
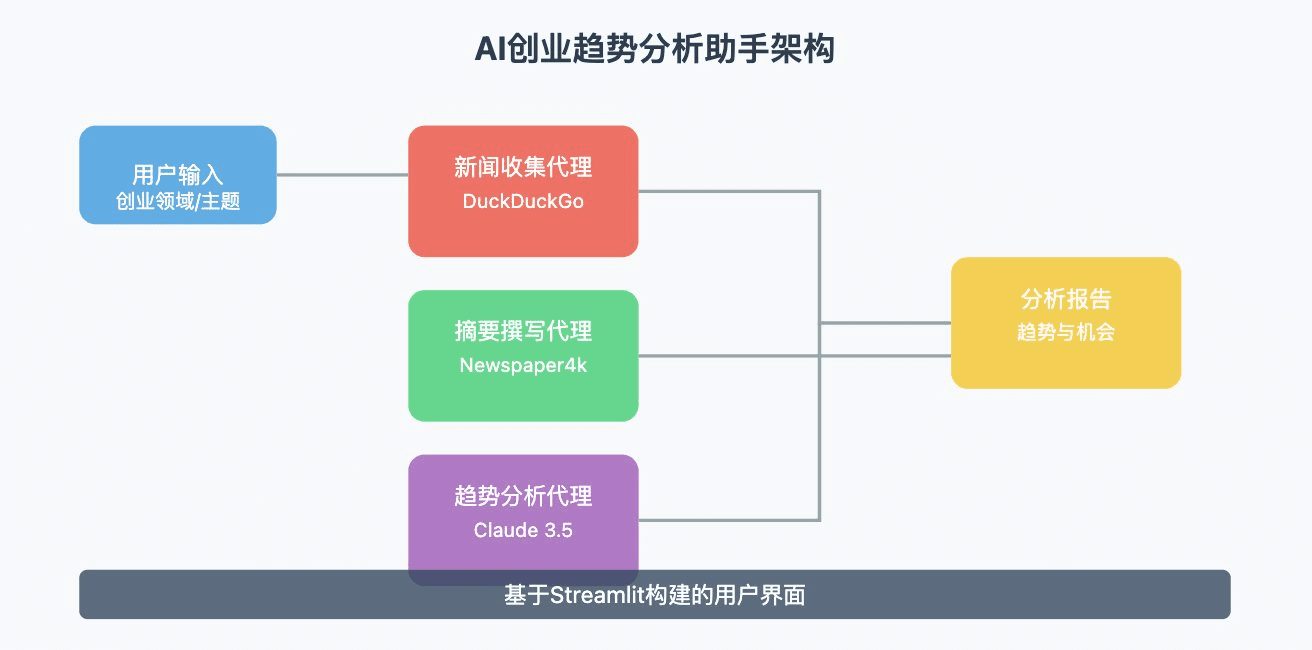
LangChain의 올라마 - 파이썬 통합

개요
이 문서에서는 Ollama LangChain과 통합하여 강력한 AI 애플리케이션을 생성하세요.Ollama는 대규모 언어 모델을 위한 오픈 소스 배포 도구이며, LangChain은 언어 모델 기반 애플리케이션을 구축하기 위한 프레임워크입니다. 이 두 가지를 결합하면 로컬 환경에서 고급 AI 모델을 신속하게 배포하고 사용할 수 있습니다.
참고: 이 문서에는 핵심 코드 스니펫과 자세한 설명이 포함되어 있습니다. 전체 코드는이 주피터 노트북발견됨.
1. 환경 설정
Conda 환경 구성
먼저 Jupyter에서 Conda 환경을 사용해야 합니다. 명령줄에서 다음 명령을 실행합니다:
conda create -n handlm python=3.10 -y
conda activate handlm
pip install jupyter
python -m ipykernel install --user --name=handlm
실행 후 Jupyter를 다시 시작하고 그림과 같이 해당 환경의 커널을 선택합니다:

⚠️ 참고
주의: 콘다 가상 환경 없이도 글로벌 환경을 직접 사용할 수도 있습니다.
