

OpenAI가 o1 모델을 출시한 이후테스트 시간 컴퓨팅 확장(확장 추론이라는 주제는 AI 업계에서 가장 뜨거운 주제 중 하나가 되었습니다. 간단히 말해, 사전 학습이나 사후 학습 단계에서 컴퓨팅 파워를 쌓아두는 대신 추론 단계(즉, 대규모 언어 모델이 출력을 생성할 때)에 더 많은 컴퓨팅 자원을 사용하는 것이 좋습니다. o1 모델은 큰 문제를 일련의 작은 문제(즉, 연쇄 사고)로 분할하여 모델이 인간처럼 단계별로 생각하여 다양한 가능성을 평가하고, 더 자세한 계획을 세우고, 답을 제공하기 전에 스스로 성찰하는 등 모델을 사용하여 다양한 가능성을 평가하고 더 자세한 계획을 세우고 답을 제공할 수 있도록 합니다. 모델은 인간처럼 생각하고, 다양한 가능성을 평가하고, 더 자세한 계획을 세우고, 답을 내기 전에 스스로를 반성하는 등의 작업을 할 수 있습니다. 이러한 방식으로 모델을 재훈련할 필요가 없으며 추론하는 동안 추가 계산만으로 성능을 향상시킬 수 있습니다.모델에 암기 학습을 시키는 대신, 더 많은 생각을 하게 하세요.-- 이 전략은 복잡한 추론 작업에서 특히 효과적이며 결과를 크게 개선할 수 있으며, 알리바바가 최근 발표한 QwQ 모델은 추론 시 계산을 확장하여 모델 기능을 개선하는 이러한 기술 트렌드를 확인시켜 줍니다.
👩🏫 이 백서에서 확장이란 추론 과정에서 계산 리소스(예: 연산 또는 시간)를 늘리는 것을 의미합니다. 수평적 확장(분산 컴퓨팅) 또는 가속 처리(계산 시간 단축)를 의미하지 않습니다.

O1 모델을 사용해 본 적이 있다면, 다단계 추론은 문제를 해결하기 위해 생각의 사슬을 만들어야 하기 때문에 시간이 더 많이 걸린다는 것을 확실히 느낄 것입니다.
Jina AI에서는 대규모 언어 모델(LLM)보다는 임베딩과 리랭커에 더 중점을 두기 때문에 자연스레 임베딩과 리랭커를 생각하게 되었습니다:'생각의 사슬'이라는 개념을 임베딩 모델에도 적용할 수 있나요?
언뜻 보기에는 직관적이지 않을 수 있지만, 이 백서에서는 새로운 관점을 살펴보고 테스트 시간 컴퓨팅 확장 기능을 어떻게 적용할 수 있는지 설명합니다.jina-clip에 대한 이해를 돕기 위해 까다로운 도메인 외부(OOD) 이미지 분류는 다른 방법으로는 불가능한 작업을 해결하기 위해 수행됩니다.
벡터 모델로는 여전히 상당히 어려운 포켓몬 인식 실험을 진행했는데, CLIP과 같은 모델은 이미지와 텍스트 매칭에 강하지만 이전에 본 적이 없는 도메인 외 데이터(OOD)를 만나면 롤오버하는 경향이 있습니다.
그러나 다음과 같은 사실을 발견했습니다.모델 추론 시간을 늘리고 모델 튜닝이 필요 없는 연쇄 사고와 같은 다객관 분류 전략을 사용하면 도메인 외부 데이터의 분류 정확도를 향상시킬 수 있습니다.
사례 연구: 포켓몬 이미지 분류
🔗 Google Colab: https://colab.research.google.com/drive/1zP6FZRm2mN1pf7PsID-EtGDc5gP_hm4Z#scrollTo=CJt5zwA9E2jB
저희는 수천 개의 포켓몬 카드 이미지가 포함된 TheFusion21/PokemonCards 데이터 세트를 사용했습니다.이미지 분류 작업입니다.를 사용하여 잘린 포켓몬 덱을 입력하면 (텍스트 설명이 제거된) 올바른 포켓몬 이름을 출력할 수 있습니다. 그러나 클립 삽입 모델에서는 여러 가지 이유로 이 기능을 사용하기가 어렵습니다:
- 포켓몬의 이름과 외모는 비교적 새로운 모델이며, 직접 분류를 통해 각본을 쉽게 뒤집을 수 있습니다.
