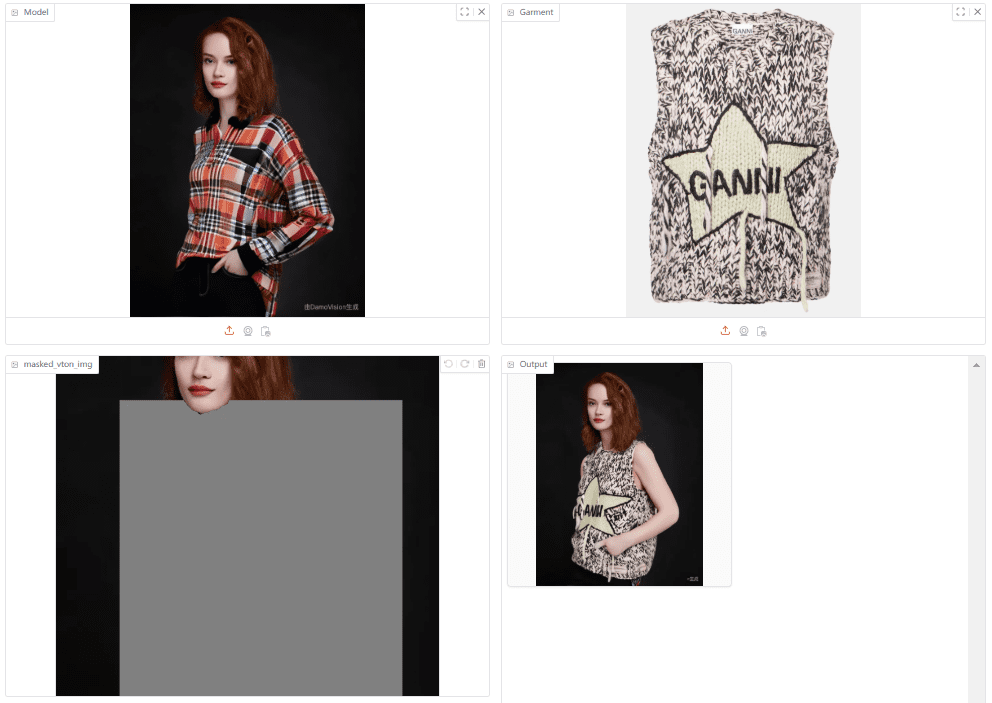

일반 소개
세그애니모는 UC 버클리와 북경대학교의 연구팀이 개발한 오픈 소스 프로젝트로, 난 황을 비롯한 여러 연구원이 참여하고 있습니다. 이 도구는 동영상 처리에 중점을 두고 있으며 동영상에서 사람, 동물 또는 차량과 같이 움직이는 임의의 물체를 자동으로 식별하고 분할할 수 있습니다. 이 도구는 TAPNet, DINOv2, SAM2와 같은 기술을 결합하여 CVPR 2025에서 결과를 발표할 계획입니다. 프로젝트 코드는 완전히 공개되어 사용자가 무료로 다운로드, 사용 또는 수정할 수 있으며 개발자, 연구자 및 비디오 처리 애호가에게 적합하며 SegAnyMo의 목표는 움직이는 비디오의 분석을 단순화하고 효율적인 세그먼트 분할 솔루션을 제공하는 것입니다.

기능 목록
- 동영상에서 움직이는 물체를 자동으로 감지하고 정확한 분할 마스크를 생성합니다.
- 동영상 형식(예: MP4, AVI) 또는 이미지 시퀀스 입력을 지원합니다.
- 신속한 배포 및 테스트를 지원하기 위해 사전 학습된 모델을 제공합니다.
- 탭넷과 통합하면 2D 트래킹 트레이스를 생성하고 모션 정보를 캡처할 수 있습니다.
- 세분화 정확도를 높이기 위해 의미론적 특징을 추출하는 데 DINOv2를 사용합니다.
- SAM2 세분화 마스크를 사용한 픽셀 수준 세분화.
- 다양한 시나리오에 적응할 수 있도록 맞춤형 데이터 세트 교육을 지원합니다.
- 시각화된 결과를 출력하여 쉽게 확인하고 조정할 수 있습니다.
도움말 사용
세그애니모는 특정 기술 기반이 필요하며 주로 프로그래밍 경험이 있는 사용자를 대상으로 합니다. 아래는 자세한 설치 및 사용 가이드입니다.
