

논리 구문 분석이란?
Logics-Parsing은 Qwen2.5-VL-7B 기반의 Ali 오픈 소스 엔드 투 엔드 문서 구문 분석 모델입니다. 강화 학습을 통해 문서 레이아웃 분석 및 읽기 순서 추론을 최적화하고, PDF 이미지를 구조화된 HTML 출력으로 변환할 수 있으며, 일반 텍스트, 수학 공식, 표, 화학 공식 및 필기 한자를 포함한 다양한 콘텐츠 유형을 지원합니다. 이 모델은 두 단계로 훈련됩니다. 첫 번째 단계는 구조화된 출력을 생성하는 방법을 학습하기 위한 감독 미세 조정이고, 두 번째 단계는 텍스트 정확도, 레이아웃 위치 및 읽기 순서를 최적화하기 위한 레이아웃 중심 강화 학습입니다. 특히 일반 텍스트, 화학 구조 및 필기 콘텐츠 구문 분석에서 다른 방법보다 뛰어난 성능을 보이며 LogicsParsingBench 벤치마크에서 우수한 성능을 발휘합니다.
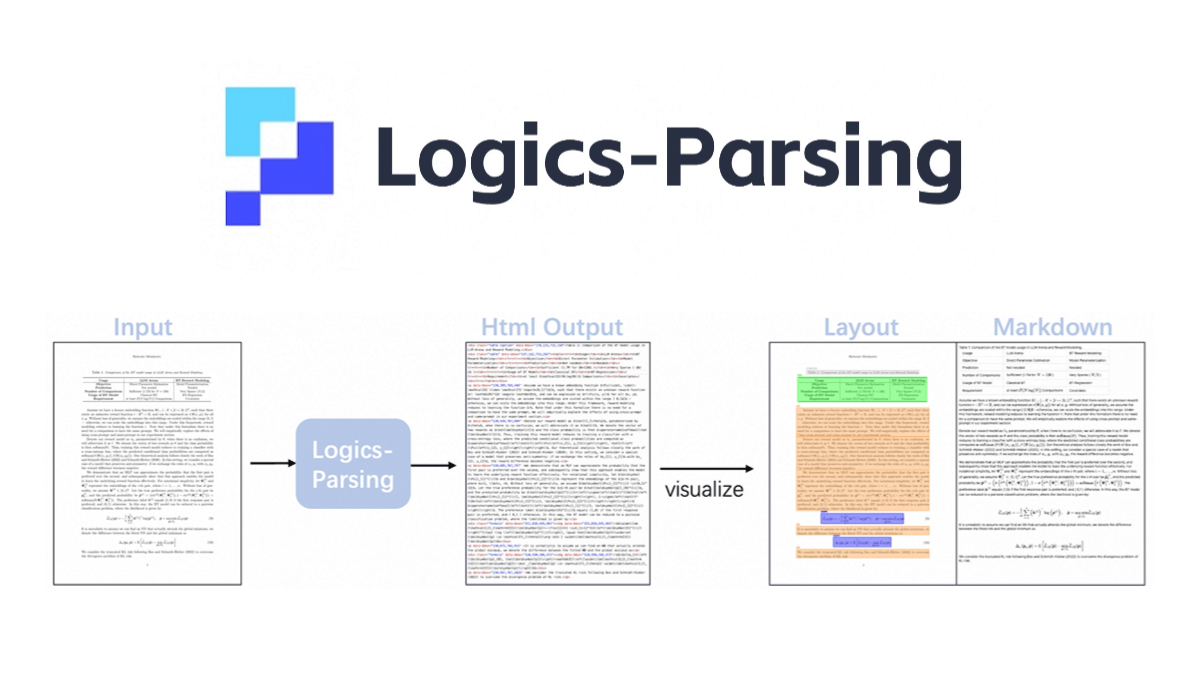
논리 구문 분석의 특징
- 엔드투엔드 해상도 기능복잡한 다단계 파이프라인 없이 문서 이미지에서 직접 구조화된 HTML 출력을 생성합니다.
- 고급 콘텐츠 인식수학 공식, 화학 구조, 필기체 한자와 같은 복잡한 내용을 정확하게 인식합니다.
- 구조화된 출력생성된 HTML은 각 콘텐츠 블록에 대한 세부 태그 및 좌표와 함께 문서의 논리적 구조를 유지합니다.
- 관련 없는 요소 자동 제거머리글 및 바닥글과 같은 관련 없는 요소를 자동으로 필터링하여 핵심 콘텐츠에 집중할 수 있습니다.
- 향상된 학습 최적화집중적인 학습을 통해 레이아웃 분석 및 읽기 순서를 최적화하여 구문 분석 정확도를 향상시킵니다.
- 고성능복잡한 다양한 문서 유형에서 기존의 다른 방법보다 성능이 뛰어납니다.
- 간단한 배포 및 추론설치 후 명령줄에서 모델 가중치를 빠르게 다운로드하고 추론 작업을 수행할 수 있습니다.
논리 구문 분석의 핵심 이점
- 높은 정확도다양한 문서 유형과 복잡한 콘텐츠에서 뛰어난 성능과 높은 정확도를 제공합니다.
- 엔드투엔드 해상도다단계 파이프라인 없이 문서 이미지에서 바로 구조화된 출력을 생성하여 프로세스를 간소화합니다.
- 복잡한 콘텐츠를 처리하는 강력한 능력수학 공식, 화학 구조, 필기체 중국어와 같은 복잡한 내용을 정확하게 인식하고 구문 분석하는 능력.
- 구조화된 출력결과 HTML 출력은 후속 처리 및 적용을 위해 문서의 논리적 구조를 보존합니다.
- 관련 없는 요소의 자동 필터링헤더 및 바닥글과 같은 불필요한 콘텐츠를 자동으로 식별하고 제거하여 핵심 메시지에 집중할 수 있도록 합니다.
- 향상된 학습 최적화강화 학습을 통해 레이아웃 분석 및 읽기 순서를 최적화하여 전반적인 성능을 개선합니다.
로직스-파싱의 공식 웹사이트는 무엇인가요?
- 깃허브 리포지토리:: https://github.com/alibaba/Logics-Parsing
- 허깅페이스 모델 라이브러리:: https://huggingface.co/Logics-MLLM/Logics-Parsing
- arXiv 기술 논문:: https://arxiv.org/pdf/2509.19760
논리 구문 분석은 누구를 위한 서비스인가요?
- (과학) 연구원학술 논문 및 과학 보고서를 구문 분석하여 핵심 정보를 추출하는 데 사용됩니다.
- 교육자교수 및 학습 지원을 위한 교재, 시험지, 필기 노트 등의 취급.
- 기업 분석가비즈니스 문서, 보고서 구문 분석, 데이터 및 정보 추출.
- 데이터 과학자데이터 마이닝 및 분석을 위해 대량의 문서 데이터를 처리합니다.
- 문서 처리 엔지니어문서 처리 시스템을 개발하여 자동화를 강화합니다.
- 학생학습 보조, 교과서 및 노트 파싱을 통해 학습 효율성을 높입니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...