- 각 포켓몬은 고유한 시각적 특징을 가지고 있습니다.예를 들어 도형, 색상, 자세 등의 클립을 더 잘 이해할 수 있습니다.
- 하지만 카드의 스타일은 통일되어 있습니다.하지만 다양한 배경, 포즈, 그리기 스타일로 인해 난이도가 높아집니다..
- 이 작업에는 다음이 필요합니다.여러 시각적 기능을 동시에 고려하세요.의 복잡한 생각의 사슬처럼 말입니다.

앱솔, 에어로닥틸과 같은 포켓몬의 라벨이 이름이기 때문에 모델들이 속임수를 써서 텍스트에서 직접 답을 찾을 수 없도록 카드에서 모든 텍스트 정보(제목, 바닥글, 설명)를 제거했습니다.
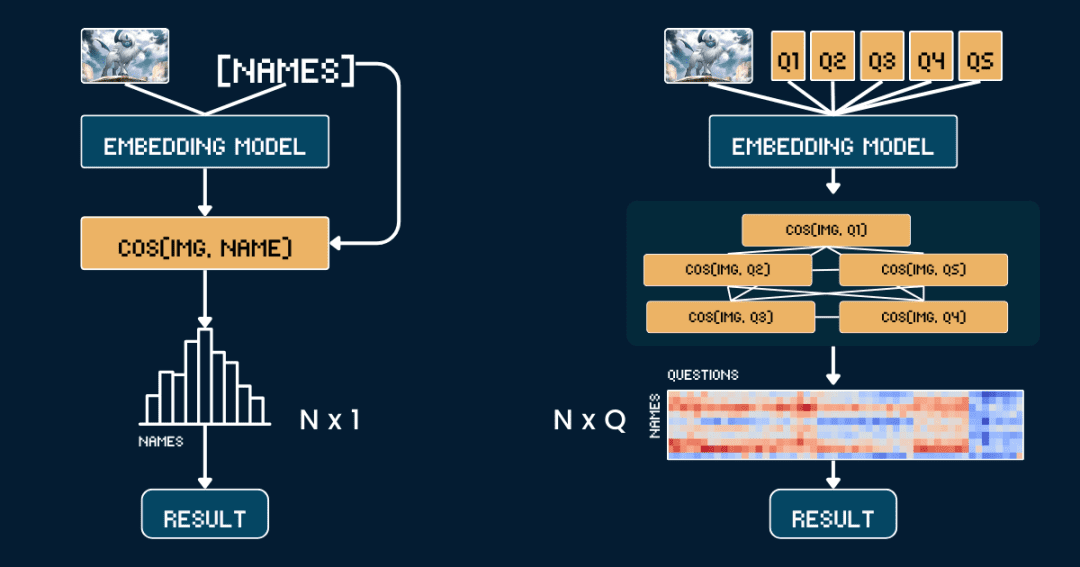
기준 방법론: 직접 유사도 비교
가장 간단한 기본 방법론인 포켓몬 사진과 이름 간의 유사성 직접 비교.
먼저 카드에서 모든 텍스트 정보를 제거하여 CLIP 모델이 텍스트에서 직접 답을 추측할 필요가 없도록 하는 것이 좋습니다. 그런 다음 jina-clip-v1 노래로 응답 jina-clip-v2 이 모델은 이미지와 포켓몬 이름을 별도로 인코딩하여 각각의 벡터 표현을 얻습니다. 마지막으로 이미지 벡터와 텍스트 벡터 사이의 코사인 유사도를 계산하여 유사도가 가장 높은 이름이 해당 그림의 포켓몬으로 간주합니다.
이 접근 방식은 다른 문맥 정보나 속성을 고려하지 않고 이미지와 이름을 일대일로 일치시키는 것과 동일합니다. 다음 의사 코드는 이 과정을 간략하게 설명합니다.
