

AI 분야에서는 모델 선택이 매우 중요합니다. 업계 리더인 openAI는 두 가지 주요 유형의 모델 제품군을 제공합니다:추론 모델 (추론 모델) 및 GPT 모델 (GPT 모델). 전자는 다음과 같은 O 시리즈 모델로 대표됩니다. o1 노래로 응답 o3-mini후자는 다음과 같은 GPT 모델군으로 유명합니다. GPT-4o. 이 두 가지 유형의 모델 간의 차이점과 각각이 뛰어난 적용 시나리오를 이해하는 것은 AI의 잠재력을 최대한 활용하기 위해 매우 중요합니다.
이 글에서는 이에 대해 자세히 설명합니다:
- OpenAI 추론 모델과 GPT 모델의 주요 차이점.
- OpenAI 추론 모델 사용의 우선순위를 정해야 하는 경우.
- 최적의 성능을 위해 추론 모델을 효과적으로 큐잉하는 방법.
얼마 전 Microsoft 엔지니어들은 OpenAI O1 및 O3 미니 추론 모델을 위한 힌트 엔지니어링 로 설정하면 둘 사이의 적용 차이를 비교할 수 있습니다.
추론 모델과 GPT 모델: 전략가 대 실행자
익숙한 GPT 모델과 달리 OpenAI의 추론 모델인 o-시리즈는 다양한 유형의 작업에서 고유한 강점을 나타내며 서로 다른 큐잉 전략을 필요로 합니다. 이 두 가지 유형의 모델은 단순히 더 좋거나 나쁘다는 것이 아니라 서로 다른 기능에 중점을 두고 있다는 점을 이해하는 것이 중요합니다. 이는 심층 추론이 필요한 점점 더 복잡한 애플리케이션의 요구 사항을 해결하기 위해 모델 기능의 경계를 확장하려는 OpenAI의 지속적인 노력을 반영합니다.
OpenAI는 내부적으로 Planners라는 코드명을 가진 O 시리즈 모델을 더 오래, 더 깊이 사고하도록 특별히 훈련시켜 전략 수립, 복잡한 문제 계획, 대량의 모호한 정보에 기반한 의사 결정 등의 분야에서 탁월한 능력을 발휘할 수 있도록 했습니다. 이러한 모델은 높은 수준의 정밀도와 정확성으로 작업을 완료할 수 있기 때문에 수학, 과학, 엔지니어링, 금융 서비스, 법률 서비스 등 전통적으로 인간 전문가에게 의존하는 전문 분야에 이상적입니다.
반면에 OpenAI의 GPT 모델(내부 코드명 "Workhorses")은 지연 시간이 더 짧고 비용 효율적이며 직접 작업을 실행하도록 설계되었습니다. 실제로는 이 두 가지 유형의 모델을 조합하여 사용하는 것이 일반적인 패턴으로, 특히 절대적인 정확도보다 속도와 비용 효율성이 더 중요한 시나리오에서는 O 시리즈 모델을 사용하여 문제 해결을 위한 거시적 전략을 수립한 다음 GPT 모델을 통해 특정 하위 작업을 효율적으로 실행하는 것입니다. 이러한 분업은 계획과 실행을 분리하는 AI 모델 설계 철학의 성숙도를 반영합니다.
적합한 모델을 선택하는 방법은 무엇인가요? 요구 사항 이해
모델을 선택할 때 핵심은 애플리케이션 시나리오의 핵심 요구 사항을 정의하는 것입니다:
- 속도와 비용. 속도와 비용 효율성이 우선 순위라면 일반적으로 GPT 모델이 더 빠르고 경제적인 선택입니다.
- 명확하게 정의된 작업. 목표가 명확하고 작업 경계가 잘 정의된 애플리케이션의 경우 GPT 모델은 실행 작업에서 탁월한 성능을 발휘할 수 있습니다.
- 정확성 및 신뢰성. 최고 수준의 정확도와 결과의 신뢰성이 요구되는 애플리케이션의 경우, o-시리즈 모델이 더 신뢰할 수 있는 의사 결정권자입니다.
- 복잡한 문제 해결. 모호성과 복잡성이 높은 상황에서도 O 시리즈 모델은 효과적으로 대처할 수 있습니다.
따라서 속도와 비용이 주요 고려 사항이고 사용 사례에 주로 간단하고 잘 정의된 작업이 포함된다면 OpenAI의 GPT 모델이 이상적입니다. 그러나 정확성과 신뢰성이 중요하고 복잡한 다단계 문제를 해결해야 하는 경우에는 OpenAI의 o 시리즈 모델이 더 적합할 수 있습니다.
많은 실제 AI 워크플로우에서 가장 좋은 방법은 이 두 모델을 조합하여 사용하는 것입니다. 즉, o 모델군은 상담원 계획 및 의사 결정을 담당하는 '플래너' 역할을 하고, GPT 모델군은 특정 작업 실행을 담당하는 '실행자' 역할을 합니다. 이 조합 전략은 두 가지 유형의 모델의 강점을 최대한 활용합니다.

