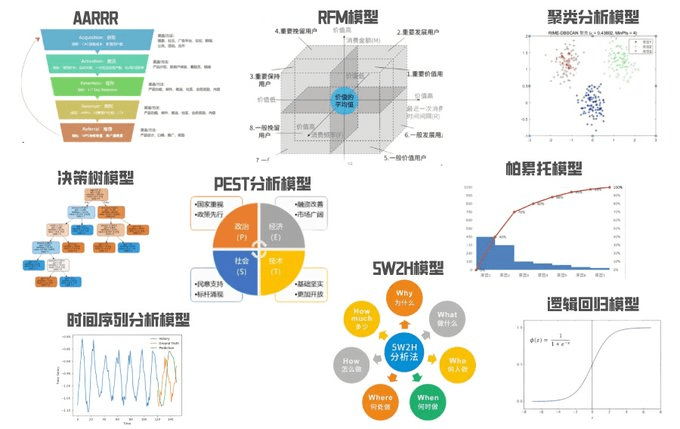
옵시디언 노트에서 언어 모델을 효과적으로 사용하기

오늘 Hacker News에서 ChatGPT와 통합되는 새로운 옵시디언용 플러그인에 관한 기사를 읽었습니다. 시중에 이런 도구가 꽤 많이 나와 있고 사람들이 다양한 방식으로 옵시디언에 적용하고 있는 것을 보게 되어 기쁩니다. 사람들이 관계를 형성하고 노트 콘텐츠에 깊이를 더하는 데 도움이 될 수 있습니다. 일부 의견은 이 도구가 사람이 직접 하던 작업을 대체할 것이라고 생각하지만, 저는 오히려 새롭고 놀라운 기능을 제공한다고 생각합니다.
노트와의 대화
가장 직접적이고 가장 중요한 방법은 노트의 내용과 대화를 나누는 것입니다. 질문을 통해 통찰력을 얻으세요. 이 모델을 노트에 직접 조준할 수 있다면 매우 편리할 것입니다. 하지만 대부분의 모델은 한 번에 모든 것을 처리할 수 없습니다.
질문이 있을 때 모든 노트가 관련성이 있는 것은 아닙니다. 관련 있는 부분을 찾아서 모델에 제출해야 하는데, 옵시디언은 검색 기능을 제공하지만 정확한 단어와 구문만 검색할 뿐, 우리가 검색해야 하는 것은 개념입니다. 이때 임베디드 인덱스가 필요합니다. 인덱스를 만드는 것은 사실 아주 간단합니다.
인덱서 구축
옵시디언 플러그인을 만들 때 시작 시 특정 작업을 수행하도록 설정한 다음, 명령을 실행하거나 노트를 열거나 다른 활동을 할 때 옵시디언에서 다른 작업을 수행하도록 설정할 수 있습니다. 따라서 플러그인이 시작하자마자 노트를 이해하고 진행 상황을 저장해 인덱스를 다시 생성할 필요가 없도록 해야 합니다. 노트의 색인을 만드는 방법을 보여주는 코드 샘플을 살펴봅시다. 여기서는 [라마 색인], [LangChain] 또한 훌륭한 선택입니다.
"llamaindex"에서 { 벡터스토어인덱스, 서비스컨텍스트프롬디폴트, 스토리지컨텍스트프롬디폴트, 마크다운리더 }를 가져옵니다;
const service_context = serviceContextFromDefaults({ chunkSize: 256 })
const storage_context = await storageContextFromDefaults({ persistDir: ". /storage" });const mdpath = process.argv[2];
const mdreader = 새 마크다운리더();
const thedoc = await mdreader.loadData(mdpath)
먼저, 인메모리 데이터 웨어하우스를 초기화해야 합니다. 이것은 라마 인덱스와 함께 제공되는 저장 시설이지만, 크로마 DB도 많이 사용됩니다. 두 번째 코드 줄은 인덱스의 모든 내용을 유지하고자 함을 나타냅니다. 다음으로 파일 경로를 가져와서 파일을 읽는 리더를 초기화합니다. Llama Index는 Markdown을 이해하므로 콘텐츠를 올바르게 읽고 색인할 수 있습니다. 또한 PDF, 텍스트 파일, Notion 문서 등을 지원합니다. 단어를 저장할 뿐만 아니라 그 단어의 의미와 텍스트의 다른 단어와의 관계도 이해합니다.
