
미니맥스-M1이란?
MiniMax-M1은 총 4,560억 개의 파라미터가 있는 혼합 전문가 아키텍처(MoE)와 라이트닝 어텐션 메커니즘의 조합을 기반으로 하는 MiniMax 팀의 오픈 소스 추론 모델입니다. 이 모델은 1백만 토큰 MiniMax-M1은 긴 컨텍스트 입력과 80,000개의 토큰 출력을 지원하므로 긴 문서와 복잡한 추론 작업에 적합합니다. 이 모델은 계산 리소스를 최적화하고 추론 비용을 절감하기 위해 40만 및 80만 추론 예산 버전으로 제공됩니다. 미니맥스-M1은 소프트웨어 엔지니어링, 긴 문맥 이해, 도구 사용과 같은 작업에서 여러 오픈 소스 모델보다 뛰어난 성능을 발휘합니다. 이 모델의 효율적인 계산 능력과 강력한 추론 기능은 차세대 언어 모델링 에이전트를 위한 강력한 기반이 됩니다.

MiniMax-M1의 주요 기능
- 긴 컨텍스트 처리최대 100만 토큰의 입력과 8만 토큰의 출력을 지원하며, 긴 문서, 긴 보고서, 학술 논문 등 긴 텍스트 콘텐츠를 효율적으로 처리할 수 있어 복잡한 추론 작업에 적합합니다.
- 효율적인 추론컴퓨팅 리소스 할당을 최적화하고 추론 비용을 줄이며 고성능을 유지하기 위해 40K와 80K의 두 가지 추론 예산 버전을 제공합니다.
- 다분야 작업 최적화수학적 추론, 소프트웨어 엔지니어링, 긴 맥락 이해 및 도구 사용과 같은 작업에 탁월합니다.
- 함수 호출구조화된 함수 호출 지원, 외부 함수 호출 매개변수 식별 및 출력 가능, 외부 도구와 쉽게 상호 작용하여 자동화 및 업무 효율성 향상.
MiniMax-M1 성능
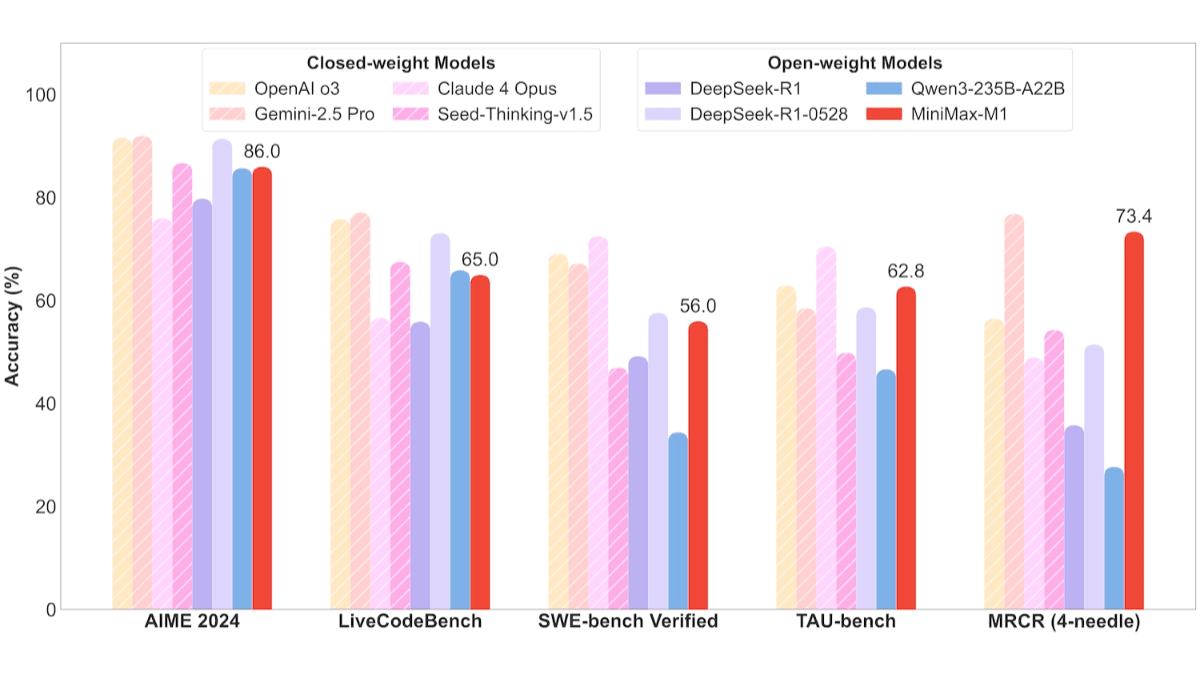
- 소프트웨어 엔지니어링 작업미니맥스-M1-40k와 미니맥스-M1-80k는 SWE 벤치마크에서 각각 55.61 TP3T와 56.01 TP3T를 기록해 딥시크-R1-0528의 57.61 TP3T보다 약간 떨어지고 다른 오픈소스 모델보다 훨씬 뛰어난 성능을 보였습니다.
- 문맥에 맞는 긴 이해력 과제수백만 개의 컨텍스트 창을 활용하는 MiniMax-M1은 긴 컨텍스트 이해 작업에서 탁월한 성능을 발휘하여 모든 오픈 소스 모델을 전반적으로 능가하며, 심지어 OpenAI o3 및 Claude 4 Opus를 능가하고 Gemini 2.5 Pro에 이어 세계 2위를 차지했습니다.