예를 들어, 고객 서비스 시나리오에서는 고객 정보를 먼저 사용하여 주문 세부 정보를 분류하고 주문 문제와 반품 정책을 파악한 다음, 이러한 데이터 포인트를 o3-mini 모델에 입력하여 사전 설정된 정책에 따라 반품 가능 여부를 최종 결정하는 데 OpenAI의 GPT-4o 및 GPT-4o mini 모델을 사용할 수 있습니다.
추론 모델의 적용 시나리오: 복잡성 및 모호성 해결에 탁월함
OpenAI는 고객과의 협업 및 내부 관찰을 통해 추론 모델을 성공적으로 적용한 몇 가지 일반적인 패턴을 개발했습니다. 아래 나열된 적용 시나리오는 전체가 아니라 OpenAI의 o 시리즈 모델을 더 잘 평가하고 테스트하는 데 도움이 되도록 설계된 실용적인 가이드입니다.
1. 모호한 작업 탐색: 단편적인 정보에서 의도 파악하기
추론 모델은 특히 불완전하거나 흩어져 있는 정보가 있는 작업을 처리하는 데 탁월합니다. 추론 모델은 제한된 정보를 제공하더라도 사용자의 진정한 의도를 효과적으로 파악하고 지침의 모호함을 적절히 처리할 수 있습니다. 추론 모델은 일반적으로 섣부른 추측을 하거나 스스로 정보 격차를 메우려고 하지 않고, 작업 요구 사항을 정확하게 이해하기 위해 적극적으로 명확한 질문을 던진다는 점을 언급할 가치가 있습니다. 이는 불확실성과 복잡한 작업을 처리할 때 추론 모델의 장점을 보여주는 좋은 예입니다.
법률 및 금융 부문을 위한 AI 지식 플랫폼인 헤비아는 "o1의 뛰어난 추론 기능 덕분에 OpenAI의 다중 에이전트 플랫폼인 Matrix는 복잡한 문서를 효율적으로 처리하고 상세하고 체계적이며 유익한 답변을 생성할 수 있습니다. 예를 들어, o1은 간단한 프롬프트만으로 결제 한도가 제한된 신용 계약에 따라 사용 가능한 금액을 쉽게 파악할 수 있습니다. 이전에는 어떤 모델도 이 정도의 성능을 달성하지 못했습니다. 52%의 집중적인 신용 계약 복합 큐잉 테스트에서 o1은 다른 모델에 비해 더 유의미한 결과를 달성했습니다."
-법률 및 금융 분야를 위한 AI 지식 플랫폼 기업, 헤비아(Hebbia)
2. 정보 검색: 건초더미에서 바늘 찾기, 정확한 위치 찾기
추론 모델은 방대한 양의 비정형 정보에 직면했을 때 강력한 정보 이해력을 발휘하고 질문과 가장 관련성이 높은 정보를 정확하게 추출하여 사용자의 질문에 효율적으로 답변할 수 있습니다. 이는 특히 대규모 데이터 세트를 다룰 때 정보 검색 및 핵심 정보 필터링에서 추론 모델의 우수한 성능을 강조합니다.
AI 금융 인텔리전스 플랫폼인 Endex는 "기업 인수를 심층적으로 분석하기 위해 계약서, 임대차 계약서 등 수십 개의 회사 문서를 검토하여 거래에 부정적인 영향을 미칠 수 있는 잠재적 조항을 찾기 위해 o1 모델을 사용했습니다. 이 모델은 주요 조항에 플래그를 지정하는 임무를 맡았습니다. 이 과정에서 o1은 각주에서 회사를 매각할 경우 7,500만 달러의 대출금을 즉시 상환해야 한다는 핵심 '경영권 변경' 조항을 예리하게 찾아냈습니다. 각주에서 회사를 매각할 경우 7,500만 달러의 대출금을 즉시 상환해야 한다는 핵심 조항을 찾아내는 데도 o1의 세부적인 주의가 결정적이었습니다. 세부 사항에 대한 o1의 높은 관심 덕분에 OpenAI의 AI 에이전트는 미션 크리티컬 정보를 정확하게 식별하여 금융 전문가들의 업무를 효과적으로 지원할 수 있었습니다."
--엔덱스, AI 금융 인텔리전스 플랫폼
3. 관계 발견 및 뉘앙스 식별: 데이터의 가치에 대해 더 깊이 파고들기
OpenAI는 추론 모델이 법률 계약서, 재무제표, 보험금 청구서 등 수백 페이지에 달하는 고밀도 비정형 문서를 분석하는 데 특히 효과적이라는 사실을 발견했습니다. 이러한 모델은 복잡한 문서에서 정보를 추출하고, 서로 다른 문서를 연결하며, 데이터에 내포된 사실을 바탕으로 추론적 결정을 내리는 데 효과적입니다. 이는 추론 모델이 복잡한 문서를 처리하고 심층 정보를 마이닝하는 데 상당한 이점을 가지고 있음을 보여줍니다.