await VectorStoreIndex.fromDocuments(thedoc, { storageContext: storage_context, serviceContext: service_context });
코드의 이 부분은 OpenAI의 서비스 중 하나를 사용하지만 ChatGPT와는 별개이며 다른 모델과 제품을 사용합니다.Langchain은 조금 느리지만 로컬에서 이 작업을 수행할 수 있는 대안을 제공하며, Ollama도 임베딩을 제공합니다. 클라우드의 초고속 자체 호스팅 인스턴스에서 이러한 서비스를 사용한 다음 인덱싱이 완료되면 인스턴스를 종료할 수도 있습니다.
검색 노트
이 파일을 인덱싱했습니다. Obsidian은 모든 파일을 나열할 수 있으므로 이 프로세스를 반복해서 실행할 수 있습니다. 데이터를 보존하고 있으므로 한 번만 작업하면 됩니다. 이제 어떻게 질문할까요? 노트의 관련 부분으로 이동하여 모델에 전달하고 그 정보를 사용해 답을 구하는 코드가 필요합니다.
const storage_context = await storageContextFromDefaults({ persistDir: ". /storage" });
const index = await VectorStoreIndex.init({ storageContext: storage_context });
const ret = index.asRetriever();
ret.similarityTopK = 5
const prompt = process.argv[2];
const response = await ret.retrieve(prompt);
const systemPrompt = `다음 텍스트를 사용하여 프롬프트에 대한 답을 제시합니다: ${response.map(r => r.node.toJSON().text).join(" - ")}`.
이 코드에서는 처리된 콘텐츠를 사용해 인덱스를 초기화합니다. 'Retriever.retrieve' 줄은 힌트를 사용해 모든 관련 노트 스니펫을 찾아 텍스트를 반환합니다. 여기서는 처음 5개의 가장 잘 일치하는 항목을 사용하도록 설정했습니다. 그래서 노트에서 5개의 텍스트 스니펫을 가져올 것입니다. 이 원시 데이터를 사용해 질문할 때 모델이 어떻게 대답해야 하는지 안내하는 시스템 프롬프트를 생성할 수 있습니다.
const ollama = 새로운 올라마().
ollama.setModel("ollama2");
ollama.set시스템 프롬프트(시스템 프롬프트);
const genout = await ollama.generate(prompt);
다음으로 모델 작업을 시작했습니다. 며칠 전에 만든 [...]에서 만든 모델을 사용했습니다.npm를 클릭합니다. 모델을 사용하도록 설정했습니다.llama2라는 명령어를 사용하여 내 컴퓨터에 다운로드했습니다. 다양한 모델을 실험하여 자신에게 가장 적합한 답을 찾을 수 있습니다.
빠른 답변을 얻으려면 작은 모델을 선택해야 합니다. 하지만 동시에 모든 텍스트 조각을 담을 수 있을 만큼 입력 컨텍스트 크기가 큰 모델도 선택해야 합니다. 저는 256개의 토큰으로 구성된 텍스트 조각을 최대 5개까지 설정했습니다. 시스템 프롬프트에 텍스트 스니펫이 포함되어 있습니다. 간단히 질문하면 몇 초 안에 답변을 받을 수 있습니다.
이제 옵시디언 플러그인이 답변을 적절하게 표시할 수 있게 되었습니다.
또 무엇을 할 수 있을까요?
텍스트 콘텐츠를 단순화하거나 텍스트와 어울리는 최적의 키워드를 찾아 메타데이터에 추가해 노트를 서로 더 잘 연결할 수 있도록 하는 방법도 고려해 볼 수 있습니다. 저는 유용한 질문과 답변 10가지를 만들어 [Anki] 이러한 다양한 목적을 달성하기 위해 다양한 모델과 프롬프트를 사용해 볼 수 있습니다. 작업의 필요에 따라 단서와 모델 가중치까지 매우 쉽게 변경할 수 있습니다.
이 포스팅을 통해 옵시디언이나 다른 노트 필기 도구를 위한 멋진 플러그인을 개발하는 방법에 대한 통찰력을 얻으셨기를 바랍니다. 에서 보시는 바와 같이 [ollama.com를 보면, 최신 네이티브 AI 도구를 사용하는 것은 매우 쉬우며, 여러분의 창의력을 보여주세요.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...