설치 프로세스
- 하드웨어 및 소프트웨어 준비
이 프로젝트는 우분투 22.04에서 개발 중이며 NVIDIA RTX A6000 또는 유사한 CUDA 지원 그래픽 카드가 권장됩니다. Git 및 Anaconda가 사전 설치되어 있어야 합니다.- 코드 리포지토리를 복제합니다:
git clone --recurse-submodules https://github.com/nnanhuang/SegAnyMo - 프로젝트 카탈로그로 이동합니다:
cd SegAnyMo
- 코드 리포지토리를 복제합니다:
- 가상 환경 만들기
종속성 충돌을 피하기 위해 Anaconda로 별도의 Python 환경을 만드세요.- 환경 만들기:
conda create -n seg python=3.12.4 - 환경을 활성화합니다:
conda activate seg
- 환경 만들기:
- 핵심 종속성 설치
PyTorch 및 기타 필요한 라이브러리를 설치합니다.- PyTorch를 설치합니다(CUDA 12.1 지원):
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia - 다른 종속성을 설치합니다:
pip install -r requirements.txt - 엑스포머(가속 추론)를 설치합니다:
pip install -U xformers --index-url https://download.pytorch.org/whl/cu121
- PyTorch를 설치합니다(CUDA 12.1 지원):
- DINOv2 설치
DINOv2는 특징 추출에 사용됩니다.- 전처리 카탈로그로 이동하여 복제합니다:
cd preproc && git clone https://github.com/facebookresearch/dinov2
- 전처리 카탈로그로 이동하여 복제합니다:
- SAM2 설치
SAM2는 마스크 정제 코어입니다.- SAM2 카탈로그로 이동합니다:
cd sam2 - 설치:
pip install -e . - 사전 학습된 모델을 다운로드하세요:
cd checkpoints && ./download_ckpts.sh && cd ../..
- SAM2 카탈로그로 이동합니다:
- TAPNet 설치
TAPNet은 2D 추적 추적을 생성하는 데 사용됩니다.- TAPNet 카탈로그로 이동합니다:
cd preproc/tapnet - 설치:
pip install . - 모델을 다운로드하세요:
cd ../checkpoints && wget https://storage.googleapis.com/dm-tapnet/bootstap/bootstapir_checkpoint_v2.pt
- TAPNet 카탈로그로 이동합니다:
- 설치 확인
환경이 정상인지 확인합니다:
python -c "import torch; print(torch.cuda.is_available())"
수출 True 성공을 나타냅니다.
사용법
데이터 준비
세그애니모는 비디오 또는 이미지 시퀀스 입력을 지원합니다. 데이터는 다음과 같은 구조로 정리해야 합니다:
data
├── images
│ ├── scene_name
│ │ ├── image_name
│ │ ├── ...
├── bootstapir
│ ├── scene_name
│ │ ├── image_name
│ │ ├── ...
├── dinos
│ ├── scene_name
│ │ ├── image_name
│ │ ├── ...
├── depth_anything_v2
│ ├── scene_name
│ │ ├── image_name
│ │ ├── ...
- 입력이 비디오인 경우 도구(예: FFmpeg)를 사용하여 프레임을 추출하여
images폴더. - 이미지 시퀀스인 경우 해당 디렉토리에 직접 넣습니다.
운영 전처리
- 심도 맵, 피처 및 궤적 생성하기
다음 명령을 사용하여 데이터를 처리합니다(데이터 양에 따라 약 10분 정도 소요):- 이미지 시퀀스의 경우:
python core/utils/run_inference.py --data_dir $DATA_DIR --gpus 0 --depths --tracks --dinos --e - 비디오의 경우:
python core/utils/run_inference.py --video_path $VIDEO_PATH --gpus 0 --depths --tracks --dinos --e
매개변수 설명:
--e효율 모드를 활성화하면 프레임 속도와 해상도를 낮추고 처리 속도를 높일 수 있습니다.--step 1010프레임 중 1프레임이 쿼리 프레임으로 사용됨을 나타내며, 정확도를 높이기 위해 아래쪽으로 조정할 수 있습니다.