# 预处理 cropped_images = [crop_artwork(img) for img in pokemon_cards] # 去掉文字,只保留图片 pokemon_names = ["Absol", "Aerodactyl", ...] # 宝可梦名字# 用 jina-clip-v1 获取 embeddings image_embeddings = model.encode_image(cropped_images) text_embeddings = model.encode_text(pokemon_names) # 计算余弦相似度进行分类 similarities = cosine_similarity(image_embeddings, text_embeddings) predicted_names = [pokemon_names[argmax(sim)] for sim in similarities] # 哪个名字相似度最高,就选哪个 # 评估准确率 accuracy = mean(predicted_names == ground_truth_names)
고급: 이미지 분류에 생각의 사슬 적용하기
이번에는 사진과 이름을 직접 맞추는 방식이 아닌 '포켓몬 커넥트'를 하듯 포켓몬 식별을 여러 부분으로 나누었습니다.
기본 색상(예: "흰색", "파란색"), 기본 형태(예: "늑대", "날개 달린 파충류"), 주요 특징(예: "흰 뿔", "큰 날개"), 몸 크기(예: "네발 달린 늑대 형태"), 주요 특성(예: "네 발 달린 늑대 형태 날개 달린 파충류"), 주요 특징(예: "흰 뿔", "큰 날개"), 몸 크기(예: "네 발 달린 늑대 형태 ", "날개가 있고 날씬한"), 배경 장면(예: "우주 공간", "녹색 숲").
각 속성 세트에 대해 "이 포켓몬의 몸은 주로 {}색입니다"와 같은 특별한 단서 단어를 디자인한 다음 가능한 옵션을 채웠습니다.그런 다음 모델을 사용하여 이미지와 각 옵션의 유사도 점수를 계산하고, 모델의 신뢰도를 더 잘 측정할 수 있는 소프트맥스 함수를 사용하여 점수를 확률로 변환합니다.
완전한 생각의 사슬(CoT)은 두 부분으로 구성됩니다:classification_groups 노래로 응답 pokemon_rules전자는 질문의 틀을 정의합니다. 각 속성(예: 색상, 형태)은 질문 템플릿과 가능한 답변 옵션 세트에 해당합니다. 후자는 각 포켓몬에 대해 어떤 옵션이 일치해야 하는지를 기록합니다.
예를 들어, 앱솔의 색은 "흰색"이고 형태는 "늑대"여야 합니다. 나중에 완전한 CoT 구조를 구축하는 방법에 대해 설명할 것이며, 아래의 pokemon_system은 CoT의 구체적인 예시입니다:
pokemon_system = {
"classification_cot": {
"dominant_color": {
"prompt": "This Pokémon's body is mainly {} in color.",
"options": [
"white", # Absol, Absol G
"gray", # Aggron
"brown", # Aerodactyl, Weedle, Beedrill δ
"blue", # Azumarill
"green", # Bulbasaur, Venusaur, Celebi&Venu, Caterpie
"yellow", # Alakazam, Ampharos
"red", # Blaine's Moltres
"orange", # Arcanine
"light blue"# Dratini
]
},
"primary_form": {
"prompt": "It looks like {}.",
"options": [
"a wolf", # Absol, Absol G
"an armored dinosaur", # Aggron
"a winged reptile", # Aerodactyl
"a rabbit-like creature", # Azumarill
"a toad-like creature", # Bulbasaur, Venusaur, Celebi&Venu
"a caterpillar larva", # Weedle, Caterpie
"a wasp-like insect", # Beedrill δ
"a fox-like humanoid", # Alakazam
"a sheep-like biped", # Ampharos
"a dog-like beast", # Arcanine
"a flaming bird", # Blaine's Moltres
"a serpentine dragon" # Dratini
]
},
"key_trait": {
"prompt": "Its most notable feature is {}.",
"options": [
"a single white horn", # Absol, Absol G
"metal armor plates", # Aggron
"large wings", # Aerodactyl, Beedrill δ
"rabbit ears", # Azumarill
"a green plant bulb", # Bulbasaur, Venusaur, Celebi&Venu
"a small red spike", # Weedle
"big green eyes", # Caterpie
"a mustache and spoons", # Alakazam
"a glowing tail orb", # Ampharos
"a fiery mane", # Arcanine
"flaming wings", # Blaine's Moltres
"a tiny white horn on head" # Dratini
]
},
"body_shape": {
"prompt": "The body shape can be described as {}.",
"options": [
"wolf-like on four legs", # Absol, Absol G
"bulky and armored", # Aggron
"winged and slender", # Aerodactyl, Beedrill δ
"round and plump", # Azumarill
"sturdy and four-legged", # Bulbasaur, Venusaur, Celebi&Venu
"long and worm-like", # Weedle, Caterpie
"upright and humanoid", # Alakazam, Ampharos
"furry and canine", # Arcanine
"bird-like with flames", # Blaine's Moltres
"serpentine" # Dratini
]
},
"background_scene": {
"prompt": "The background looks like {}.",
"options": [
"outer space", # Absol G, Beedrill δ
"green forest", # Azumarill, Bulbasaur, Venusaur, Weedle, Caterpie, Celebi&Venu
"a rocky battlefield", # Absol, Aggron, Aerodactyl
"a purple psychic room", # Alakazam
"a sunny field", # Ampharos
"volcanic ground", # Arcanine
"a red sky with embers", # Blaine's Moltres
"a calm blue lake" # Dratini
]
}
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 2
},
"Absol G": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 0
},
// ...