세금 조사를 위한 AI 플랫폼인 Blue J는 "세금 조사는 최종적이고 설득력 있는 결론을 도출하기 위해 여러 문서의 정보를 통합해야 하는 경우가 많습니다. OpenAI는 GPT-4o 모델을 o1 모델로 교체한 후 o1이 문서 간의 상호 작용을 더 잘 추론하고 단일 문서에서 명확하지 않은 논리적 결론을 도출할 수 있다는 사실을 발견했습니다. 그 결과, o1 모델로 전환함으로써 OpenAI는 엔드투엔드 성능이 4배나 향상되는 놀라운 결과를 얻었습니다."
--세금 조사를 위한 AI 플랫폼, Blue J
추론 모델은 미묘한 정책과 규칙을 이해하고 이를 특정 작업에 적용하여 합리적인 결론에 도달하는 데에도 똑같이 능숙합니다.
투자 관리 AI 플랫폼인 BlueFlame AI는 "재무 분석 분야에서 애널리스트는 종종 주주의 권리와 관련된 복잡한 상황을 처리해야 하며 관련 법적 복잡성에 대한 깊은 이해가 필요합니다."라고 예를 들었습니다. OpenAI는 어렵지만 일반적인 질문인 '기존 주주가 희석 방지 특권을 행사할 때 자금 조달 행위가 기존 주주에게 어떤 영향을 미칠까'라는 질문을 사용하여 여러 공급업체의 약 10개 모델을 테스트했습니다. 이 질문에는 자금 조달 전후의 기업 가치에 대한 추론과 주기적 희석의 복잡성을 처리해야 하는데, 이는 최고의 재무 분석가도 20~30분 정도면 이해할 수 있는 질문입니다. OpenAI는 o1 및 o3-mini 모델이 이 문제를 완벽하게 해결한다는 사실을 발견했습니다! 이 모델은 심지어 10만 명의 주주에게 자금 조달 행동이 미치는 영향을 자세히 보여주는 명확한 계산 표를 생성했습니다."
--투자 관리 AI 플랫폼, BlueFlame AI
4. 다단계 에이전시 계획: 운영을 위한 전략적 계획, 성공을 위한 전략
추론 모델은 상담원 계획 및 전략 수립에 중요한 역할을 합니다. OpenAI는 추론 모델을 '계획자'로 배치할 경우 복잡한 문제에 대한 상세한 다단계 솔루션을 생성할 수 있음을 관찰했습니다. 그 후 시스템은 지연 시간과 지능에 대한 다양한 요구 사항에 따라 각 단계를 실행할 가장 적합한 GPT 모델("실행자")을 선택하고 할당할 수 있습니다. 이는 추론 모델이 전략 계획의 '두뇌' 역할을 하고 GPT 모델이 실행의 '팔과 다리' 역할을 하는 모델 조합 사용의 장점을 더욱 잘 보여줍니다.
제약 업계를 위한 AI 지식 플랫폼인 Argon AI는 "OpenAI는 에이전트 인프라에서 o1 모델을 플래너로 사용하여 워크플로우의 다른 모델을 조율하여 다단계 작업을 효율적으로 완료할 수 있도록 지원합니다."라고 밝혔습니다. o1 모델은 올바른 유형의 데이터를 선택하고 크고 복잡한 문제를 관리하기 쉬운 작은 모듈로 세분화하여 다른 모델이 특정 실행에 집중할 수 있도록 하는 데 매우 능숙하다는 사실을 발견했습니다."라고 말합니다.
--제약 산업을 위한 AI 지식 플랫폼, Argon AI
업무용 AI 비서인 Lindy.AI는 "o1 모델은 OpenAI의 AI 업무 비서인 Lindy의 다양한 상담원 워크플로우를 강력하게 지원합니다. 이 모델은 함수 호출을 사용하여 사용자의 캘린더나 이메일에서 주요 정보를 추출하여 회의 예약, 이메일 전송, 기타 일상 업무 관리를 자동으로 지원할 수 있습니다. OpenAI는 문제를 일으켰던 과거 린디의 모든 에이전트 단계를 o1 모델로 전환했고, 거의 하룻밤 사이에 린디의 에이전트 기능이 완벽하게 작동하는 것을 관찰할 수 있었습니다!"
--린디.AI, 업무 AI 어시스턴트
5. 시각적 추론: 이미지 이면의 정보에 대한 통찰력
오늘부터.o1 는 시각적 추론 기능을 지원하는 유일한 추론 모델입니다. o1 와 함께 GPT-4o 의 중요한 차이점은o1 복잡한 구조의 차트, 표, 화질이 좋지 않은 사진 등 가장 까다로운 시각적 정보도 효과적으로 처리할 수 있습니다. 이는 다음 사항의 중요성을 강조합니다. o1 시각 정보 처리 분야에서 독보적인 이점을 제공합니다.