- 이미지 시퀀스의 경우:
모션 궤적 예측
- 모델 가중치 다운로드
통해 (틈새) 포옹하는 얼굴 어쩌면 Google 드라이브 사전 학습된 모델을 다운로드합니다. 경로를configs/example_train.yaml(명목식 형태로 사용됨)resume_path필드.- 달리기 궤적 예측:
python core/utils/run_inference.py --data_dir $DATA_DIR --motin_seg_dir $OUTPUT_DIR --config_file configs/example_train.yaml --gpus 0 --motion_seg_infer --e
출력은
$OUTPUT_DIR. - 달리기 궤적 예측:
세분화 마스크 생성
- SAM2 리파이닝 마스크 사용
- 마스크 생성을 실행합니다:
python core/utils/run_inference.py --data_dir $DATA_DIR --sam2dir $RESULT_DIR --motin_seg_dir $OUTPUT_DIR --gpus 0 --sam2 --e
매개변수 설명:
$DATA_DIR는 원본 이미지 경로입니다.$RESULT_DIR는 마스크 저장 경로입니다.$OUTPUT_DIR는 궤적 예측 결과 경로입니다.
참고: SAM2는 기본적으로 다음과 같이 지원합니다..jpg어쩌면.jpeg형식을 사용하는 경우 파일 이름은 일반 숫자여야 합니다. 일치하지 않는 경우 코드를 변경하거나 파일 이름을 바꿀 수 있습니다.
- 마스크 생성을 실행합니다:
평가 결과
- 미리 계산된 결과 다운로드
엔티티 이전 Google 드라이브 비교를 위해 공식 마스크를 다운로드하세요.- DAVIS 데이터 세트의 평가:
CUDA_VISIBLE_DEVICES=0 python core/eval/eval_mask.py --res_dir $RES_DIR --eval_dir $GT_DIR --eval_seq_list core/utils/moving_val_sequences.txt - 정교한 평가:
cd core/eval/davis2017-evaluation && CUDA_VISIBLE_DEVICES=0 python evaluation_method.py --task unsupervised --results_path $MASK_PATH
- DAVIS 데이터 세트의 평가:
맞춤형 교육
- 데이터 전처리
HOI4D 데이터 세트가 예시로 사용됩니다:
python core/utils/process_HOI.py
python core/utils/run_inference.py --data_dir $DATA_DIR --gpus 0 --tracks --depths --dinos
사용자 지정 데이터 세트에는 RGB 이미지와 동적 마스크가 필요합니다.
- 데이터 무결성을 확인합니다:
python current-data-dir/dynamic_stereo/dynamic_replica_data/check_process.py - 데이터를 정리하면 공간이 절약됩니다:
python core/utils/run_inference.py --data_dir $DATA_DIR --gpus 0 --clean
- 모델 교육
수정configs/$CONFIG.yaml구성, Kubric, HOI4D 등의 데이터 세트로 학습된 데이터 세트
CUDA_VISIBLE_DEVICES=0 python train_seq.py ./configs/$CONFIG.yaml
애플리케이션 시나리오
- 비디오 포스트 프로덕션
움직이는 물체(예: 달리는 사람)를 동영상에서 분리하고 마스크를 생성한 다음 효과 합성에 사용합니다. - 행동 분석 연구
동물 또는 사람의 이동 궤적을 추적하고 행동 패턴을 분석합니다. - 자율 주행 개발
주행 영상에서 움직이는 물체(예: 차량, 보행자)를 세분화하여 인식 시스템을 최적화합니다. - 시스템 최적화 모니터링
감시 영상에서 비정상적인 움직임을 추출하여 보안 효율성을 개선하세요.
QA
- GPU가 필요하신가요?
예, NVIDIA 카드는 CUDA를 지원하는 것이 좋습니다. 그렇지 않으면 비효율적으로 실행됩니다. - 실시간 처리를 지원하나요?
현재 버전은 오프라인 처리에 적합하며 실시간 애플리케이션은 자체적으로 최적화해야 합니다. - 교육에 필요한 공간은 어느 정도인가요?
데이터 집합에 따라 작은 데이터 집합은 몇 기가바이트이고 큰 데이터 집합은 수백 기가바이트일 수 있습니다. - 세분화 정확도를 높이는 방법은 무엇인가요?
감소--step값으로 설정하거나 더 많은 레이블이 지정된 데이터로 모델을 학습시킬 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서

댓글 없음...