}
}
즉, 단순히 유사성을 한 번만 비교하는 대신 각 속성의 확률을 결합하여 여러 번 비교함으로써 보다 합리적인 판단을 내릴 수 있게 된 것입니다.
# 分类流程
def classify_pokemon(image):
# 生成所有提示
all_prompts = []
for group in classification_cot:
for option in group["options"]:
prompt = group["prompt"].format(option)
all_prompts.append(prompt)
# 获取向量及其相似度
image_embedding = model.encode_image(image)
text_embeddings = model.encode_text(all_prompts)
similarities = cosine_similarity(image_embedding, text_embeddings)
# 将相似度转换为每个属性组的概率
probabilities = {}
for group_name, group_sims in group_similarities:
probabilities[group_name] = softmax(group_sims)
# 根据匹配的属性计算每个宝可梦的得分
scores = {}
for pokemon, rules in pokemon_rules.items():
score = 0
for group, target_idx in rules.items():
score += probabilities[group][target_idx]
scores[pokemon] = score
return max(scores, key=scores.get) # 返回得分最高的宝可梦
두 가지 방법의 복잡성 분석
이제 N개의 포켓몬 이름 중에서 주어진 이미지와 가장 일치하는 이름을 찾고 싶다고 가정하고 복잡성을 분석해 보겠습니다:
기준 방법은 N개의 텍스트 벡터(각 이름당 하나씩)와 1개의 이미지 벡터를 계산한 다음 N개의 유사도 계산(이미지 벡터를 각 텍스트 벡터와 비교)을 수행해야 합니다.따라서 벤치마크 방법의 복잡성은 주로 텍스트 벡터의 계산 횟수 N에 따라 달라집니다.
대신 CoT 방법에서는 모든 문제-옵션 조합의 총 개수인 Q 텍스트 벡터와 1개의 그림 벡터를 계산해야 합니다. 그런 다음 Q 유사도 계산(각 문제-옵션 조합에 대한 그림 벡터와 텍스트 벡터의 비교)을 수행해야 합니다.따라서 방법의 복잡성은 주로 Q에 따라 달라집니다.
이 예에서는 N = 13, Q = 52(그룹당 평균 약 10개의 옵션이 있는 5개 속성 그룹)입니다. 두 방법 모두 이미지 벡터를 계산하고 분류 단계를 수행해야 하므로 비교에서 이러한 공통 작업을 반올림합니다.
극단적인 경우, Q = N이 되면 우리의 방법은 사실상 벤치마크 방법으로 전락합니다. 따라서 추론 시간 계산을 효과적으로 확장하는 것이 관건입니다:
Q의 값을 높이도록 문제를 설계합니다. 각 질문이 질문의 범위를 좁히는 데 도움이 되는 유용한 단서를 제공하는지 확인하세요. 정보 획득을 극대화하려면 질문 간에 중복되는 정보가 없도록 하는 것이 가장 좋습니다.
