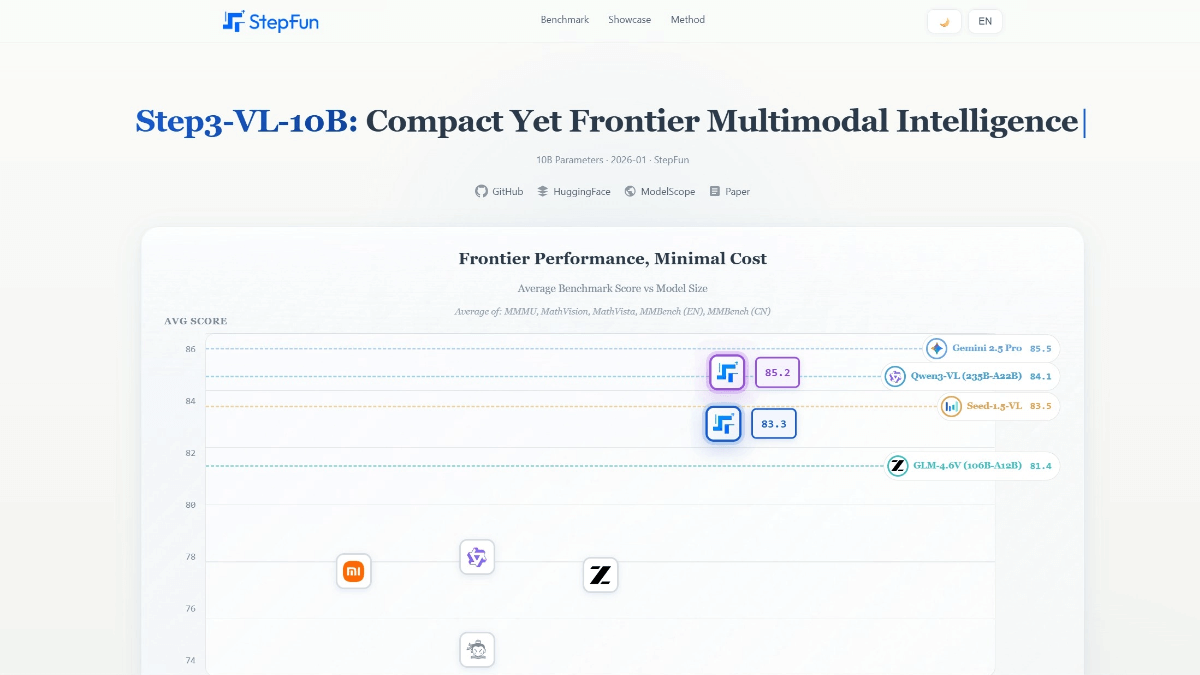

일반 소개
Muyan-TTS는 팟캐스트 시나리오를 위해 설계된 오픈 소스 텍스트 음성 변환(TTS) 모델입니다. 100,000시간 이상의 팟캐스트 오디오 데이터로 사전 학습되었으며 제로 샘플 음성 합성을 지원하여 고품질의 자연스러운 음성을 생성합니다. 이 모델은 Llama-3.2-3B를 기반으로 구축되었으며 다음을 결합합니다. SoVITS 또한 Muyan-TTS는 특정 음색의 요구에 맞춰 수십 분 분량의 1인 음성 데이터로 개인화된 음성 커스터마이징을 지원합니다. 이 프로젝트는 Apache 2.0 라이선스에 따라 전체 학습 코드, 데이터 처리 흐름 및 모델 가중치를 GitHub, Hugging Face 및 ModelScope에서 호스팅하며 개발자는 커뮤니티에 개발 및 기여를 권장합니다.

기능 목록
- 제로 샘플 음성 합성다양한 톤의 입력에 맞춰 추가 교육 없이 고품질 팟캐스트 스타일의 음성을 생성할 수 있습니다.
- 개인화된 음성 사용자 지정: 몇 분 분량의 1인 음성 데이터를 미세 조정하여 특정 화자의 음성을 생성합니다.
- 효율적인 추론 속도단일 NVIDIA A100 GPU에서 초당 약 0.33초의 오디오 생성으로 여러 오픈 소스 TTS 모델보다 뛰어난 성능을 제공합니다.
- 오픈 소스 교육 코드기본 모델부터 미세 조정된 모델까지 완벽한 교육 프로세스를 제공하며 개발자 커스터마이징을 지원합니다.
- 데이터 처리 파이프라인팟캐스트 오디오 데이터를 정리하고 트랜스크립트하기 위해 Whisper, FunASR 및 NISQA와 통합.
