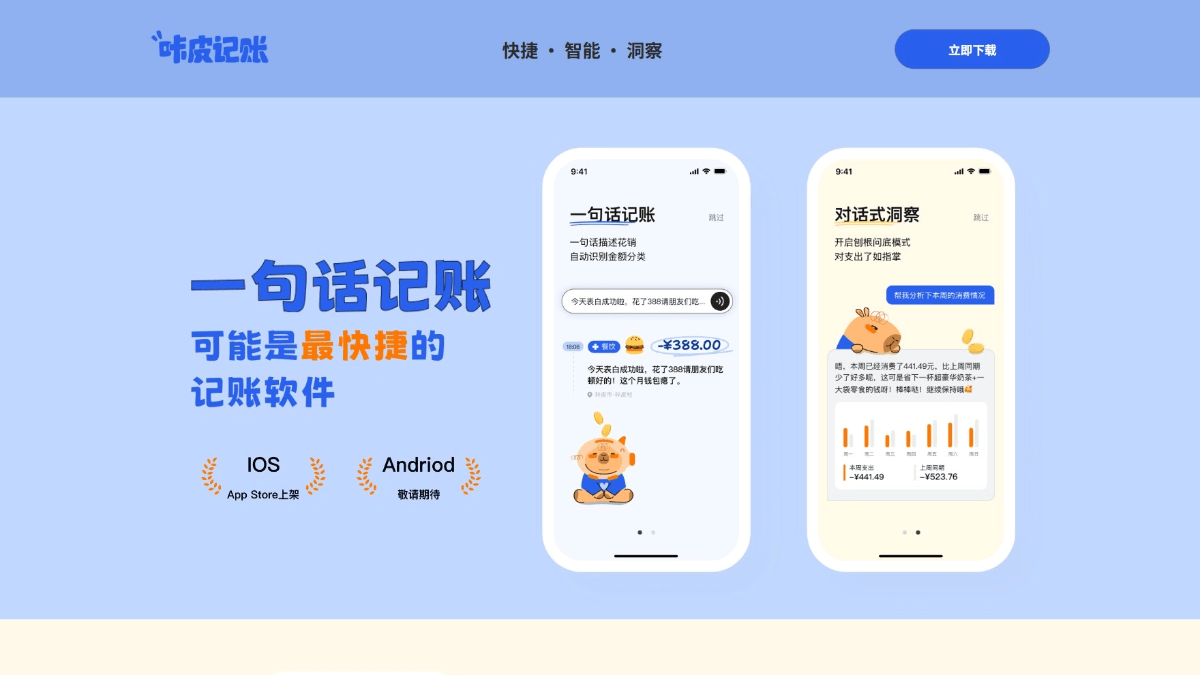

일반 소개
오픈 딥 리서치는 모든 주제에 대한 종합적인 리서치 보고서를 생성하는 웹 기반 리서치 도우미입니다. 이 시스템은 사용자가 시간이 많이 소요되는 연구 단계로 넘어가기 전에 보고서 구조를 계획하고 검토할 수 있는 계획 후 실행 워크플로우를 사용합니다. 사용자는 개인의 필요에 따라 다양한 계획 모델, 검색 API, Tavily, Perplexity, Anthropic, OpenAI 등의 작성 모델 중에서 선택할 수 있으며, Open Deep Research는 보고서의 깊이와 정확성을 보장하기 위해 여러 번의 반영 및 검색 반복을 지원합니다. 사용자는 간단한 구성 파일과 명령줄 작업을 통해 도구를 빠르게 배포하고 사용할 수 있습니다.

기능 목록
- 보고서의 구조에 대한 개요를 제공합니다.
- 계획 모델 설정(예: DeepSeek, OpenAI 추론 모델 등)
- 보고서의 각 섹션에 대한 계획에 피드백을 주고 사용자가 만족할 때까지 반복합니다.