결과
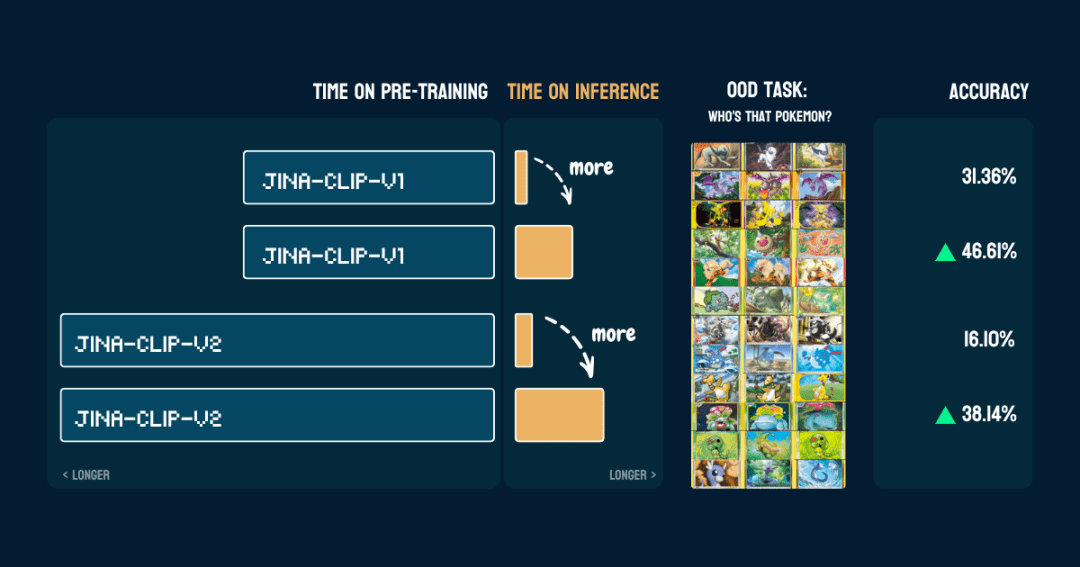
13가지 포켓몬이 포함된 117개의 테스트 이미지로 평가했습니다. 정확도 결과는 다음과 같습니다:

또한 한 번pokemon_system제대로 구축되었습니다.코드를 변경하거나 미세 조정 또는 추가 교육 없이도 동일한 CoT를 다른 모델에서 바로 사용할 수 있습니다.
흥미롭군요.jina-clip-v1이 모델의 포켓몬 분류에 대한 기본 정확도는 포켓몬 데이터가 포함된 LAION-400M 데이터 세트에서 학습되었기 때문에 더 높습니다(31.36%). 반면 jina-clip-v2이 모델은 더 높은 품질의 데이터 세트인 DFN-2B로 훈련되었지만, 더 많은 데이터를 필터링하고 포켓몬 관련 콘텐츠도 제거했을 가능성이 있으므로 기본 정확도(16.10%)가 낮습니다.
잠깐만요, 이 방법은 어떻게 작동하나요?
👩🏫 우리가 한 일을 검토해 보겠습니다.
처음에는 사전 학습된 고정 벡터 모델로 시작했는데, 샘플이 0인 분포 불일치(OOD) 문제를 처리할 수 없었습니다. 하지만 분류 트리를 구축하자 갑자기 이를 처리할 수 있게 되었습니다. 그 비결은 무엇일까요? 기존 머신 러닝의 약한 학습자 통합과 관련된 것일까요? 벡터 모델이 '불량'에서 '양호'로 업그레이드될 수 있는 것은 통합 학습 그 자체가 아니라 분류 트리에 포함된 외부 도메인 지식 때문이라는 점에 주목할 필요가 있습니다. 샘플 없이 수천 개의 질문을 반복적으로 분류할 수 있지만, 그 답변이 최종 결과에 기여하지 못하면 의미가 없습니다. 마치 20개의 질문으로 구성된 "네가 말해봐, 내 생각엔" 게임처럼, 각 질문마다 점진적으로 답을 좁혀가야 합니다. 따라서 중요한 것은 이러한 외부 지식 또는 사고 과정입니다.- 예시에서와 마찬가지로 핵심은 포켓몬 시스템을 어떻게 구축하는지에 있습니다.이러한 전문 지식은 사람이나 대규모 언어 모델에서 얻을 수 있습니다.
