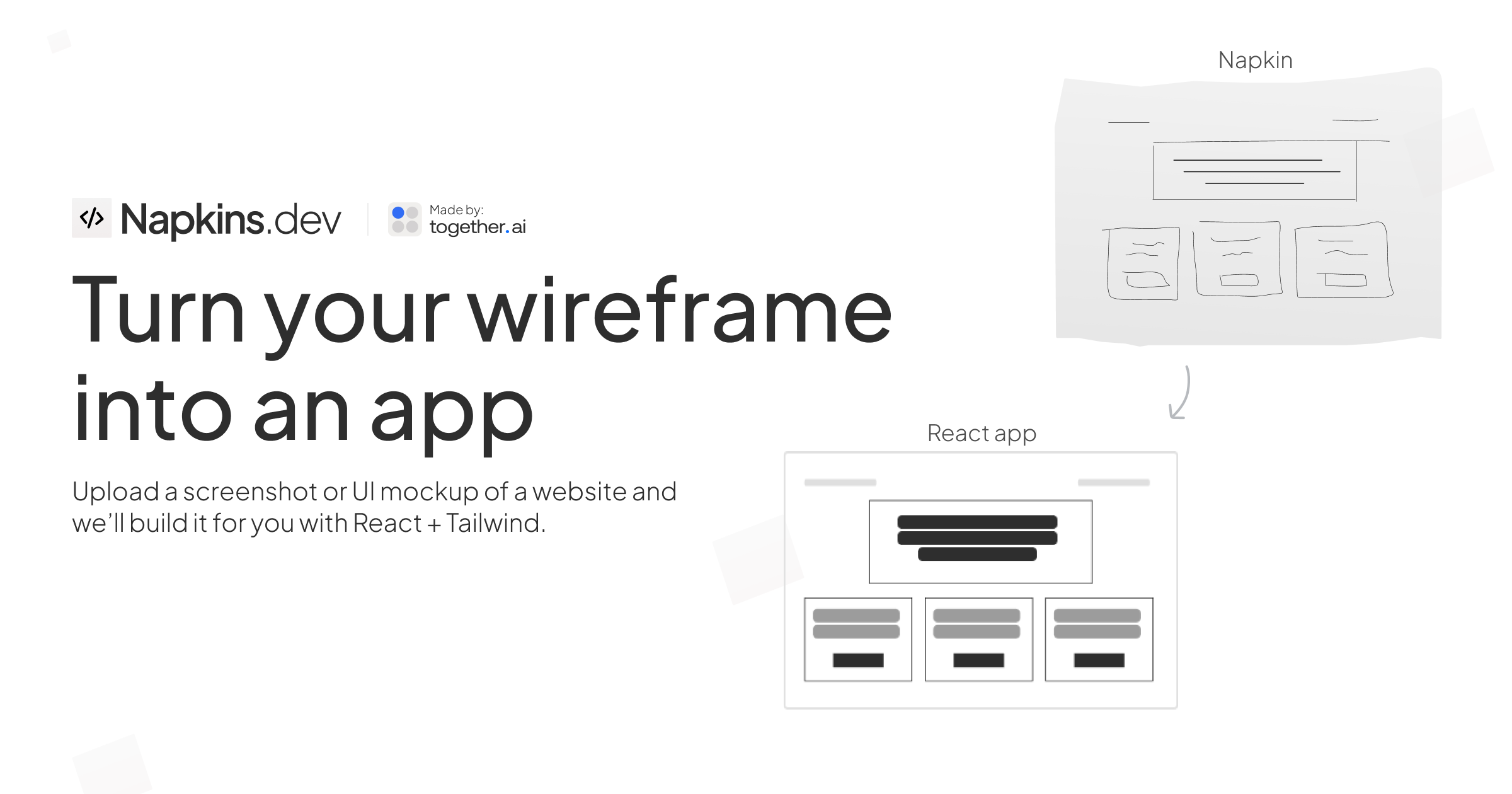

일반 소개
Ollama Ollama 플랫폼에서 제공하는 최첨단 시각 언어 모델을 사용하여 이미지에서 텍스트를 추출하는 강력한 광학 문자 인식(OCR) 툴킷입니다. 이 프로젝트는 Python 패키지와 사용자 친화적인 Streamlit 웹 애플리케이션 인터페이스로 제공됩니다. 실시간 처리를 위한 LLaVA 7B와 복잡한 문서를 위한 고정밀 라마 3.2 비전 모델 등 다양한 비전 모델을 지원하며, Ollama OCR은 마크다운, 일반 텍스트, JSON 등 광범위한 출력 형식 지원과 일괄 처리 기능으로 차별화됩니다. 이 도구는 이미지에서 텍스트 데이터를 추출하고 구조화해야 하는 개발자와 연구자에게 특히 적합합니다.