- 검색 API(예: 타빌리, 퍼플렉시티) 및 연구 반복당 검색 횟수 설정하기
- 각 섹션에 대한 검색 깊이(반복 횟수) 설정하기
- 사용자 지정 글쓰기 모델(예: Anthropic)
- 로컬에서 LangGraph Studio UI 실행
- 구조화된 연구 보고서 자동 생성
- 다중 검색 및 반사적 반복을 지원하여 보고서 품질 향상
도움말 사용
빠른 시작
- 필요한 도구의 API 키가 설정되었는지 확인합니다.
- 웹 검색 도구를 선택합니다(기본적으로 Tavily가 사용됨):
- 쓰기 모델 선택(기본적으로 Anthropic이 사용됨) Claude 3.5 소네트):
- 플래닝 모델을 선택합니다(기본적으로 OpenAI o3-mini가 사용됨):
- OpenAI
- Groq
사용법
가상화 환경
- 가상 환경을 만듭니다:
python -m venv open_deep_research source open_deep_research/bin/activate
- 설치:
pip install open-deep-research
다음에서 주피터 노트북 사용
- 차트를 가져와서 컴파일합니다:
from langgraph.checkpoint.memory import MemorySaver from open_deep_research.graph import builder memory = MemorySaver() graph = builder.compile(checkpointer=memory) - 차트 보기:
from IPython.display import Image, display display(Image(graph.get_graph(xray=1).draw_mermaid_png())) - 차트를 실행합니다:
import uuid thread = {"configurable": {"thread_id": str(uuid.uuid4()), "search_api": "tavily", "planner_provider": "openai", "planner_model": "o3-mini", "writer_provider": "anthropic", "writer_model": "claude-3-5-sonnet-latest", "max_search_depth": 1, }} topic = "Overview of the AI inference market with focus on Fireworks, Together.ai, Groq" async for event in graph.astream({"topic":topic,}, thread, stream_mode="updates"): print(event) print("\n") - 보고서 계획을 생성한 후 피드백을 제출하여 보고서 계획을 업데이트합니다:
from langgraph.types import Command async for event in graph.astream(Command(resume="Include a revenue estimate (ARR) in the sections"), thread, stream_mode="updates"): print(event) print("\n") - 보고 체계에 만족할 때 제출
True를 클릭하여 보고서를 생성합니다:async for event in graph.astream(Command(resume=True), thread, stream_mode="updates"): print(event) print("\n")
로컬에서 LangGraph Studio UI 실행
- 복제 창고:
git clone https://github.com/langchain-ai/open_deep_research.git cd open_deep_research - 컴파일러
.env파일을 사용하여 API 키를 설정합니다:cp .env.example .env - 환경 변수 설정하기:
export TAVILY_API_KEY=<your_tavily_api_key> export ANTHROPIC_API_KEY=<your_anthropic_api_key> export OPENAI_API_KEY=<your_openai_api_key> - LangGraph 서버를 시작합니다:
- Mac:
curl -LsSf https://astral.sh/uv/install.sh | sh uvx --refresh --from "langgraph-cli[inmem]" --with-editable . --python 3.11 langgraph dev - Windows:
pip install -e . pip install langgraph-cli[inmem] langgraph dev
- Mac:
- Studio UI를 엽니다:
- 🚀 API: http://127.0.0.1:2024 - 🎨 Studio UI: https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:2024 - 📚 API Docs: http://127.0.0.1:2024/docs
사용자 지정 보고서
report_structure:: 사용자 지정 보고서 구조 정의(기본적으로 표준 리서치 보고서 형식이 사용됨)number_of_queries:: 섹션당 생성되는 검색 쿼리 수(기본값: 2)max_search_depth최대 검색 깊이(기본값: 2)planner_provider:: 계획 단계용 모델링 공급자(기본값: "openai", 선택 사항 "groq")planner_model:: 계획에 사용되는 특정 모델(기본값: "o3-mini", 선택적으로 "deepseek-r1-distill-llama-70b").writer_model:: 보고서 작성에 사용된 모델(기본값: "claude-3-5-sonnet-latest")search_api: 검색 API 사용(기본값: Tavily)
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...