pokemon_system품질.수동에서 완전 자동에 이르기까지 다양한 방법으로 이 CoT 시스템을 구축할 수 있으며, 각 시스템에는 고유한 장단점이 있습니다.1. 수동 구성
2. LLM 지원 건설
我需要一个宝可梦分类系统。对于以下宝可梦:[Absol, Aerodactyl, Weedle, Caterpie, Azumarill, ...],创建一个包含以下内容的分类系统:
1. 基于以下视觉属性的分类组:
- 宝可梦的主要颜色
- 宝可梦的形态
- 宝可梦最显著的特征
- 宝可梦的整体体型
- 宝可梦通常出现的背景环境
2. 对于每个分类组:
- 创建一个自然语言提示模板,用 "{}" 表示选项
- 列出所有可能的选项
- 确保选项互斥且全面
3. 创建规则,将每个宝可梦映射到每个属性组中的一个选项,使用索引引用选项
请以 Python 字典格式输出,包含两个主要部分:
- "classification_groups": 包含每个属性的提示和选项
- "pokemon_rules": 将每个宝可梦映射到其对应的属性索引
示例格式:
{
"classification_groups": {
"dominant_color": {
"prompt": "This Pokemon's body is mainly {} in color.",
"options": ["white", "gray", ...]
},
...
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0, # "white" 的索引
...
},
...
}
}
LLM은 초안을 빠르게 생성하지만 수작업으로 확인하고 수정해야 합니다.
보다 안정적인 접근 방식은 다음과 같습니다. LLM 생성 및 수동 유효성 검사 결합. LLM은 먼저 초기 버전을 생성한 다음 속성 그룹, 옵션 및 규칙을 수동으로 확인하고 수정한 다음 수정 사항을 다시 LLM에 피드백하여 만족할 때까지 계속 다듬도록 합니다. 이 접근 방식은 효율성과 정확성의 균형을 유지합니다.
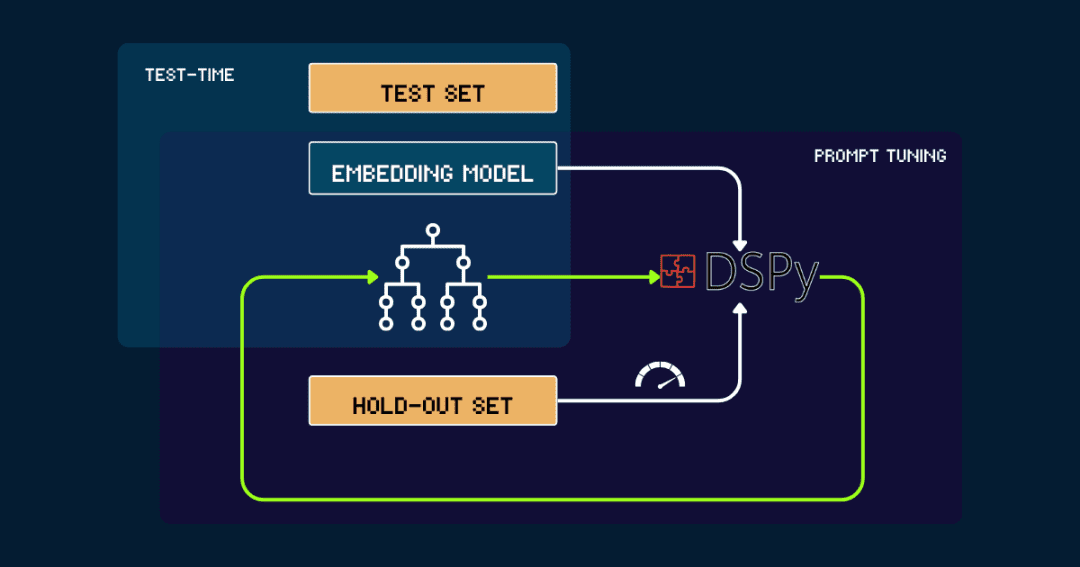
3. DSPy로 자동 빌드하기
완전 자동화된 빌드의 경우 pokemon_system를 사용하여 반복적으로 최적화할 수 있습니다.
간단한 pokemon_system 시작을 수동으로 생성하거나 LLM에서 생성합니다. 그런 다음 제외 세트의 데이터로 평가하여 정확도를 DSPy에 피드백으로 표시하고, DSPy는 이 피드백을 사용하여 새로운 pokemon_system이 사이클을 반복하여 성능이 수렴하고 더 이상 큰 개선이 없을 때까지 반복합니다.
벡터 모델은 프로세스 전반에 걸쳐 고정됩니다.. DSPy를 사용하면 최적의 포켓몬 시스템(CoT) 디자인을 자동으로 찾을 수 있으며, 작업당 한 번만 조정하면 됩니다.