종속성 설치
시작하기 전에 다음 패키지를 설치해야 합니다:
langchain-ollamaOllama 모델을 LangChain 프레임워크에 통합하기 위해langchainAI 애플리케이션 구축을 위한 도구와 추상화를 제공하는 LangChain의 핵심 라이브러리입니다.langchain-community커뮤니티에서 기여한 다양한 통합 및 도구 포함Pillow: 멀티 모달 작업에 사용되는 이미지 처리용faiss-cpu간단한 구축용 RAG 리트리버
다음 명령어로 설치할 수 있습니다:
pip install langchain-ollama langchain langchain-community Pillow faiss-cpu
2. 필요한 모델을 다운로드하고 OllamaLLM을 초기화합니다.
llama3.1 모델 다운로드
- 공식 웹사이트 https://ollama.com/download 로 이동하여 지원되는 플랫폼에서 Ollama를 다운로드하여 설치하세요.
- 사용 가능한 모든 모델은 https://ollama.ai/library 에서 확인하세요.
- 통과(청구서 또는 검사 등)
ollama pull <name-of-model>명령을 사용하여 사용 가능한 LLM 모델을 가져옵니다(예ollama pull llama3.1).
명령줄은 그림과 같이 실행됩니다:

모델 저장 위치:
- Mac.
~/.ollama/models/ - Linux(또는 WSL).
/usr/share/ollama/.ollama/models - Windows.
C:\Users\Administrator\.ollama\models
3. 기본 사용 예
ChatPromptTemplate을 사용하여 대화 진행하기
ChatPromptTemplate을 사용하면 하나 이상의 매개변수가 포함된 재사용 가능한 템플릿을 만들 수 있습니다. 이러한 매개변수는 런타임에 동적으로 교체하여 다양한 프롬프트를 생성할 수 있습니다.
template = """
你是一个乐于助人的AI,擅长于解决回答各种问题。
问题:{question}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = prompt | model
chain.invoke({"question": "你比GPT4厉害吗?"})
체인 생성 섹션에서 파이프 연산자를 사용합니다. |프롬프트를 모델에 연결하여 처리 흐름을 형성합니다. 이러한 연쇄를 통해 다양한 구성 요소를 쉽게 결합하고 재사용할 수 있습니다.
invoke 메서드는 전체 처리 체인을 트리거하여 질문을 템플릿에 전달한 다음 형식이 지정된 프롬프트를 모델에 전송하여 처리합니다.
스트리밍 출력
스트리밍 출력은 긴 텍스트를 생성하면서 결과를 점진적으로 반환하는 기술입니다. 이 방법에는 몇 가지 중요한 장점이 있습니다:
- 사용자 환경 개선: 사용자는 전체 응답이 완료될 때까지 기다리지 않고 부분적인 결과를 즉시 확인할 수 있습니다.
- 대기 시간 단축: 긴 답변의 경우 전체 답변이 생성되기 전에 사용자가 읽기를 시작할 수 있습니다.
- 실시간 상호 작용: 생성 프로세스 중에 개입하거나 종료할 수 있습니다.
실제로, 특히 챗봇이나 실시간 대화 시스템에서 스트리밍 출력은 거의 필수적입니다.
from langchain_ollama import ChatOllama
model = ChatOllama(model="llama3.1", temperature=0.7)
messages = [
("human", "你好呀"),
]
for chunk in model.stream(messages):
print(chunk.content, end='', flush=True)
model.stream() 메서드는 Ollama API의 스트리밍 출력 인터페이스를 둘러싼 래퍼로, 제너레이터 객체를 반환합니다. 호출할 때 model.stream(messages) 이렇게 하면 다음 작업이 완료됩니다:
- Ollama API에 요청을 보내 응답 생성을 시작합니다.
- API는 텍스트 생성을 시작하지만 텍스트가 모두 생성될 때까지 기다리지 않고 작은 덩어리로 반환합니다.
