-vits.tar.bz2 tar xvf sherpa-onnx-tts-vits.tar.bz2 - TTS를 실행합니다:
./build/bin/sherpa-onnx-offline-tts --model=sherpa-onnx-tts-vits/model.onnx "你好,世界"
음성 활동 감지(VAD)::
- VAD를 실행합니다:
./build/bin/sherpa-onnx-vad --model=path/to/vad_model.onnx your_audio.wav
주의
- 모델 선택필요에 따라 적절한 모델(예: 스트리밍 또는 비스트리밍 버전)을 선택하세요. 모델마다 성능과 실시간성이 다릅니다.
- 하드웨어 요구 사항셰르파-onnx는 리소스 소비가 적도록 설계되었지만 복잡한 모델에는 특히 모바일 디바이스에서 더 높은 연산 능력이 필요할 수 있습니다.
- 언어 지원사전 학습된 모델은 여러 언어를 지원할 수 있으므로 사용 중인 언어에 맞는 모델을 선택해야 합니다.
이러한 단계와 팁을 통해 실시간 대화 시스템이나 오프라인 음성 처리 등 음성 관련 애플리케이션 개발에 셰르파-온넥스를 사용할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...