벡터 모델에서 테스트 시간 계산을 확장하는 이유는 무엇인가요?
사전 학습된 모델의 크기를 항상 늘리는 데 드는 비용 때문에 휴대하기에는 너무 비쌉니다.
지나 임베딩 컬렉션, 에서jina-embeddings-v1및v2및v3 (시간)까지 jina-clip-v1및v2그리고 jina-ColBERT-v1및v2업그레이드할 때마다 더 큰 모델과 더 많은 사전 학습된 데이터, 그리고 비용 증가에 의존하게 됩니다.
takejina-embeddings-v11억 1천만 개의 매개변수가 포함된 2023년 6월 릴리스의 경우 교육 비용은 5,000~10,000달러입니다. 그때까지 jina-embeddings-v3성능은 많이 향상되었지만 여전히 주로 리소스에 돈을 투입하는 방식입니다. 이제 최고 모델의 훈련 비용은 수천 달러에서 수만 달러로 증가했으며 대기업은 수억 달러를 지출해야 합니다. 사전 교육에 더 많은 투자를 할수록 모델 결과는 더 좋아지지만 비용이 너무 높고 비용 효율성이 점점 낮아지고 있으며 궁극적으로 지속 가능성을 고려해야 할 필요성이 있습니다.
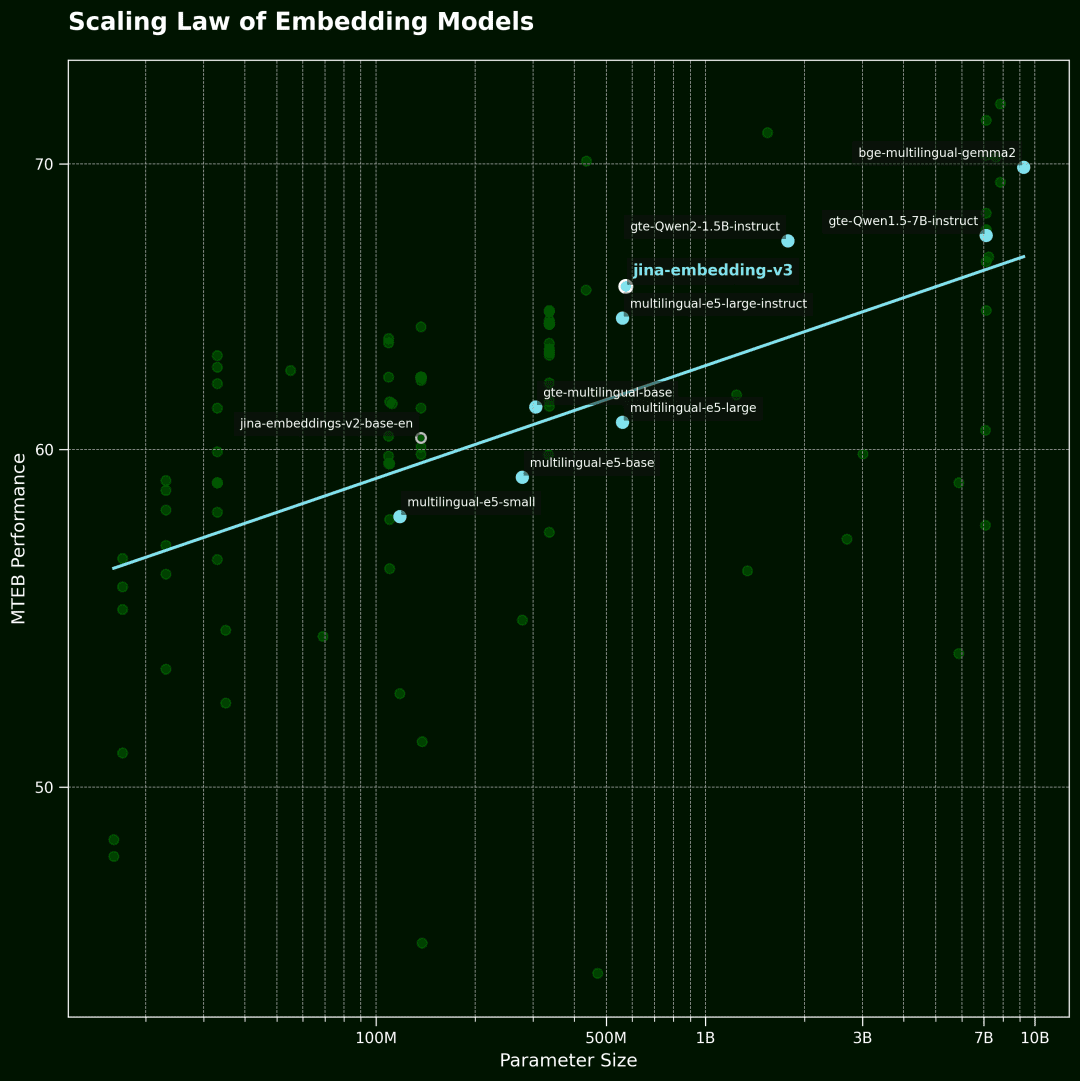
벡터 모델링 스케일링 법칙
이 그림은 벡터 모델의 Sc알링 법칙.가로축은 모델 파라미터의 수이고 세로축은 MTEB의 평균 성능입니다. 각 점은 벡터 모델을 나타냅니다. 추세선은 모든 모델의 평균을 나타내며 파란색 점은 다국어 모델입니다.