AI 판매자 모니터링 플랫폼인 Safetykit은 "OpenAI는 명품 주얼리 복제품, 멸종 위기종, 규제 품목 등 수백만 개의 온라인 제품에 대한 위험 및 규정 준수 검토를 자동화하는 데 전념하고 있습니다. OpenAI의 가장 까다로운 이미지 분류 작업에서 GPT-4o 모델의 정확도는 50%에 불과했습니다.
o1이 모델은 OpenAI의 기존 프로세스를 수정하지 않고도 최대 88%의 인상적인 정확도를 달성합니다."-안전 키트, AI 판매자 모니터링 플랫폼
OpenAI의 자체 내부 테스트에서도 다음과 같은 결과가 나타났습니다.o1 이 모델은 매우 상세한 건축 도면에서 비품과 자재를 식별하고 종합적인 자재 명세서를 생성할 수 있습니다. OpenAI가 관찰한 가장 놀라운 현상 중 하나는o1 예를 들어, 이 모델은 건축 도면의 한 페이지에 있는 범례를 명시적인 지침 없이 다른 페이지에 정확하게 적용할 수 있습니다. 아래 예시에서 "4x4 PT 나무 기둥"의 경우, "4x4 PT 나무 기둥"에 대해o1 이 모델은 범례에 따라 "PT"가 "압력 처리"를 의미한다는 것을 정확하게 인식할 수 있었습니다. 이는 o1 모델은 복잡한 시각적 정보 이해와 문서 간 추론에서 강력한 성능을 발휘합니다.

6. 코드 검토, 디버깅 및 품질 개선: 우수성, 코드 최적화를 위한 노력
추론 모델은 코드 검토 및 개선에 탁월하며 특히 대규모 코드 베이스를 처리하는 데 탁월합니다. 추론 모델의 상대적으로 높은 지연 시간을 고려할 때 코드 검토 작업은 일반적으로 백그라운드에서 실행됩니다. 이는 지연 시간에도 불구하고 추론 모델이 코드 분석 및 품질 관리, 특히 높은 실시간 성능이 필요하지 않은 시나리오에서 중요한 응용 분야를 가지고 있음을 시사합니다.
AI 코드 리뷰 스타트업 CodeRabbit은 "OpenAI는 GitHub 및 GitLab과 같은 코드 호스팅 플랫폼에서 자동화된 AI 코드 리뷰 서비스를 제공합니다. 코드 리뷰 프로세스는 본질적으로 지연 시간에 민감하지 않지만 여러 파일의 코드 변경 사항에 대한 깊은 이해가 필요합니다. 이 점에서 o1 모델은 탁월한 성능을 발휘하며, 사람 리뷰어가 놓치기 쉬운 코드베이스의 미묘한 변경 사항을 안정적으로 감지합니다. OpenAI는 o 시리즈 모델로 전환한 후 제품 전환이 3배 증가했습니다."
-AI 코드 리뷰 스타트업, CodeRabbit
비록 GPT-4o 노래로 응답 GPT-4o mini 모델이 지연 시간이 짧은 코딩 시나리오에 더 적합할 수 있지만, OpenAI는 다음과 같이 관찰합니다. o3-mini 모델은 지연에 민감하지 않은 코드 생성 사용 사례에 탁월합니다. 즉 o3-mini 또한 코드 생성 영역, 특히 높은 코드 품질이 필요하고 상대적으로 지연에 관대한 애플리케이션 시나리오에서 잠재력을 가지고 있습니다.
AI 기반 코드 완성 스타트업 코듐 는 "까다로운 코딩 작업에도 불구하고
o3-mini또한 모델은 고품질의 결정적인 코드를 일관되게 생성할 수 있으며, 문제가 잘 정의된 경우 올바른 솔루션을 제공하는 경우가 매우 많습니다. 다른 모델은 작고 빠른 코드 반복에만 적합할 수 있지만o3-mini모델은 복잡한 소프트웨어 설계 시스템을 계획하고 실행하는 데 특화되어 있습니다."--코디엄, AI 기반 코드 확장 스타트업
7. 모델 평가 및 벤치마킹: 객관적인 평가 및 최고 중의 최고 선정
또한 OpenAI는 추론 모델이 다른 모델의 응답을 벤치마킹하고 평가할 때 우수한 성능을 보인다는 사실을 발견했습니다. 데이터 검증은 특히 의료와 같은 민감한 영역에서 데이터 세트의 품질과 신뢰성을 보장하는 데 매우 중요합니다. 기존의 유효성 검사 방법은 사전 정의된 규칙과 패턴에 의존하지만, 다음과 같은 방법은 o1 노래로 응답 o3-mini 이러한 고급 모델은 맥락을 이해하고 추론할 수 있으므로 보다 유연하고 지능적인 검증 방법을 사용할 수 있습니다. 이는 추론 모델이 다른 모델의 출력 품질을 평가하는 '심판' 역할을 할 수 있음을 시사하며, 이는 AI 시스템의 반복적인 최적화에 매우 중요합니다.
AI 평가 플랫폼인 브레인트러스트는 "많은 고객이 평가 프로세스의 일부로 브레인트러스트 플랫폼의 LLM-as-a-judge 기능을 사용합니다. 예를 들어, 의료 회사에서 다음과 같은 도구를 사용할 수 있습니다.
gpt-4o이러한 마스터 모델을 사용하여 환자 이력 문제를 요약한 다음o1모델을 사용하여 초록의 품질을 평가합니다. 한 Braintrust 고객은4o모델을 심판으로 사용하는 경우 F1 점수는 0.12이며, 심판으로 전환하면o1모델링 후 F1 점수는 0.74로 뛰어올랐습니다! 이러한 사용 사례에서 다음과 같은 사실을 발견했습니다.o1이 모델의 추론 능력은 특히 가장 어렵고 복잡한 채점 작업에서 완료 결과의 미묘한 차이를 포착하는 데 혁신적입니다."--AI 평가 플랫폼, Braintrust
추론 모델을 효과적으로 유도하기 위한 팁: 단순함이 우선입니다.