- API 배포 지원팟캐스트 또는 기타 음성 애플리케이션에 쉽게 통합할 수 있는 API 도구를 제공합니다.
- 모델 가중치 열기Muyan-TTS 및 Muyan-TTS-SFT 모델 가중치는 허깅 페이스와 모델스코프에서 다운로드할 수 있습니다.
도움말 사용
설치 프로세스
Muyan-TTS의 설치는 Linux 환경에서 수행해야 하며, 우분투를 권장합니다. 자세한 단계는 다음과 같습니다:
- 클론 창고
터미널을 열고 다음 명령을 실행하여 Muyan-TTS 리포지토리를 복제합니다:git clone https://github.com/MYZY-AI/Muyan-TTS.git cd Muyan-TTS
- 가상 환경 만들기
Conda로 Python 3.10용 가상 환경 만들기:conda create -n muyan-tts python=3.10 -y conda activate muyan-tts - 종속성 설치
다음 명령을 실행하여 프로젝트 종속성을 설치합니다:make build참고: FFmpeg를 설치해야 합니다. 우분투에서 작동합니다:
sudo apt update sudo apt install ffmpeg - 사전 학습된 모델 다운로드
아래 링크에서 모델 가중치를 다운로드하세요:- Muyan-TTS. 포옹하는 얼굴, 모델 범위
- Muyan-TTS-SFT. 포옹하는 얼굴, 모델 범위
- chinese-hubert-base. 포옹하는 얼굴
다운로드한 모델 파일을pretrained_models디렉토리에 다음과 같은 구조로 저장됩니다:
pretrained_models ├── chinese-hubert-base ├── Muyan-TTS └── Muyan-TTS-SFT - 설치 확인
모든 종속성과 모델 파일이 제대로 설치되었는지 확인한 후 추론 또는 학습을 수행할 수 있습니다.
기본 모델 사용(제로 샘플 음성 합성)
Muyan-TTS의 기본 모델은 제로 샘플 음성 합성을 지원하므로 팟캐스트 스타일의 음성을 빠르게 생성하는 데 적합합니다. 단계는 다음과 같습니다:
- 입력 텍스트 및 참조 오디오 준비
텍스트 준비(text) 및 참조 연설(ref_wav_path). 예시:ref_wav_path="assets/Claire.wav" prompt_text="Although the campaign was not a complete success, it did provide Napoleon with valuable experience and prestige." text="Welcome to the captivating world of podcasts, let's embark on this exciting journey together." - 추론 명령 실행
다음 명령을 사용하여 음성을 생성하려면 다음을 지정합니다.model_type때문에base::python tts.py또는 핵심 추론 코드를 실행하세요:
async def main(model_type, model_path): tts = Inference(model_type, model_path, enable_vllm_acc=False) wavs = await tts.generate( ref_wav_path="assets/Claire.wav", prompt_text="Although the campaign was not a complete success, it did provide Napoleon with valuable experience and prestige.", text="Welcome to the captivating world of podcasts, let's embark on this exciting journey together." ) output_path = "logs/tts.wav" with open(output_path, "wb") as f: f.write(next(wavs)) print(f"Speech generated in {output_path}")생성된 음성은
logs/tts.wav. - 레퍼런스 오디오 교체
제로 샘플 모드에서는ref_wav_path어떤 화자의 목소리로 교체할 수 있으며, 모델이 해당 화자의 음색을 모방하여 새로운 목소리를 생성합니다.
