

Qwen3-ASR-Flash란 무엇인가요?
Qwen3-ASR-Flash는 알리바바의 최신 고정밀 음성 인식 모델입니다. Qwen3 방대한 멀티모달 데이터로 학습된 기본 모델. 만다린어, 쓰촨어, 민난어, 우어, 광둥어 등의 방언과 영국 및 미국 영어를 포함한 11개 언어와 여러 억양을 지원합니다. 주요 기능으로는 최고의 인식 정확도, 놀라운 노래 인식 능력(오류율 8% 미만), 맞춤형 인식(사용자가 배경 텍스트를 제공하여 맞춤형 결과를 얻을 수 있음), 비음성 제거 기능을 갖춘 언어 인식, 복잡한 음향 환경에서의 높은 견고성 등이 있습니다. 사용자는 모델스코프, 허깅 페이스, 알리클라우드 백 리파이닝 API를 통해 이 모델을 무료로 체험해 볼 수 있습니다.
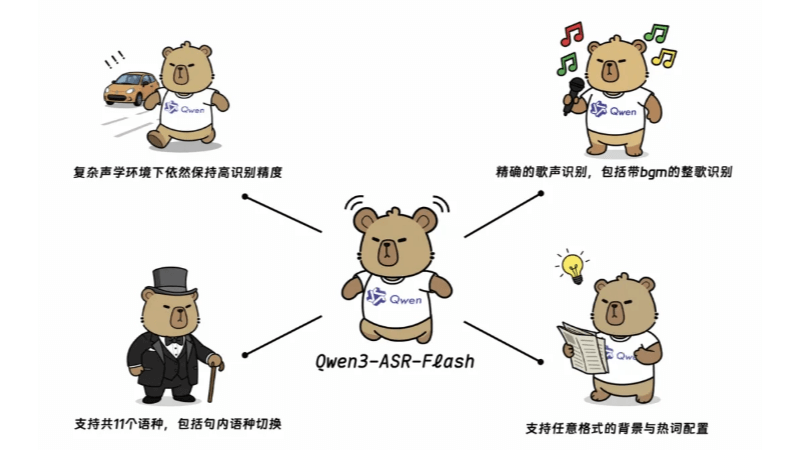
Qwen3-ASR-Flash 기능적 특징
- 매우 정확한 인식영어, 중국어 및 다국어 벤치마크에서 최고의 성능을 발휘하며 여러 언어와 방언을 정확하게 인식합니다.
- 노래 인식이 시스템은 배경 음악과 함께 깨끗한 노래와 전곡 인식을 지원하며, 측정된 오류율은 8%보다 낮습니다.
- 맞춤형 신원 확인사용자가 어떤 형식의 배경 텍스트도 제공할 수 있으며, 모델은 사전 처리 없이도 그에 따라 인식 결과를 조정할 수 있습니다.
- 언어 인식 및 비음성 거부 기능음성 언어를 정확하게 구분하고 침묵 및 배경 소음과 같은 비음성 부분을 자동으로 필터링합니다.
- 높은 견고성복잡한 음향 환경이나 길고 어려운 문장, 문장 중간에 언어가 바뀌는 등 어려운 텍스트 패턴이 있을 때 높은 정확도를 유지합니다.
Qwen3-ASR-Flash의 핵심 이점
- 매우 정확한 인식다국어 및 방언 인식 테스트에서 뛰어난 성능을 보이며 경쟁 제품보다 오류율이 낮습니다.
- 다국어 지원단일 모델은 중국어, 영어, 프랑스어, 독일어 등 11개 언어와 여러 방언을 지원합니다.
- 맞춤형 신원 확인사용자가 어떤 형식의 배경 텍스트도 제공할 수 있으며, 모델은 문맥 정보를 지능적으로 사용하여 맞춤형 인식 결과를 출력할 수 있습니다.
- 노래 인식배경 음악이 있는 깨끗한 노래와 전곡 인식을 지원하며, 측정된 오차율이 8%보다 낮아 노래 인식 분야에서 뛰어난 성능을 발휘합니다.
- 언어 인식 및 비음성 거부 기능음성 언어를 정확하게 구분하고 침묵 및 배경 소음과 같은 비음성 부분을 자동으로 필터링하는 기능으로 인식 효율성이 향상됩니다.
- 높은 견고성복잡한 음향 환경이나 길고 어려운 문장, 문장 중간에 언어가 바뀌는 등 어려운 텍스트 패턴이 있을 때 높은 정확도를 유지합니다.
Qwen3-ASR-Flash의 공식 웹사이트는 무엇인가요?
- 프로젝트 웹사이트: https://bailian.console.aliyun.com/?spm=5176.29597918.J_tAwMEW-mKC1CPxlfy227s.1.4f007b08aWhTjW&tab=model#/model-market/detail /group-qwen3-asr-flash?modelGroup=group-qwen3-asr-flash
- 온라인 경험 데모:: https://huggingface.co/spaces/Qwen/Qwen3-ASR-Demo
Qwen3-ASR-Flash의 대상 사용자
- 고정밀 음성 트랜스크립션이 필요한 사용자저널리스트, 회의 기록자, 연구원 등 음성 콘텐츠를 텍스트로 빠르고 정확하게 변환할 수 있습니다.
- 다국어외국어 학습자, 다국적 기업 직원, 국제 회의 참가자 등 언어 장벽을 뛰어넘는 데 도움을 줄 수 있습니다.
- 콘텐츠 크리에이터동영상 블로거, 팟캐스트 진행자 등이 자막과 대본을 효율적으로 생성할 수 있습니다.
- 현장 전문가예를 들어 의료, 금융 및 법률 분야의 실무자는 맞춤형 인식 기능을 사용하여 용어를 정확하게 식별할 수 있습니다.
- 특별한 음성 인식이 필요한 사람예를 들어 청각 장애인은 모델의 도움을 받아 음성 정보를 더 잘 이해할 수 있으며, 고객 서비스 담당자나 현장 기자처럼 시끄러운 환경에서 음성 인식이 필요한 사용자도 활용할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...