추론 모델은 명확하고 간결한 프롬프트를 받을 때 가장 잘 수행하는 경향이 있습니다. 모델에게 "단계별로 생각하라"고 지시하는 것과 같은 일부 전통적인 큐 엔지니어링 기법은 성과를 개선하는 데 효과적이지 않을 수 있으며 때로는 역효과가 날 수도 있습니다. 다음은 몇 가지 모범 사례를 참조하거나 큐잉 예시를 참고하여 시작할 수 있습니다.
- 개발자 메시지는 시스템 메시지를 대체합니다. 통해 (틈새)
o1-2024-12-17버전부터는 추론 모델이 모델 사양에 설명된 명령 체인 동작을 준수하기 위해 기존 시스템 메시지가 아닌 개발자 메시지를 지원하기 시작했습니다. - 프롬프트는 간단하고 직접적으로 표시하세요. 추론 모델은 명확하고 간결한 지시를 이해하고 반응하는 데 능숙합니다. 따라서 추론 모델에는 복잡한 큐 엔지니어링 기술보다 명확하고 직접적인 지침이 더 효과적입니다.
- 생각의 사슬 피하기 팁. 추론 모델에는 이미 내부적으로 추론 기능이 있으므로 '단계별로 생각하라'거나 '추론 과정을 설명하라'는 메시지를 표시할 필요가 없습니다. 이러한 중복 프롬프트는 오히려 모델 성능을 저하시킬 수 있습니다.
- 구분 기호를 사용하여 명확성을 높입니다. 마크다운, XML 태그 및 섹션 제목과 같은 구분 기호를 사용하여 입력의 다른 부분에 명확하게 레이블을 지정하면 모델이 여러 섹션의 콘텐츠를 정확하게 이해하는 데 도움이 됩니다.
- 더 적은 샘플 단서를 고려하기 전에 제로 샘플 단서에 대한 시도의 우선 순위를 정합니다. 추론 모델은 일반적으로 몇 개의 샘플 예제 없이도 좋은 결과를 생성합니다. 따라서 먼저 예제 없이 제로 샘플 힌트를 작성하는 것이 좋습니다. 출력 결과에 대한 더 복잡한 요구 사항이 있는 경우 힌트에 입력 및 원하는 출력의 예시를 포함하는 것이 도움이 될 수 있습니다. 그러나 예제와 프롬프트 지침이 서로 다르면 결과가 좋지 않을 수 있으므로 예제가 프롬프트 지침과 매우 일관성이 있는지 확인하는 것이 중요합니다.
- 명확하고 구체적인 안내를 제공하세요. 모델의 응답 범위를 제한할 수 있는 명시적인 제약 조건이 있는 경우(예: "예산이 $500 미만인 솔루션 제안") 프롬프트에 이러한 제약 조건을 명확하게 명시하세요.
- 최종 목표의 명확화. 지침에서 성공적인 응답을 판단할 기준을 최대한 구체적으로 설명하고, 모델이 성공 기준을 충족할 때까지 계속 추론하고 반복하도록 장려하세요.
- 마크다운 서식 지정 제어. 통해 (틈새)
o1-2024-12-17버전 1부터 API의 추론 모델은 기본적으로 마크다운 서식이 있는 응답을 생성하지 않습니다. 모델이 응답에 마크다운 서식을 포함하도록 하려면 응답에 문자열Formatting re-enabled.
추론 모델 API 사용 예시
추론 모델은 '사고' 프로세스가 독특합니다. 기존의 언어 모델과 달리 추론 모델은 내부적으로 깊이 사고하고 긴 추론의 사슬을 구축한 후 답을 제시합니다. OpenAI 공식 설명에 명시된 바와 같이, 이러한 모델은 사용자에게 응답하기 전에 깊이 생각합니다. 이러한 메커니즘 덕분에 추론 모델은 복잡한 퍼즐 풀기, 코딩, 과학적 추론, 상담원 워크플로우를 위한 다단계 계획과 같은 작업에 탁월한 능력을 발휘할 수 있습니다.
OpenAI의 GPT 모델과 유사하게 OpenAI는 서로 다른 요구 사항을 충족하는 두 가지 추론 모델을 제공합니다:o3-mini 이 모델은 더 작은 크기와 빠른 속도로 눈에 띄는 반면에 토큰 비용도 상대적으로 낮습니다. o1 반면 모델은 더 강력한 문제 해결을 위해 더 큰 규모와 약간 느린 속도를 희생합니다.o1 모델은 일반적으로 복잡한 작업을 처리할 때 더 나은 품질의 응답을 생성하고 여러 도메인에서 더 나은 일반화 성능을 보여줍니다.