기능 목록
- 여러 고급 시각 언어 모델 지원(LLaVA 7B 및 Llama 3.2 Vision)
- 다양한 출력 형식 제공(마크다운, 일반 텍스트, JSON, 구조화된 데이터, 키-값 쌍)
- 일괄 이미지 처리 기능 지원, 여러 이미지를 병렬로 처리할 수 있습니다.
- 기본 제공 이미지 사전 처리(크기 조정, 정규화 등)
- 진행 상황 추적 및 처리 통계 제공
- 사용자 친화적인 Streamlit 웹 인터페이스 지원
- 드래그 앤 드롭 이미지 업로드 및 실시간 처리 지원
- 추출된 텍스트에 대한 다운로드 기능 제공
- 통합 이미지 미리보기 및 상세 정보 표시
도움말 사용
1. 설치 단계
- 먼저 Ollama 플랫폼을 설치해야 합니다:
- Ollama 공식 웹사이트를 방문하여 시스템에 맞는 설치 패키지를 다운로드하세요.
- Ollama의 기본 설치 완료
- 필요한 시각적 모델을 설치합니다:
ollama pull llama3.2-vision:11b
- Ollama OCR 패키지를 설치합니다:
pip install ollama-ocr
2. Python 패키지 사용법
2.1 단일 이미지 처리
from ollama_ocr import OCRProcessor
# 初始化OCR处理器
ocr = OCRProcessor(model_name='llama3.2-vision:11b')
# 处理单张图像
result = ocr.process_image(
image_path="图片路径.png",
format_type="markdown" # 可选格式:markdown, text, json, structured, key_value
)
print(result)
2.2 이미지 일괄 처리
# 初始化OCR处理器,设置并行处理数
ocr = OCRProcessor(model_name='llama3.2-vision:11b', max_workers=4)
# 批量处理图像
batch_results = ocr.process_batch(
input_path="图片文件夹路径",
format_type="markdown",
recursive=True, # 搜索子目录
preprocess=True # 启用图像预处理
)
# 查看处理结果
for file_path, text in batch_results['results'].items():
print(f"\n文件: {file_path}")
print(f"提取的文本: {text}")
# 查看处理统计
print(f"总图像数: {batch_results['statistics']['total']}")
print(f"成功处理: {batch_results['statistics']['successful']}")
print(f"处理失败: {batch_results['statistics']['failed']}")
3. Streamlit 웹 애플리케이션 사용 방법
- 코드 리포지토리를 복제합니다:
git clone https://github.com/imanoop7/Ollama-OCR.git
cd Ollama-OCR
- 종속성을 설치합니다:
pip install -r requirements.txt
- 웹 애플리케이션을 시작합니다:
cd src/ollama_ocr
streamlit run app.py
4. 출력 형식에 대한 설명
- 마크다운 서식: 제목과 목록을 포함한 텍스트 서식을 유지합니다.
- 일반 텍스트 서식: 깔끔하고 간단한 텍스트 추출 기능 제공
- JSON 형식: 구조화된 데이터 형식 출력
- 구조화된 형식: 표 및 정리된 데이터
- 키-값 쌍 형식: 레이블이 지정된 정보 추출하기
5. 주의 사항
- LLaVA 모델은 때때로 잘못된 출력을 생성할 수 있으며, 중요한 시나리오에는 Llama 3.2 Vision 모델을 사용하는 것이 좋습니다.
- 이미지 전처리를 통해 인식 정확도를 향상시킬 수 있습니다.
- 일괄 처리 시 과도한 메모리 소모를 피하기 위해 병렬 처리 수를 합리적으로 설정하는 데 주의하세요.
- 많은 수의 이미지를 처리할 때는 진행률 추적을 켜는 것이 좋습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...