

벡터 임베딩은 현재 검색 증강 생성(RAG) 애플리케이션의 핵심입니다. 데이터 개체(예: 텍스트, 이미지 등)에 대한 시맨틱 정보를 캡처하여 숫자 배열로 표현합니다. 현재 생성형 AI 애플리케이션에서 이러한 벡터 임베딩은 일반적으로 임베딩 모델에 의해 생성됩니다. RAG 애플리케이션에 적합한 임베딩 모델을 선택하는 방법은 무엇인가요? 전반적으로 특정 사용 사례와 특정 요구 사항에 따라 달라집니다. 이제 각 단계를 세분화하여 개별적으로 살펴보겠습니다.
01. 구체적인 사용 사례 파악
RAG 적용 요건에 따라 다음 질문을 고려합니다:
첫째, 일반 모델로 요구 사항을 충족할 수 있을까요?
둘째, 특정한 요구사항이 있나요? 예를 들어 모달리티(예: 텍스트 또는 이미지 전용, 멀티모달 임베딩 옵션의 경우적합한 임베딩 모델을 선택하는 방법"), 특정 분야(예: 법률, 의학 등)
대부분의 경우 원하는 모드에 대해 일반 모델을 선택하는 것이 일반적입니다.
02. 일반 모델 선택
범용 모델을 선택하는 방법=허깅페이스의 대규모 텍스트 임베딩 벤치마크(MTEB) 순위표에는 현재 다양한 독점 및 오픈 소스 텍스트 임베딩 모델이 나열되어 있으며, 각 임베딩 모델에 대해 모델 파라미터, 메모리 등 다양한 메트릭이 나열되어 있습니다, 임베딩 차원, 최대 토큰 수, 검색 및 요약과 같은 작업에서의 점수 등 다양한 지표를 나열합니다.
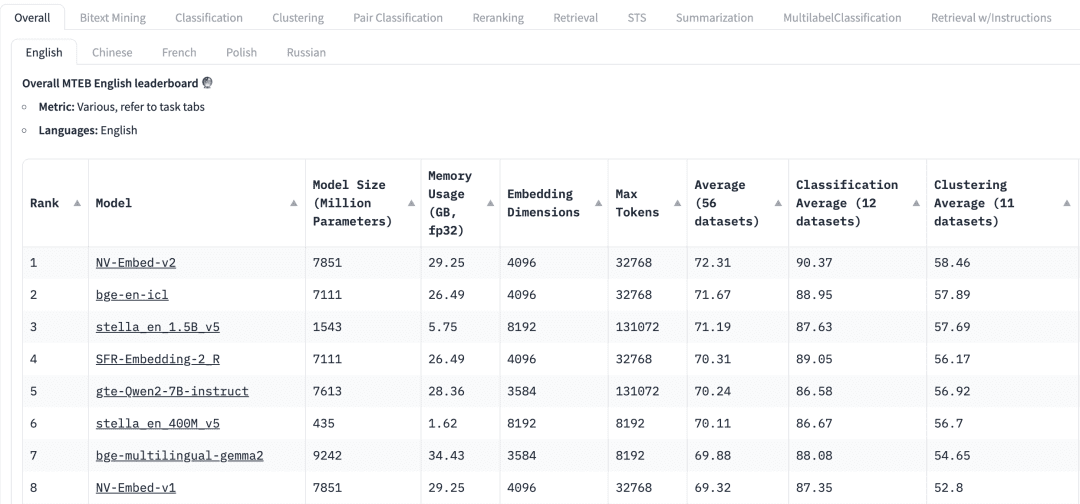
RAG 애플리케이션을 위한 임베딩 모델을 선택할 때는 다음 요소를 고려해야 합니다:
명령MTEB 리더보드 상단에는 다양한 작업 탭이 표시됩니다. RAG 애플리케이션의 경우 다음을 선택할 수 있는 "검색" 작업에 더 집중해야 할 수 있습니다. Retrial 이 탭입니다.
