
밍유니오디오란 무엇인가요?
밍유니오디오는 텍스트, 오디오, 이미지, 비디오의 혼합 입출력을 지원하는 Ant Group의 오픈 소스 통합 오디오 멀티모달 생성 모델입니다. 다중 스케일 트랜스포머 및 혼합 전문가(MoE) 아키텍처를 채택하여 모달리티 인식 라우팅 메커니즘을 통해 크로스 모달 정보를 효율적으로 처리하여 계산 효율성을 크게 향상시킵니다. 이 모델은 음성 합성, 보이스프린트 복제, 다중 방언 생성, 오디오-텍스트 교차 모달 작업에서 우수한 성능을 발휘하며 고품질 실시간 생성이 가능합니다. 오픈 소스 기능은 연구 커뮤니티가 멀티모달 기술 개발과 실제 애플리케이션 혁신을 촉진할 수 있는 확장 가능한 솔루션을 제공합니다.
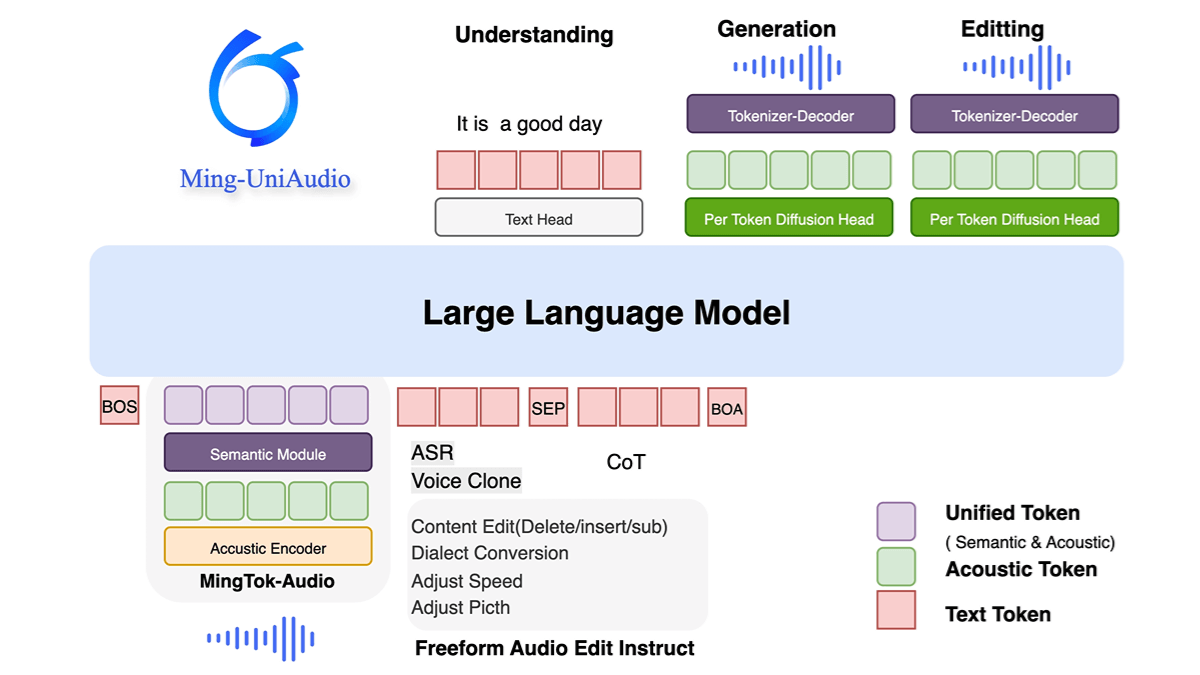
밍유니오디오의 특징
- 통합 멀티모달 처리오디오, 텍스트, 이미지, 비디오의 혼합 입력 및 생성을 지원하여 여러 모달리티에서 통합 모델링 및 상호 작용이 가능합니다.
- 엔드 투 엔드 음성 합성 및 복제고품질 음성 생성, 다중 방언 복제 및 개인화된 음성 지문 사용자 지정.
- 다중 임무 합동 교육개별 시퀀스 토큰화를 통해 여러 오디오 유형을 처리하고, 공동 학습 및 미세 조정을 위해 LLM과 결합하여 보이지 않는 작업에 맞게 조정합니다.
- 효율적인 컴퓨팅 아키텍처멀티 스케일 트랜스포머 구조를 채택하여 코덱 설계를 최적화하고 생성 효율과 품질을 향상시킵니다.
밍유니오디오의 핵심 장점
- 통합된 멀티모달 처리 기능오디오, 텍스트, 이미지, 비디오의 혼합 입력 및 생성을 지원하여 여러 개의 독립적인 모델에 의존할 필요 없이 단일 모델을 통해 여러 양식에 걸쳐 통합 모델링 및 상호 작용을 가능하게 합니다.
- 효율적인 컴퓨팅 아키텍처모달별 라우팅 메커니즘과 결합된 멀티스케일 트랜스포머 및 MoE(혼합 전문가) 설계는 계산 효율성과 리소스 활용도를 크게 향상시킵니다.
- 고품질 음성 합성 및 복제통합된 고급 오디오 디코더는 다중 방언 음성 생성, 개인화된 보이스프린트 사용자 지정 및 실시간 응답을 지원하며 음성의 자연스러움과 적응성이 뛰어납니다.
- 멀티태스크 공동 최적화개별 시퀀스 토큰화 및 단계적 훈련 전략을 통해 지각 및 생성 작업을 동시에 최적화하여 오디오 이해 및 텍스트 생성과 같은 벤치마크 테스트에서 선도적인 수준에 도달합니다.
- 오픈 소스 및 확장성커뮤니티의 추가 연구 개발을 지원하고 멀티모달 기술 및 애플리케이션 혁신의 대중화를 촉진하기 위해 코드와 모델 가중치를 완전히 공개합니다.
밍유니오디오의 공식 웹사이트는 무엇인가요?
- 프로젝트 웹사이트:: https://xqacmer.github.io/Ming-Unitok-Audio.github.io/
- 깃허브 리포지토리:: https://github.com/inclusionAI/Ming-UniAudio
- 허깅페이스 모델 라이브러리:: https://huggingface.co/inclusionAI/Ming-UniAudio-16B-A3B
밍유니오디오가 적합한 사람들
- AI 연구자 및 개발자오디오, 텍스트, 이미지, 비디오 하이브리드 처리 및 생성 작업에는 통합된 멀티모달 모델이 필요합니다.
- 음성 기술 애플리케이션음성 합성, 음성 복제 및 다중 방언 생성(예: 지능형 비서, 오디오 콘텐츠 제작자)에 중점을 둡니다.
- 멀티모달 제품 팀지각 및 생성 기능을 실제 애플리케이션에 통합할 수 있는 효율적인 컴퓨팅 아키텍처와 오픈 소스 솔루션을 모색합니다.
- 컴퓨팅 리소스 최적화 수요자모델 효율성에 대한 우려, 리소스 활용도를 개선하기 위해 모달 라우팅 메커니즘과 함께 MoE를 사용해야 합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서

댓글 없음...