- 도구 사용 시나리오TAU 벤치 테스트에서 MiniMax-M1-40k는 모든 오픈 소스 모델에서 선두를 차지하며 Gemini-2.5 Pro를 제쳤습니다.
MiniMax-M1의 공식 웹사이트 주소
- GitHub 리포지토리::https://github.com/MiniMax-AI/MiniMax-M1
- 허깅페이스 모델 라이브러리::https://huggingface.co/collections/MiniMaxAI/minimax-m1
- 기술 문서::https://github.com/MiniMax-AI/MiniMax-M1/blob/main/MiniMax_M1_tech_report.pdf
MiniMax-M1 사용 방법
- API 호출::
- 공식 웹사이트 방문하기미니맥스 방문하기 공식 웹사이트를 클릭하고 계정에 등록한 후 로그인합니다.
- API 키 가져오기개인 센터 또는 개발자 페이지에서 API 키를 요청하세요.
- API 사용공식 API 문서에 따라 HTTP 요청을 기반으로 모델을 호출합니다. 예를 들어 Python의 요청 라이브러리를 사용하여 요청을 보냅니다:
import requests
url = "https://api.minimax.cn/v1/chat/completions"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
data = {
"model": "MiniMax-M1",
"messages": [
{"role": "user", "content": "请生成一段关于人工智能的介绍。"}
]
}
response = requests.post(url, headers=headers, json=data)
print(response.json())- 포옹하는 얼굴 사용::
- 허깅 페이스 라이브러리 설치변압기 및 토치와 같은 종속성이 설치되어 있는지 확인합니다.
pip install transformers torch- 모델 로드허깅 페이스 허브에서 MiniMax-M1 모델을 로드합니다.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "MiniMaxAI/MiniMax-M1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
input_text = "请生成一段关于人工智能的介绍。"
inputs = tokenizer(input_text, return_tensors="pt")
output = model.generate(**inputs, max_length=100)
print(tokenizer.decode(output[0], skip_special_tokens=True))- MiniMax 앱 또는 웹에서 사용::
- 웹 액세스미니맥스 웹 사이트에 로그인하고 페이지에 질문이나 작업을 입력하면 모델이 직접 답을 생성합니다.
- 앱 다운로드휴대폰에 MiniMax 앱을 다운로드하고 유사한 조작을 통해 상호 작용하세요.
MiniMax-M1의 제품 가격
- API 호출 추론 비용 가격 책정::
- 0-32k 입력 길이::
- 투입 비용토큰당 $0.8 / 백만 달러.
- 출력 비용8/백만 토큰.
- 32k-128k 입력 길이::
- 투입 비용1.2/백만 토큰.
- 출력 비용토큰 백만 개당 $16.
- 128k-1M 입력 길이::
- 투입 비용2.4백만 달러/토큰.
- 출력 비용백만 토큰당 $24.
- 0-32k 입력 길이::
- 앱 및 웹::
- 무료 사용미니맥스 앱과 웹은 무제한 무료 액세스를 제공하며, 일반 사용자 및 기술적 배경이 없는 사용자에게 적합합니다.
MiniMax-M1 핵심 이점
- 긴 컨텍스트 처리 기능최대 100만 토큰의 입력과 최대 8만 토큰의 출력을 지원하므로 긴 문서와 복잡한 추론 작업을 처리하는 데 적합합니다.
- 효율적인 추론 성능계산 리소스를 최적화하고 추론 비용을 줄이기 위해 라이트닝 주의 메커니즘과 결합된 40K 및 80K의 두 가지 추론 예산 버전을 제공합니다.
- 다분야 작업 최적화소프트웨어 엔지니어링, 긴 맥락 이해, 수학적 추론 및 도구 사용과 같은 작업에 탁월하며 다양한 애플리케이션 시나리오에 적응할 수 있습니다.
- 고급 기술 아키텍처하이브리드 전문가 아키텍처(MoE)와 대규모 강화 학습(RL) 학습을 기반으로 계산 효율성과 모델 성능을 개선합니다.
- 높은 가격 대비 품질성능은 해외 주요 모델에 근접하면서도 유연한 가격 전략과 앱 및 웹에 대한 무료 액세스를 제공하여 사용 장벽을 낮췄습니다.
MiniMax-M1의 대상 사용자
- 개발자소프트웨어 개발자는 코드를 효율적으로 생성하고, 코드 구조를 최적화하고, 프로그램을 디버그하거나, 코드 문서를 자동으로 생성할 수 있습니다.
- 연구자 및 학자긴 학술 논문을 처리하고, 문헌 검토 또는 복잡한 데이터 분석을 수행하고, 모델을 사용하여 아이디어를 빠르게 정리하고, 보고서를 생성하고, 결과를 요약합니다.
- 콘텐츠 크리에이터긴 형식의 콘텐츠를 제작해야 하는 사람들은 아이디어 생성, 스토리 개요 작성, 텍스트 수정, 장편 소설 제작 등에 MiniMax-M1을 사용합니다.
- 학생명확한 솔루션과 글쓰기 지원을 제공합니다.
- 비즈니스 사용자기업에서는 지능형 고객 서비스, 데이터 분석 도구 또는 비즈니스 프로세스 자동화와 같은 자동화 솔루션에 통합합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서




댓글 없음...