데이터는 MTEB 순위에서 상위 100개 벡터 모델 중에서 선택되었습니다. 데이터의 품질을 보장하기 위해 모델 크기 정보를 공개하지 않은 모델과 일부 유효하지 않은 제출물을 필터링했습니다.
반면에 벡터 모델은 이제 다국어, 멀티태스킹, 멀티모달, 제로 샘플 학습 및 명령어 추종 기능이 뛰어난 매우 강력한 모델입니다.이러한 다재다능함은 추론 시 알고리즘을 개선하고 계산을 확장할 수 있는 상상력이 풍부한 가능성을 열어줍니다.
핵심 질문은 다음과 같습니다:사용자가 정말로 관심 있는 쿼리에 대해 지불할 의향이 있는 금액? 미리 학습된 고정된 모델을 추론하는 데 시간이 조금 더 걸리는 것만으로도 결과의 품질이 크게 향상될 수 있다면 많은 사람들이 그만한 가치가 있다고 생각할 것입니다.
저희의 의견입니다.확장된 추론 시간 계산은 벡터 모델링 분야에서 아직 개발되지 않은 큰 잠재력을 가지고 있습니다.는 향후 연구에 중요한 돌파구가 될 것입니다.더 큰 모델을 목표로 하는 대신 추론 단계에 더 많은 노력을 기울이고 더 영리한 계산 방법을 탐색하여 성능을 개선하는 것이 좋습니다. -- 이 방법이 더 경제적이고 효율적인 방법일 수 있습니다.
평결에 도달하기
존재 jina-clip-v1/v2 실험 성능에서 다음과 같은 주요 현상을 관찰했습니다:
우리 모델에서 볼 수 없는 데이터 및 도메인 외부(OOD)에 대한 정보(수학.) 속더 나은 인식 정확도를 달성했으며 모델에 대한 미세 조정이나 추가 학습이 전혀 필요하지 않았습니다. 이 시스템은 다음을 통해 운영됩니다. 유사도 검색 및 분류 기준을 반복적으로 개선하기를 통해 더욱 세밀한 차별화 기능을 구현할 수 있습니다. 소개함으로써 동적 큐 조정 및 반복적 추론("생각의 사슬"과 유사), 벡터 모델의 추론 프로세스를 단일 쿼리에서 더 복잡한 생각의 사슬로 변환합니다.
이것은 시작에 불과합니다! 테스트 시간 컴퓨팅 확장의 잠재력은 이보다 훨씬 더 큽니다!에도 아직 탐험해야 할 방대한 공간이 있습니다. 예를 들어, '20문 20답' 게임에서 최적의 해답을 찾는 전략과 유사하게 가장 효율적인 전략을 반복적으로 선택함으로써 답의 공간을 좁히는 보다 효율적인 알고리즘을 개발할 수 있습니다. 추론 시간 계산을 확장함으로써 벡터 모델을 기존의 병목 현상을 뛰어넘어 이전에는 불가능해 보였던 복잡하고 세분화된 작업을 해결하고 이러한 모델을 더 광범위한 애플리케이션으로 확장할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서




댓글 없음...