- 작은 문자가 수신될 때마다
stream()메서드는 텍스트 블록을 생성합니다. flush=True버퍼가 채워질 때까지 기다리지 말고 각 클립이 즉시 표시되도록 하세요.
도구 호출
도구 호출은 AI 모델이 외부 함수 또는 API와 상호 작용할 수 있는 기능입니다. 이를 통해 모델은 수학적 계산, 데이터 쿼리 또는 외부 서비스 호출과 같은 복잡한 작업을 수행할 수 있습니다.
def simple_calculator(operation: str, x: float, y: float) -> float:
'''实际的代码处理逻辑'''
llm = ChatOllama(
model="llama3.1",
temperature=0,
).bind_tools([simple_calculator])
result = llm.invoke("你知道一千万乘二是多少吗?")
bind_tools 메서드를 사용하면 사용자 정의 함수를 모델에 등록할 수 있습니다. 이렇게 하면 모델이 계산이 필요한 문제에 직면했을 때 사전 학습 지식에 의존하지 않고 이 함수를 호출하여 정확한 결과를 얻을 수 있습니다.
이 기능은 예를 들어 복잡한 AI 애플리케이션을 구축할 때 유용합니다:
- 실시간 데이터에 액세스할 수 있는 챗봇 만들기
- 특정 작업(예: 예약, 문의 등)을 수행하는 지능형 어시스턴트를 구축하세요.
- 정밀한 계산이나 복잡한 작업을 수행할 수 있는 AI 시스템 개발
멀티모달 모델
멀티모달 모델은 여러 유형의 입력(예: 텍스트, 이미지, 오디오 등)을 처리할 수 있는 AI 모델로, Ollama는 바클라바 및 라바와 같은 멀티모달 모델을 지원합니다. 이러한 모델은 크로스 모달 콘텐츠를 이해하고 생성하는 데 탁월하여 보다 복잡하고 자연스러운 인간과 컴퓨터 간의 상호 작용을 가능하게 합니다.
먼저 멀티모달 모델을 다운로드해야 합니다. 명령줄에서 실행합니다:
ollama pull llava

그런 다음 다음 코드를 사용하여 이미지 및 텍스트 입력을 처리할 수 있습니다:
from langchain_ollama import ChatOllama
from langchain_core.messages import HumanMessage
from langchain_core.output_parsers import StrOutputParser
llm = ChatOllama(model="llava", temperature=0)
def prompt_func(data):
'''构造多模态输入'''
chain = prompt_func | llm | StrOutputParser()
query_chain = chain.invoke(
{"text": "这个图片里是什么动物啊?", "image": image_b64}
)
여기서 핵심은 다음과 같습니다:
- 이미지 전처리: 이미지를 base64로 인코딩된 문자열로 변환해야 합니다.
- 힌트 기능:
prompt_func텍스트와 이미지가 포함된 멀티모달 입력이 생성됩니다. - 연결: 다음을 사용합니다.
|연산자는 힌트 함수, 모델, 출력 구문 분석기를 연결합니다.
예를 들어 멀티모달 모델은 여러 시나리오에서 유용합니다:
- 이미지 설명 생성
- 시각적 질문 및 답변 시스템
- 이미지 기반 콘텐츠 분석 및 추천
4. 고급 사용법
컨버세이션체인을 사용한 대화
ConversationChain 는 다자간 대화를 관리하기 위해 LangChain에서 제공하는 강력한 도구입니다. 언어 모델, 프롬프트 템플릿, 인메모리 구성 요소를 결합하여 컨텍스트 인식 대화 시스템을 쉽게 만들 수 있습니다.
memory = ConversationBufferMemory()
conversation = ConversationChain(
llm=model,
memory=memory,
verbose=True
)
# 进行对话
response = conversation.predict(input="你好,我想了解一下人工智能。")
print("AI:", response)
response = conversation.predict(input="能给我举个AI在日常生活中的应用例子吗?")
print("AI:", response)
response = conversation.predict(input="这听起来很有趣。AI在医疗领域有什么应用?")
print("AI:", response)
여기서 핵심 요소는 다음과 같습니다:
ConversationBufferMemory이전의 모든 대화 기록을 저장하는 간단한 인메모리 구성 요소입니다.ConversationChain언어 모델, 메모리 및 기본 대화 프롬프트 템플릿을 결합합니다.