SFT 모델 사용(개인화된 음성 사용자 지정)
SFT 모델은 특정 음색을 생성하는 데 적합한 1인 음성 데이터로 미세 조정됩니다. 절차는 다음과 같습니다:
- 학습 데이터 준비
최소 몇 분 분량의 1인 음성 데이터를 수집하여 WAV 형식으로 저장하세요. 다운로드할 수 있는 LibriSpeech의 dev-clean 데이터 세트를 예로 들어 보세요:wget --no-check-certificate https://www.openslr.org/resources/12/dev-clean.tar.gz압축을 푼 후
prepare_sft_dataset.py에 지정된librispeech_dir는 압축 해제 경로입니다. - 학습 데이터 생성
다음 명령을 실행하여 데이터를 처리하고 다음을 생성합니다.data/tts_sft_data.json::./train.sh데이터 형식은 다음과 같습니다:
{ "file_name": "path/to/audio.wav", "text": "对应的文本内容" } - 교육 구성 조정
컴파일러training/sft.yaml를 클릭하고 학습 속도, 배치 크기 등과 같은 매개 변수를 설정합니다. - 교육 시작
train.sh다음 명령이 자동으로 실행되어 교육이 시작됩니다:llamafactory-cli train training/sft.yaml트레이닝이 완료되면 모델 가중치는
pretrained_models/Muyan-TTS-new-SFT. - SoVITS 가중치 복사
기본 모델의sovits.pth새 모델 디렉토리에 복사합니다:cp pretrained_models/Muyan-TTS/sovits.pth pretrained_models/Muyan-TTS-new-SFT - 추론 실행
SFT 모델을 사용하여 음성을 생성하려면 다음을 유지해야 합니다.ref_wav_path교육에 사용된 스피커와 일치합니다:python tts.py --model_type sft
API를 통한 배포
Muyan-TTS는 애플리케이션에 쉽게 통합할 수 있도록 API 배포를 지원합니다. 단계는 다음과 같습니다:
- API 서비스 시작하기
다음 명령을 실행하여 서비스를 시작합니다. 기본 포트는 8020입니다:python api.py --model_type base서비스 로그는
logs/llm.log. - 요청 보내기
다음 Python 코드를 사용하여 요청을 전송합니다:import requests payload = { "ref_wav_path": "assets/Claire.wav", "prompt_text": "Although the campaign was not a complete success, it did provide Napoleon with valuable experience and prestige.", "text": "Welcome to the captivating world of podcasts, let's embark on this exciting journey together.", "temperature": 0.6, "speed": 1.0, } url = "http://localhost:8020/get_tts" response = requests.post(url, json=payload) with open("logs/tts.wav", "wb") as f: f.write(response.content)
주의
- 하드웨어 요구 사항추론에는 NVIDIA A100(40GB) 또는 동급 GPU를 권장합니다.
- 언어 제한학습 데이터가 주로 영어로 되어 있기 때문에 현재 영어 입력만 지원됩니다.
- 데이터 품질SFT 모델의 음성 품질은 학습 데이터의 선명도와 일관성에 따라 달라집니다.
- 교육 비용데이터 처리(3만 달러), LLM 사전 교육(1만 9,200달러), 디코더 교육(0.134만 달러)을 포함하여 사전 교육에 소요된 총 비용은 약 5만 달러였습니다.
애플리케이션 시나리오
- 팟캐스트 콘텐츠 제작
Muyan-TTS는 팟캐스트 스크립트를 자연스러운 음성으로 빠르게 변환하여 독립 크리에이터가 고품질 오디오를 생성할 수 있도록 지원합니다. 사용자는 텍스트와 참조 음성을 입력하기만 하면 팟캐스트 스타일의 음성을 생성할 수 있어 녹음 비용을 절감할 수 있습니다. - 오디오북 제작
SFT 모델을 사용하면 크리에이터는 특정 캐릭터의 목소리를 사용자 지정하여 오디오북 챕터를 생성할 수 있습니다. 이 모델은 긴 오디오 생성을 지원하므로 긴 콘텐츠에 적합합니다. - 음성 어시스턴트 개발
개발자는 API를 통해 Muyan-TTS를 음성 어시스턴트에 통합하여 자연스럽고 개인화된 음성 상호작용 경험을 제공할 수 있습니다. - 교육용 콘텐츠 생성
학교나 교육 기관은 교육 자료를 음성으로 변환하여 언어 학습이나 시각 장애인을 위한 듣기 연습이나 코스 설명에 적합한 오디오를 생성할 수 있습니다.
QA
- Muyan-TTS는 어떤 언어를 지원하나요?
현재 학습 데이터는 영어 팟캐스트 오디오가 주를 이루기 때문에 영어만 지원됩니다. 향후 데이터 세트를 확장하여 다른 언어도 지원할 수 있습니다. - SFT 모델의 음성 품질을 개선하는 방법은 무엇인가요?
배경 소음을 피하기 위해 고품질의 선명한 1인 음성 데이터를 사용합니다. 훈련 데이터가 대상 장면의 음성 스타일과 일치하는지 확인합니다. - 느린 추론은 어떨까요?
지원 사용 보장 vLLM 가속화된 GPU 환경. 기준nvidia-smi메모리 사용량을 확인하여 모델이 GPU에 올바르게 로드되었는지 확인합니다. - 상업적 사용을 지원하나요?
Muyan-TTS는 Apache 2.0 라이선스에 따라 출시되며 라이선스 조건에 따라 상업적 사용이 지원됩니다. - 기술 지원은 어떻게 받나요?
이슈는 GitHub를 통해 제출할 수 있습니다(이슈) 또는 Discord 커뮤니티에 가입(불화) 지원 받기.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서

댓글 없음...