다국어 지원: RAG가 적용되는 데이터 세트의 언어를 기준으로 해당 언어에 대한 임베딩 모델을 선택합니다.
점수: 특정 벤치마크 데이터 세트 또는 여러 벤치마크 데이터 세트에서 모델의 성능을 나타냅니다. 작업에 따라 다른 평가 지표가 사용됩니다. 일반적으로 이러한 메트릭은 0에서 1 사이의 값을 사용하며, 값이 클수록 더 나은 성능을 나타냅니다.
모델 크기 및 메모리 사용량이 메트릭을 통해 모델을 실행하는 데 필요한 계산 리소스를 파악할 수 있습니다. 검색 성능은 모델 크기에 따라 향상되지만, 모델 크기는 지연 시간에도 직접적인 영향을 미친다는 점에 유의해야 합니다. 또한 모델이 클수록 과도하게 적합되어 일반화 성능이 낮아져 프로덕션에서 성능이 저하될 수 있습니다. 따라서 프로덕션 환경에서는 성능과 지연 시간 사이의 균형을 찾아야 합니다. 일반적으로 작고 가벼운 모델로 시작하여 RAG 애플리케이션을 먼저 빠르게 구축할 수 있습니다. 애플리케이션의 기본 프로세스가 제대로 작동하면 더 큰 고성능 모델로 전환하여 애플리케이션을 더욱 최적화할 수 있습니다.
임베딩 치수: 임베딩 벡터의 길이입니다. 임베딩 차원이 클수록 데이터의 세부 정보를 더 잘 포착할 수 있지만, 결과가 반드시 최적이라고 할 수는 없습니다. 예를 들어 문서 데이터에 8192개의 차원이 정말 필요할까요? 아마도 아닐 것입니다. 반면에 임베딩 차원이 작을수록 추론 속도가 빨라지고 저장 공간과 메모리 측면에서 더 효율적입니다. 따라서 데이터 콘텐츠 캡처와 실행 효율성 사이에서 적절한 균형을 찾아야 합니다.
최대 토큰 수는 단일 임베딩의 최대 토큰 수를 나타냅니다. 일반적인 RAG 애플리케이션의 경우 임베딩에 더 적합한 청크 크기는 일반적으로 단일 단락이며, 이 경우 최대 토큰이 512인 임베딩 모델로 충분합니다. 그러나 일부 특수한 경우에는 긴 텍스트를 처리하기 위해 더 많은 수의 토큰이 포함된 모델이 필요할 수 있습니다.
03. RAG 애플리케이션에서 모델 평가
MTEB 순위표에서 일반적인 모델을 찾을 수는 있지만, 그 결과를 신중하게 다뤄야 합니다. 이러한 결과는 모델이 자체적으로 보고한 결과라는 점을 염두에 두면, 일부 모델은 학습 데이터에 공개적으로 사용 가능한 데이터 세트인 MTEB 데이터 세트를 포함했을 수 있기 때문에 성능이 부풀려진 점수를 생성할 수 있습니다. 또한 모델이 벤치마킹에 사용하는 데이터 세트가 애플리케이션에 사용된 데이터를 정확하게 나타내지 않을 수도 있습니다. 따라서 자체 데이터 세트에서 임베딩 모델을 평가해야 합니다.
3.1 데이터 세트
RAG 애플리케이션에서 사용하는 데이터에서 태그가 지정된 작은 데이터 세트를 생성할 수 있습니다. 다음 데이터 세트를 예로 들어 보겠습니다.