빠른 시작
개발자가 빠르게 시작할 수 있도록 OpenAI는 사용하기 쉬운 API 인터페이스를 제공합니다. 다음은 채팅 완성에서 추론 모델을 사용하는 방법에 대한 빠른 시작 예제입니다:
채팅 완료에 추론 모델 사용하기
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,
格式为 '[1,2],[3,4],[5,6]',并以相同的格式打印转置矩阵。
`;
const completion = await openai.chat.completions.create({
model: "o3-mini",
reasoning_effort: "medium",
messages: [
{
role: "user",
content: prompt
}
],
});
console.log(completion.choices[0].message.content);
from openai import OpenAI
client = OpenAI();
prompt = """
编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,
格式为 '[1,2],[3,4],[5,6]',并以相同的格式打印转置矩阵。
"""
response = client.chat.completions.create(
model="o3-mini",
reasoning_effort="medium",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "o3-mini",
"reasoning_effort": "medium",
"messages": [
{
"role": "user",
"content": "编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,格式为 \"[1,2],[3,4],[5,6]\",并以相同的格式打印转置矩阵。"
}
]
}'
추론의 강도: 모델에서 사고의 깊이 제어하기
위의 예에서reasoning_effort 이 매개변수(이러한 모델을 개발할 때 '주스'라는 애칭으로 불림)는 응답을 생성하기 전에 모델이 얼마나 많은 추론 계산을 수행하는지 안내하는 데 사용됩니다. 사용자는 이 매개변수에 대해 다음과 같이 지정할 수 있습니다. low및medium 어쩌면 high 세 가지 값 중 하나입니다. Where.low 모델은 속도와 낮은 토큰 비용에 중점을 두는 반면에 high 모드는 모델에서 더 심층적이고 포괄적인 추론을 유도하지만 토큰 소비와 응답 시간이 늘어납니다. 기본값은 다음과 같이 설정됩니다. medium는 속도와 추론 정확도 사이의 균형을 이루는 것을 목표로 합니다. 개발자는 실제 애플리케이션 시나리오의 요구 사항에 따라 추론 강도를 유연하게 조정하여 최적의 성능과 비용 효율성을 달성할 수 있습니다.
추론의 작동 원리: 모델의 '사고' 프로세스에 대한 심층 분석
추론 모델은 기존의 입력 및 출력 토큰을 기반으로 하여 토큰에 대한 추론 이 개념. 이러한 추론 토큰은 모델의 '사고 과정'과 유사하며, 모델은 이를 사용하여 사용자의 단서에 대한 이해를 분해하고 답을 생성하기 위한 여러 가능한 경로를 탐색합니다. 추론 토큰 생성이 완료된 후에야 모델은 최종 답변, 즉 사용자에게 보이는 보완 토큰을 출력하고 컨텍스트에서 추론 토큰을 삭제합니다.
다음 그림은 사용자와 어시스턴트 간의 다단계 대화의 예를 보여줍니다. 대화의 각 단계에서 입력 및 출력 토큰은 유지되는 반면 추론 토큰은 모델에 의해 폐기됩니다.
