
다국어 ASR이란 무엇인가요?
다국어 ASR은 Meta의 다국어 음성 인식 프레임워크로 1600개 이상의 언어를 지원하며 문자 오류율은 101 TP3T 이하인 781 TP3T입니다. 70억 개의 파라미터를 가진 wav2vec 2.0 인코더와 CTC 및 Transformer 디코더가 결합되어 보이지 않는 언어의 제로 샘플 전사를 지원하며 새로운 언어에 적응하기 위해 몇 개의 샘플만 필요합니다. 언어. 이 모델은 오픈 소스이며 350개의 저자원 언어 말뭉치를 포함하고 있어 전 세계적으로 멸종 위기에 처한 언어의 디지털화와 음성 기술 도입을 촉진합니다.
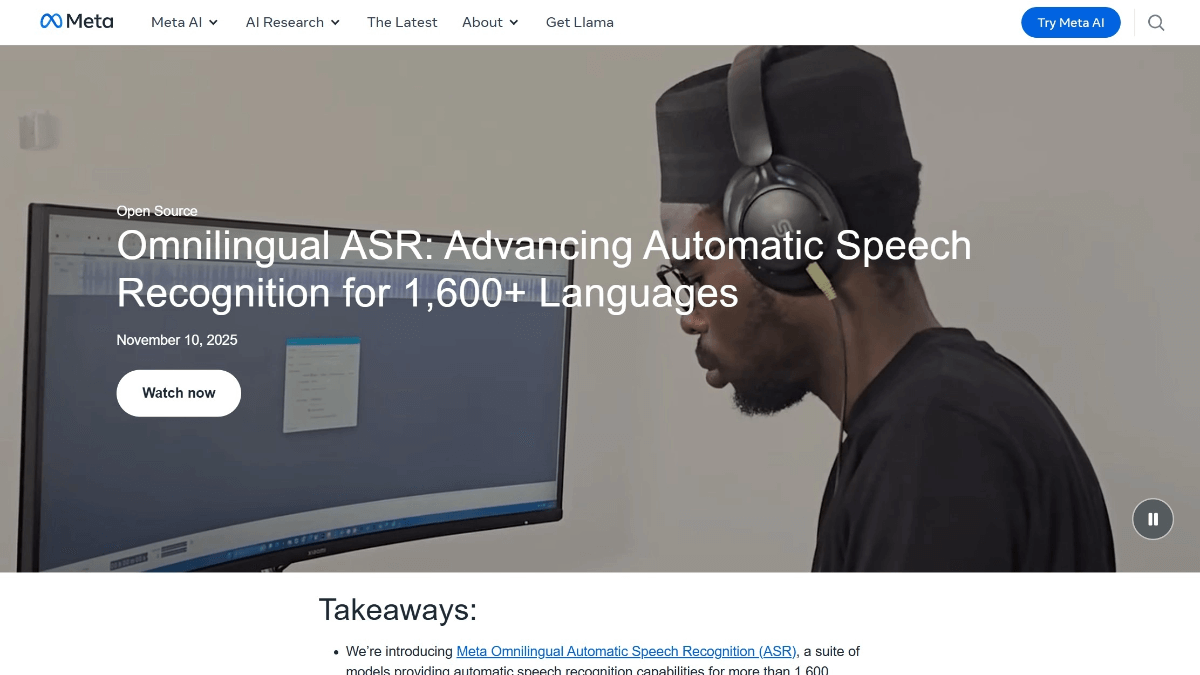
다국어 ASR의 특징
- 다국어 지원1,600개 이상의 언어를 지원하며, 저자원 및 멸종 위기에 처한 언어까지 폭넓게 지원하여 음성 인식의 글로벌 언어 범위를 크게 개선합니다.
- 낮은 리소스 언어 지원자가 지도 학습 및 데이터 향상 기술을 통해 리소스가 부족한 언어의 희박한 데이터 문제를 효과적으로 해결하고 음성 인식의 임계값을 낮춥니다.
- 제로 샘플 학습 기능대규모 말뭉치 없이도 적은 수의 예시만으로 새로운 언어를 전사할 수 있으므로 언어 커버리지를 크게 확장할 수 있습니다.
- 고성능 아키텍처CTC 및 트랜스포머 디코더와 결합된 wav2vec 2.0 인코더는 높은 정확도와 고성능 음성 인식을 지원합니다.
- 오픈 소스 및 협업전 세계 개발자와 연구자들이 음성 인식 기술을 발전시키고 멸종 위기에 처한 언어 보존을 위해 협력할 수 있도록 지원하는 오픈 소스 모델 및 데이터 세트입니다.
다국어 ASR의 핵심 이점
- 광범위한 언어 지원저자원 및 멸종 위기 언어를 포함하여 1,600개 이상의 언어를 지원하여 음성 인식의 글로벌 언어 범위를 크게 개선합니다.
- 제로 샘플 학습 기능몇 개의 오디오 및 텍스트 샘플만으로 보이지 않는 언어를 전사하면 새로운 언어를 개발하는 데 드는 비용을 크게 줄일 수 있습니다.
- 고성능 아키텍처70억 개의 파라미터를 가진 wav2vec 2.0 인코더와 고급 디코더를 자체 지도 학습과 결합하여 고정밀 음성 인식을 달성합니다.
- 오픈 소스 및 커뮤니티 지원기술 개발 및 언어 보존을 발전시키기 위해 전 세계 개발자와 연구자의 참여를 촉진하는 모델 및 데이터 세트의 오픈 소스입니다.
- 혁신적인 데이터 향상 기술모델의 일반화 능력을 향상시키기 위해 합성 음성 등의 기술을 통해 희소성이 낮은 언어 데이터의 문제를 해결합니다.
- 유연한 디코더 선택다양한 시나리오의 성능 및 효율성 요구 사항을 충족하기 위해 CTC 및 트랜스포머 디코더 옵션을 모두 제공합니다.
다국어 ASR의 공식 웹사이트는 무엇인가요?
- 프로젝트 웹사이트:: https://ai.meta.com/blog/omnilingual-asr-advancing-automatic-speech-recognition/
- GitHub 리포지토리:: https://github.com/facebookresearch/omnilingual-asr
- 허깅페이스 모델 라이브러리:: https://huggingface.co/datasets/facebook/omnilingual-asr-corpus
- 기술 문서:: https://ai.meta.com/research/publications/omnilingual-asr-open-source-multilingual-speech-recognition-for-1600-languages/
다국어 ASR의 대상
- 언어 연구원자원이 부족하고 멸종 위기에 처한 언어를 연구하고 언어 보존 및 언어 연구를 지원하는 데 사용할 수 있습니다.
- 기술 개발자오픈 소스 특성을 활용하여 2차 개발 및 통합을 위한 음성 인식 애플리케이션을 개발하는 데 적합합니다.
- 콘텐츠 크리에이터다국어 오디오 및 비디오 콘텐츠 제작을 용이하게 하여 빠른 트랜스크립션 및 자막 생성이 가능합니다.
- 교육자언어 교육 및 문화 간 커뮤니케이션을 지원하기 위한 다국어 교육 리소스 개발을 지원합니다.
- 비즈니스 사용자고객 서비스, 회의 녹음 및 기타 시나리오와 같이 다국어 음성 인식 서비스가 필요한 기업에 적합합니다.
- 커뮤니티 및 비영리 단체언어 다양성 프로그램을 지원하고 문화 교류 및 언어 보존을 촉진하는 데 사용할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...