| 언어 | 설명 |
|---|---|
| C/C++ | 성능과 효율성으로 잘 알려진 범용 프로그래밍 언어로, 낮은 수준의 메모리 조작 기능을 제공하며 시스템/소프트웨어 개발, 게임 개발 및 고성능이 필요한 애플리케이션에 널리 사용됩니다. |
| Java | 가능한 한 적은 구현 종속성을 갖도록 설계된 다목적 객체 지향 프로그래밍 언어로, 다음과 같은 구축에 널리 사용됩니다. 휴대성과 견고성으로 인해 엔터프라이즈급 애플리케이션, 모바일 애플리케이션(특히 Android) 및 웹 애플리케이션을 구축하는 데 널리 사용됩니다. |
| Python | 가독성과 단순성으로 잘 알려진 고수준의 해석 프로그래밍 언어입니다. 여러 프로그래밍 패러다임을 지원하며 널리 사용됩니다. 여러 프로그래밍 패러다임을 지원하며 웹 개발, 데이터 분석, 인공 지능, 과학 컴퓨팅 및 자동화 분야에서 널리 사용됩니다. |
| 자바스크립트 | 웹에서 대화형 동적 콘텐츠를 만드는 데 주로 사용되는 고수준 동적 프로그래밍 언어입니다. 다음과 같은 경우에 필수적인 기술입니다. 프론트엔드 웹 개발에 필수적인 기술이며 Node.js와 같은 환경에서 서버 측에서 점점 더 많이 사용되고 있습니다. |
| C# | 특히 Microsoft 에코시스템 내에서 웹, 데스크톱, 모바일, 게임 등 다양한 애플리케이션을 개발하는 데 사용됩니다. 특히 Microsoft 에코시스템 내에서 웹, 데스크톱, 모바일, 게임 등 다양한 애플리케이션을 개발하는 데 사용됩니다. |
| SQL | 관계형 데이터베이스를 프로그래밍하고 관리하는 데 사용되는 도메인 전용 언어입니다. 다음 분야에서 데이터를 쿼리, 업데이트 및 관리하는 데 필수적입니다. 데이터베이스의 데이터를 쿼리, 업데이트 및 관리하는 데 필수적이며 데이터 분석 및 비즈니스 인텔리전스 분야에서 널리 사용됩니다. |
| PHP | HTML에 내장되어 있으며 동적 웹 페이지와 애플리케이션을 구축하는 데 널리 사용되며, 워드프레스와 같은 콘텐츠 관리 시스템에서 강력한 입지를 차지하고 있습니다. 워드프레스와 같은 콘텐츠 관리 시스템에서 강력한 입지를 구축하고 있는 애플리케이션입니다. |
| Golang | Google에서 설계한 정적으로 유형화되고 컴파일된 프로그래밍 언어입니다. 단순성과 효율성으로 잘 알려진 이 언어는 확장 가능한 고성능 애플리케이션을 구축하는 데 사용됩니다. -특히 클라우드 서비스 및 분산 시스템에서 확장 가능하고 성능이 뛰어난 애플리케이션을 구축하는 데 사용됩니다. |
| Rust | 안전성과 동시성에 중점을 둔 시스템 프로그래밍 언어. 가비지 컬렉터를 사용하지 않고도 메모리 안전성을 제공하며, 특히 시스템 프로그래밍 및 웹 어셈블리 구축에 사용됩니다. 가비지 컬렉터를 사용하지 않고 메모리 안전성을 제공하며 특히 시스템 프로그래밍 및 웹 어셈블리에서 안정적이고 효율적인 소프트웨어를 빌드하는 데 사용됩니다. |
3.2 임베딩 만들기
다음으로pymilvus[model]위 데이터 세트의 경우 해당 벡터 임베딩이 생성됩니다. pymilvus[model] 사용 방법은 https://milvus.io/blog/introducing-pymilvus-integrations-with-embedding-models.md
def gen_embedding(model_name): openai_ef = model.dense.OpenAIEmbeddingFunction( model_name=model_name, api_key=os.environ["OPENAI_API_KEY"] ) docs_embeddings = openai_ef.encode_documents(df['description'].tolist()) return docs_embeddings, openai_ef
그런 다음 생성된 임베딩은 Milvus의 컬렉션에 저장됩니다.
def save_embedding(docs_embeddings, collection_name, dim):
data = [
{"id": i, "vector": docs_embeddings[i].data, "text": row.language}
for i, row in df.iterrows()
]
if milvus_client.has_collection(collection_name=collection_name):
milvus_client.drop_collection(collection_name=collection_name)
milvus_client.create_collection(collection_name=collection_name, dimension=dim)
res = milvus_client.insert(collection_name=collection_name, data=data)
3.3 쿼리
벡터 임베딩을 쉽게 불러올 수 있도록 쿼리 함수를 정의합니다.