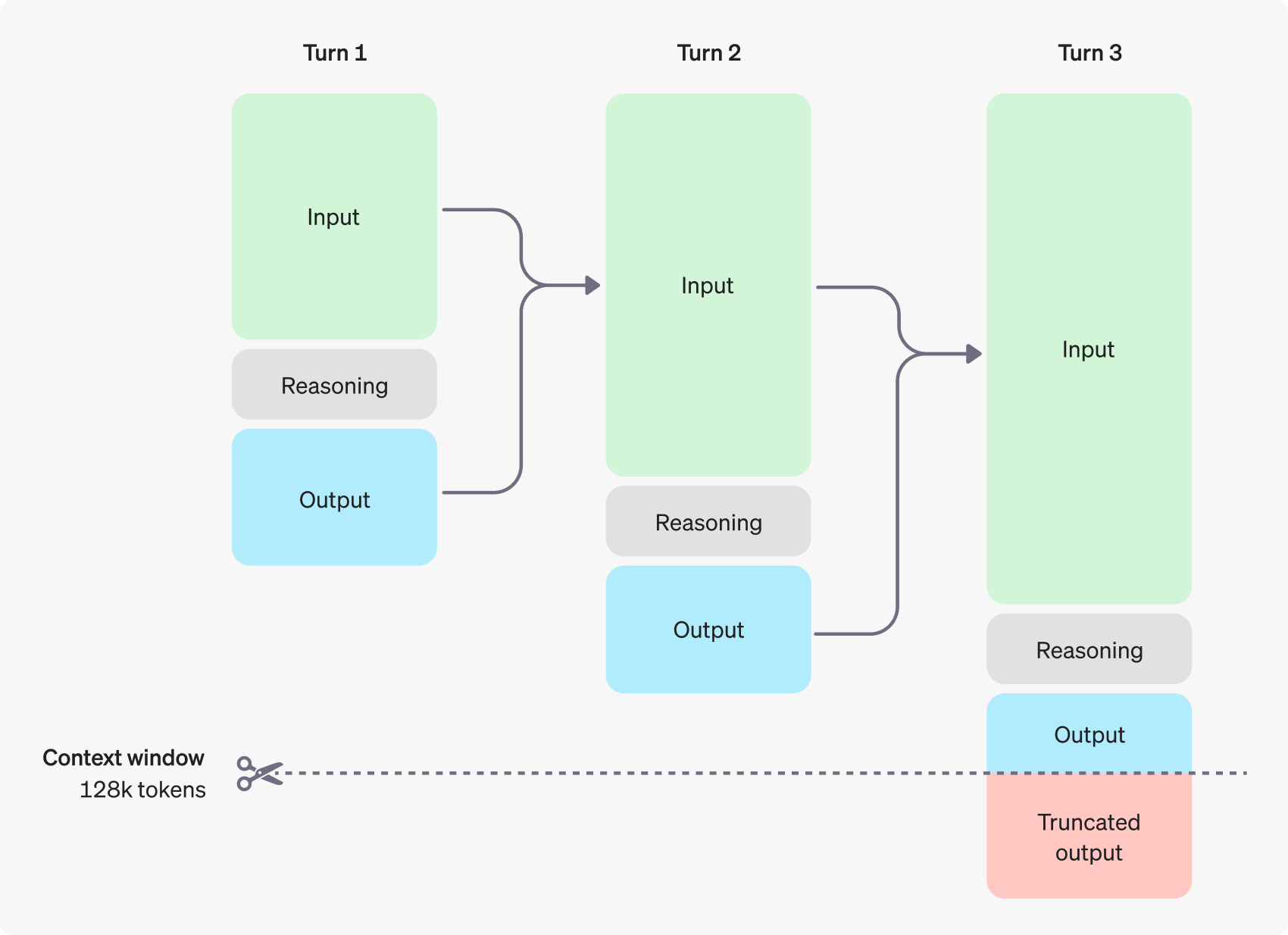
추론 토큰은 API 인터페이스를 통해 보이지 않지만 모델의 컨텍스트 창 공간을 차지하고 총 토큰 사용량에 포함되며, 출력 토큰과 마찬가지로 비용을 지불해야 한다는 점에 유의할 필요가 있습니다. 따라서 실제로 개발자는 추론 토큰의 영향을 고려하고 모델의 컨텍스트 창과 토큰 소비를 적절하게 관리해야 합니다.
상황에 맞는 창 관리: 모델에 충분한 '생각할 공간' 보장
완료 요청을 생성할 때 컨텍스트 창에 모델이 생성한 추론 토큰을 위한 충분한 공간이 있는지 확인하는 것이 중요하며, 문제의 복잡성에 따라 모델은 수백에서 수만 개의 추론 토큰을 생성해야 할 수 있으며, 사용자는 채팅 완료 응답 개체의 사용 개체를 통해 추론 토큰을 생성할 수 있습니다. completion_tokens_details 필드에서 특정 요청에 대해 모델이 사용한 추론 토큰의 정확한 수를 확인할 수 있습니다:
{
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21,
"completion_tokens_details": {
"reasoning_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
}
}
사용자는 모델 참조 페이지에서 다양한 모델에 대한 컨텍스트 창 길이를 확인할 수 있습니다. 추론 모델이 효과적으로 작동하려면 컨텍스트 윈도우를 적절히 평가하고 관리하는 것이 필수적입니다.
비용 관리: 토큰 소비 미세 조정 및 최적화
추론 모델의 비용을 효과적으로 관리하기 위해 사용자는 다음을 사용할 수 있습니다. max_completion_tokens 매개변수를 설정하여 추론 토큰과 보완 토큰을 포함하여 모델에서 생성되는 총 토큰 수를 제한할 수 있습니다.
이전 모델에서는max_tokens 이 매개변수는 모델에서 생성되는 토큰 수와 사용자에게 표시되는 토큰 수를 모두 제어하며, 이는 항상 동일합니다. 그러나 추론 모델의 경우 내부 추론 토큰의 도입으로 인해 모델에서 생성되는 총 토큰 수가 사용자에게 최종적으로 표시되는 토큰 수를 초과할 수 있습니다.
일부 애플리케이션은 다음에 의존할 수 있습니다. max_tokens 매개변수가 API가 반환한 토큰 수와 일치하는 경우, OpenAI는 특별한 max_completion_tokens 매개변수를 사용하여 추론 토큰과 사용자가 볼 수 있는 보완 토큰을 포함하여 모델에서 생성되는 총 토큰 수를 보다 명시적으로 제어할 수 있으며, 이러한 명시적인 매개변수 설정은 새 모델을 사용하는 기존 애플리케이션의 원활한 전환을 보장하여 잠재적인 호환성 문제를 방지합니다. 모든 이전 모델의 경우max_tokens 매개변수의 기능은 변경되지 않습니다.
추론을 위한 공간 허용: '생각'을 방해하지 않기
생성된 토큰 수가 컨텍스트 창 제한 또는 사용자가 설정한 토큰 수에 도달하면 max_completion_tokens 값으로 설정하면 API는 채팅 완료 응답을 반환합니다. finish_reason 필드는 다음과 같이 설정됩니다. length. 이는 모델이 사용자에게 보이는 보완 토큰을 생성하기 전에 발생할 수 있으며, 이는 사용자가 입력 토큰과 추론 토큰에 대한 비용을 지불해야 하지만 궁극적으로 눈에 보이는 응답을 받지 못할 수 있음을 의미합니다.