대화 기록을 유지하는 것은 모델을 허용하기 때문에 중요합니다:
- 컨텍스트 및 앞서 언급한 정보 이해
- 보다 일관성 있고 관련성 높은 응답 생성
- 복잡한 다라운드 대화 시나리오 처리하기
실제로는 다음과 같은 고급 메모리 컴포넌트 사용을 고려해야 할 수 있습니다. ConversationSummaryMemory를 사용하여 긴 대화를 처리하고 모델의 컨텍스트 길이 제한을 초과하지 않도록 합니다.
사용자 지정 프롬프트 템플릿
잘 디자인된 프롬프트 템플릿은 효율적인 AI 애플리케이션을 만드는 데 있어 핵심입니다. 이 예제에서는 제품 설명을 생성하기 위한 복잡한 프롬프트를 만들었습니다:
system_message = SystemMessage(content="""
你是一位经验丰富的电商文案撰写专家。你的任务是根据给定的产品信息创作吸引人的商品描述。
请确保你的描述简洁、有力,并且突出产品的核心优势。
""")
human_message_template = """
请为以下产品创作一段吸引人的商品描述:
产品类型: {product_type}
核心特性: {key_feature}
目标受众: {target_audience}
价格区间: {price_range}
品牌定位: {brand_positioning}
请提供以下三种不同风格的描述,每种大约50字:
1. 理性分析型
2. 情感诉求型
3. 故事化营销型
"""
# 示例使用
product_info = {
"product_type": "智能手表",
"key_feature": "心率监测和睡眠分析",
"target_audience": "注重健康的年轻专业人士",
"price_range": "中高端",
"brand_positioning": "科技与健康的完美结合"
}
이 구조에는 몇 가지 중요한 디자인 고려 사항이 있습니다:
- 시스템_프롬프트: AI의 역할과 전반적인 작업을 정의하여 전체 대화의 분위기를 설정합니다.
- 인간_메시지_템플릿: 특정 지침 및 필수 메시지의 구조를 제공합니다.
- 다중 매개변수 설계: 다양한 제품 및 요구사항에 유연하게 대응할 수 있습니다.
- 다양성 출력 요구 사항: 다양한 스타일의 설명을 요구하여 모델이 다양성을 보여줄 수 있도록 장려합니다.
효과적인 프롬프트 템플릿을 디자인할 때는 다음 사항을 고려하세요:
- AI의 역할과 사명을 명확하게 정의하기
- 명확하고 구조화된 입력 형식 제공
- 구체적인 출력 요구 사항 및 서식 지정 지침이 포함되어 있습니다.
- 모델의 용량과 창의성을 극대화하는 방법을 고려하세요.
간단한 RAG Q&A 시스템 구축
RAG(검색 증강 생성)는 검색과 생성을 결합하여 관련 정보를 검색함으로써 언어 모델의 답변 능력을 증강하는 AI 기법으로, RAG 시스템의 워크플로에는 일반적으로 다음 단계가 포함됩니다:
- 지식창고 문서를 청크로 분할하고 벡터 인덱스 만들기
- 사용자의 문제를 벡터화하고 색인에서 관련 문서를 검색하세요.
- 검색된 관련 문서를 원래 질문과 함께 컨텍스트로 언어 모델에 제공하세요.
- 언어 모델은 검색된 정보를 기반으로 응답을 생성합니다.
RAG의 장점은 언어 모델이 최신의 전문 정보에 액세스하고 착각을 줄이며 응답의 정확성과 관련성을 향상시키는 데 도움이 된다는 점입니다.