def query_results(query, collection_name, openai_ef):
query_embeddings = openai_ef.encode_queries(query)
res = milvus_client.search(
collection_name=collection_name,
data=query_embeddings,
limit=4,
output_fields=["text"],
)
result = {}
for items in res:
for item in items:
result[item.get("entity").get("text")] = item.get('distance')
return result
3.4 임베딩 모델 성능 평가
저희는 OpenAI의 두 가지 임베딩 모델을 사용합니다.text-embedding-3-small 노래로 응답 text-embedding-3-large를 사용하여 다음 두 쿼리를 비교합니다. 정확도, 리콜, MRR, MAP 등과 같은 많은 평가 지표가 있습니다. 여기서는 정확도와 리콜을 사용합니다.
정확도 검색 결과에서 실제 관련성이 있는 콘텐츠의 비율, 즉 반환된 결과 중 검색어와 관련된 콘텐츠가 얼마나 많은지 평가합니다.
정밀도 = TP / (TP + FP)
이 경우 정탐(TP)은 검색어와 실제로 관련성이 있는 검색어를 의미하며, 오탐(FP)은 검색 결과에서 관련성이 없는 검색어를 의미합니다.
리콜은 전체 데이터 세트에서 성공적으로 검색된 관련 콘텐츠의 양을 평가합니다.
리콜 = TP / (TP + FN)
FN(거짓 부정)은 최종 결과 세트에 포함되지 않은 모든 관련 항목을 의미합니다.
이 두 가지 개념에 대한 자세한 설명은 다음과 같습니다.
문의 1::auto garbage collection
관련 항목: 자바, 파이썬, 자바스크립트, 골랑
| 순위 | 텍스트 임베딩-3-small | 텍스트 임베딩-3-large |
|---|---|---|
| 1 | ❎ 녹 | ❎ 녹 |
| 2 | ❎ C/C++ | ❎ C/C++ |
| 3 | ✅ Golang | ✅ Java |
| 4 | ✅ Java | ✅ Golang |
| 정밀도 | 0.50 | 0.50 |
| 리콜 | 0.50 | 0.50 |
문의 2::suite for web backend server development
관련 항목: 자바, 자바스크립트, PHP, 파이썬(답변에 주관적 판단이 포함됨)
| 순위 | 텍스트 임베딩-3-small | 텍스트 임베딩-3-large |
|---|---|---|
| 1 | ✅ PHP | ✅ JavaScript |
| 2 | ✅ Java | ✅ Java |
| 3 | ✅ JavaScript | ✅ PHP |
| 4 | ❎ C# | ✅Python |
| 정밀도 | 0.75 | 1.0 |
| 리콜 | 0.75 | 1.0 |
다음 두 쿼리에서 정확도와 리콜을 기준으로 두 임베딩 모델을 비교했습니다. text-embedding-3-small 노래로 응답 text-embedding-3-large 임베딩 모델을 시작점으로 사용할 수 있습니다. 이를 시작점으로 삼아 데이터 집합의 데이터 개체 수와 쿼리 수를 늘려 임베딩 모델을 더 효과적으로 평가할 수 있습니다.
04. 요약
검색 증강 생성(RAG) 애플리케이션에서는 적절한 벡터 임베딩 모델을 선택하는 것이 매우 중요합니다. 이 백서에서는 실제 비즈니스 요구사항에서 MTEB의 일반 모델을 선택한 후, 비즈니스별 데이터 세트를 기반으로 정확도와 리콜을 테스트하여 가장 적합한 임베딩 모델을 선택하고, 이를 통해 RAG 애플리케이션의 리콜 정확도를 효과적으로 개선하는 방법을 설명합니다.
전체 코드는 다운로드를 통해 확인할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서




댓글 없음...