위와 같은 문제를 방지하려면 항상 컨텍스트 창에 충분한 공간이 확보되어 있는지 확인하거나 max_completion_tokens 매개변수를 더 높은 값으로 조정합니다. 이러한 추론 모델을 처음 시도할 때는 추론 및 출력 프로세스를 위해 최소 25,000개의 토큰을 위한 공간을 확보할 것을 권장합니다. 사용자가 프롬프트에 필요한 추론 토큰의 수에 익숙해지면 이 버퍼 크기를 적절히 조정하여 보다 세분화된 비용 관리를 할 수 있습니다.
팁 제안: 추론 모델의 잠재력 활용하기
추론 모델과 GPT 모델에 대한 메시지를 표시할 때 사용자가 알아야 할 몇 가지 주요 차이점이 있습니다. 전반적으로 추론 모델은 높은 수준의 안내만 제공되는 작업에서 더 나은 결과를 제공하는 경향이 있습니다. 이는 일반적으로 매우 정확한 지침을 받을 때 더 나은 성과를 내는 GPT 모델과는 대조적입니다.
- 숙련된 선배 동료와 같은 추론 모델 -- 사용자가 달성하고자 하는 목표를 말하기만 하면 구체적인 세부 사항을 자율적으로 해결할 수 있습니다.
- GPT 모델은 주니어 비서와 비슷합니다. -- 특정 결과물을 만들기 위한 명확하고 자세한 지침이 있을 때 가장 효과적입니다.
추론 모델 사용 모범 사례에 대해 자세히 알아보려면 공식 OpenAI 가이드를 참조하세요.
팁 예시: 애플리케이션 시나리오 데모
코딩(코드 리팩토링)
OpenAI의 o 시리즈 모델은 강력한 알고리즘 이해와 코드 생성 기능을 보여줍니다. 다음 예는 o1 모델을 사용하여 특정 기준에 맞게 리팩터링하는 방법을 보여줍니다. React 컴포넌트.
리팩터링 코드
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
指令:
- 给定以下 React 组件,修改它,使非小说类书籍显示红色文本。
- 回复中仅返回代码
- 不要包含任何额外的格式,例如 markdown 代码块
- 对于格式,使用四个空格缩进,并且不允许任何代码行超过 80 列
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
`.trim();
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
},
],
});
console.log(completion.usage.completion_tokens_details);
from openai import OpenAI
client = OpenAI();
prompt = """
指令:
- 给定以下 React 组件,修改它,使非小说类书籍显示红色文本。
- 回复中仅返回代码
- 不要包含任何额外的格式,例如 markdown 代码块
- 对于格式,使用四个空格缩进,并且不允许任何代码行超过 80 列
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
코드(프로젝트 계획)
OpenAI의 o 시리즈 모델은 다단계 프로젝트 계획을 개발하는 데도 효과적입니다. 다음 예는 o1 모델을 사용하여 Python 애플리케이션을 위한 완전한 파일 시스템 구조를 만들고 필요한 기능을 구현하는 Python 코드를 생성하는 방법을 보여줍니다.
Python 프로젝트 계획 및 생성
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
我想构建一个 Python 应用程序,它可以接收用户的问题,并在数据库中查找答案。
数据库中存储了问题到答案的映射关系。如果找到密切匹配的问题,则检索匹配的答案。
如果没有找到,则要求用户提供答案,并将问题/答案对存储在数据库中。
为我创建一个目录结构计划,我需要这个结构,然后完整地返回每个文件中的代码。
只在开头和结尾提供你的推理过程,不要在代码中穿插推理。
`.trim();
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
},
],
});
console.log(completion.usage.completion_tokens_details);
from openai import OpenAI
client = OpenAI();
prompt = """
我想构建一个 Python 应用程序,它可以接收用户的问题,并在数据库中查找答案。
数据库中存储了问题到答案的映射关系。如果找到密切匹配的问题,则检索匹配的答案。
如果没有找到,则要求用户提供答案,并将问题/答案对存储在数据库中。
为我创建一个目录结构计划,我需要这个结构,然后完整地返回每个文件中的代码。
只在开头和结尾提供你的推理过程,不要在代码中穿插推理。
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
STEM 연구
OpenAI의 o 시리즈 모델은 STEM(과학, 기술, 공학 및 수학) 연구에서 뛰어난 성능을 입증했습니다. 이러한 모델은 기초 연구 과제를 지원하기 위해 설계된 프롬프트에서 종종 인상적인 결과를 제공합니다.
기초 과학 연구와 관련된 문제 제기
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
为了推进新型抗生素的研究,我们应该考虑研究哪三种化合物?
为什么我们应该考虑它们?
`;
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
}
],
});
console.log(completion.choices[0].message.content);
from openai import OpenAI
client = OpenAI();
prompt = """
为了推进新型抗生素的研究,我们应该考虑研究哪三种化合物?
为什么我们应该考虑它们?
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
공식 예시
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...