LangChain은 올라마 모델과 원활하게 통합할 수 있는 다양한 구성 요소를 제공합니다. 여기서는 Ollama 모델을 벡터 스토어 및 리트리버와 함께 사용하여 간단한 RAG 질문과 답변 시스템을 만드는 방법을 보여드리겠습니다.
가장 먼저 해야 할 일은 임베딩 모델이 다운로드되었는지 확인하는 것이며, 명령줄에서 다음 명령을 실행하여 이를 수행할 수 있습니다:
ollama pull nomic-embed-text
그런 다음 RAG 시스템을 구축할 수 있습니다:
# 初始化 Ollama 模型和嵌入
llm = ChatOllama(model="llama3.1")
embeddings = OllamaEmbeddings(model="nomic-embed-text")
# 准备文档
text = """
Datawhale 是一个专注于数据科学与 AI 领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。
Datawhale 以" for the learner,和学习者一起成长"为愿景,鼓励真实地展现自我、开放包容、互信互助、敢于试错和勇于担当。
同时 Datawhale 用开源的理念去探索开源内容、开源学习和开源方案,赋能人才培养,助力人才成长,建立起人与人,人与知识,人与企业和人与未来的联结。
如果你想在Datawhale开源社区发起一个开源项目,请详细阅读Datawhale开源项目指南[https://github.com/datawhalechina/DOPMC/blob/main/GUIDE.md]
"""
# 分割文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
chunks = text_splitter.split_text(text)
# 创建向量存储
vectorstore = FAISS.from_texts(chunks, embeddings)
retriever = vectorstore.as_retriever()
# 创建提示模板
template = """只能使用下列内容回答问题:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# 创建检索-问答链
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
)
# 使用链回答问题
question = "我想为datawhale贡献该怎么做?"
response = chain.invoke(question)
이 RAG 시스템은 다음과 같이 작동합니다:
- 텍스트 세분화: 사용
RecursiveCharacterTextSplitter긴 텍스트를 작은 덩어리로 분할합니다. - 벡터화 및 인덱싱: 사용
OllamaEmbeddings텍스트 블록을 벡터로 변환하고 FAISS를 사용하여 벡터 인덱스를 생성합니다. - 검색: 질문이 접수되면 시스템은 질문을 벡터화하여 FAISS 색인에서 가장 관련성이 높은 텍스트 블록을 검색합니다.
- 답변 생성: 검색된 관련 텍스트 청크가 원래 질문과 함께 언어 모델에 제공되어 최종 답변을 생성합니다.
예를 들어 RAG 시스템은 많은 실제 시나리오에서 매우 유용합니다:
- 고객 서비스: 회사의 지식 베이스를 기반으로 고객 문의에 신속하게 답변할 수 있습니다.
- 연구 지원: 연구자가 관련 문헌을 빠르게 찾고 주요 정보를 요약할 수 있도록 도와줍니다.
- 개인 비서: 개인 노트와 웹 정보를 결합해 개인화된 정보 검색과 제안을 제공합니다.
평결에 도달하기
이 예시를 통해 간단한 대화 시스템부터 복잡한 RAG Q&A 시스템까지 다양한 AI 애플리케이션을 구축하기 위해 올라마와 LangChain을 사용하는 방법을 보여드리겠습니다. 이러한 도구와 기술은 강력한 AI 애플리케이션을 개발하기 위한 탄탄한 기반을 제공합니다.
올라마와 랭체인의 조합은 개발자에게 큰 유연성과 가능성을 제공합니다. 특정 요구사항에 따라 적합한 모델과 구성 요소를 선택하고 애플리케이션 시나리오에 맞는 AI 시스템을 구축할 수 있습니다.
기술이 계속 발전함에 따라 더 많은 혁신적인 애플리케이션이 등장할 것으로 예상됩니다. 이 가이드가 AI 개발 여정을 시작하고 AI 기술의 무한한 가능성을 탐구하는 창의력을 발휘하는 데 도움이 되기를 바랍니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...