
LLaVA-OneVision-1.5란 무엇인가요?
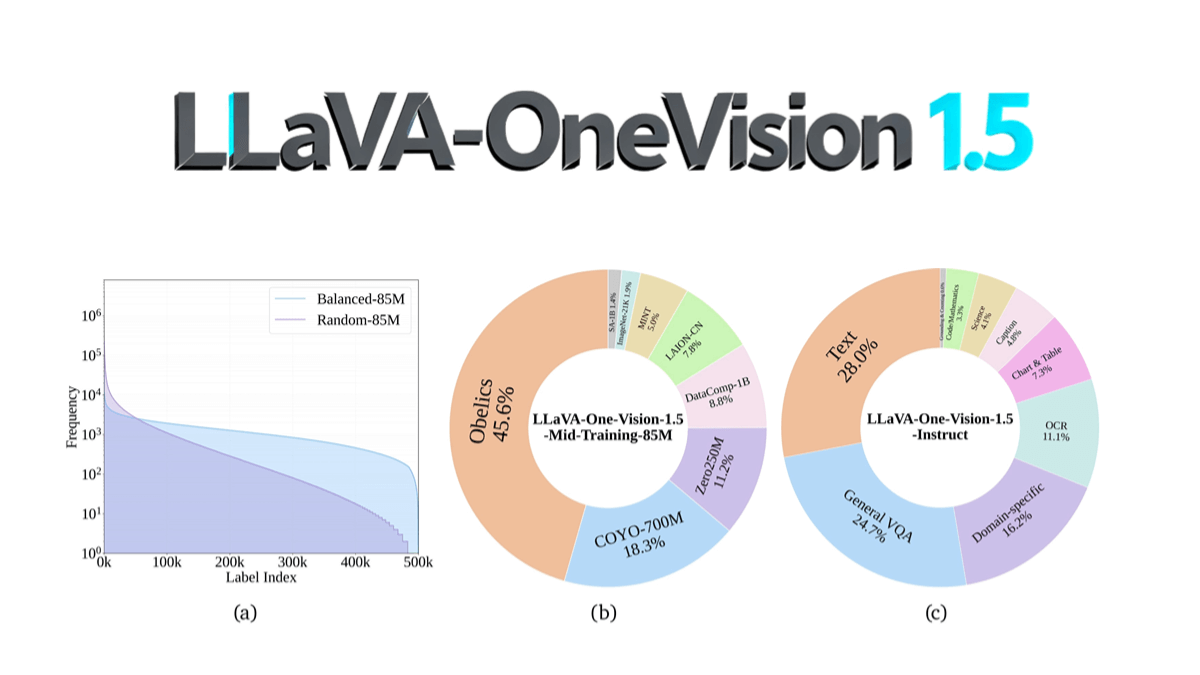
LLaVA-OneVision-1.5는 EvolvingLMMS-Lab 팀의 오픈 소스 멀티모달 모델로, 총 16만 달러의 비용으로 128개의 A800 GPU에서 4일 만에 8B 파라미터 규모를 사용하여 총 3단계(언어-이미지 정렬, 개념 균등화 및 지식 주입, 명령어 미세 조정) 훈련 과정을 통해 사전 훈련되었습니다. 핵심 혁신에는 RICE-ViT 시각 인코더의 기본 해상도 및 영역 수준의 세분화된 의미 모델링 지원과 '개념 밸런싱' 전략을 통한 최적화된 데이터 활용이 포함됩니다. OCR, 문서 이해 및 기타 작업에서 Qwen2.5-VL보다 성능이 뛰어나며, 처음으로 완전한 오픈 소스(데이터, 학습 툴체인 및 평가 스크립트 포함)를 구현하여 멀티모달 모델 재생산의 문턱을 크게 낮췄습니다. 이 모델 코드는 GitHub에 공개되어 커뮤니티에서 저비용으로 복제하고 2차 개발을 지원할 수 있습니다.
LLaVA-OneVision-1.5의 특징
- 고성능 멀티모달 이해이미지와 텍스트 정보를 효율적으로 처리하고 이해하여 다양하고 복잡한 시나리오에 대한 정확한 설명과 답변을 생성합니다.
- 효율적인 교육과 저렴한 비용최적화된 트레이닝 전략과 데이터 패킹 기술을 사용하여 높은 성능을 유지하면서 트레이닝 비용을 크게 절감할 수 있습니다.
- 강력한 명령 규정 준수사용자 명령을 정확하게 이해하고 실행할 수 있으며, 작업 일반화 능력이 우수하고 다양한 복합 작업에 적용할 수 있습니다.
- 고품질 데이터 기반신중하게 구성된 사전 학습 및 인스트럭션 미세 조정 데이터 세트를 통해 모델이 풍부한 지식과 의미 정보를 학습할 수 있도록 합니다.
- 유연한 입력 해상도 지원비주얼 인코더는 가변 입력 해상도를 지원하므로 해상도별 미세 조정이 필요 없고 다양한 이미지 크기 요구 사항에 맞게 조정할 수 있습니다.
- 지역 지각 주의 메커니즘지역 인식 주의 메커니즘을 통해 이미지의 로컬 영역에 대한 의미론적 이해를 향상시켜 모델의 디테일 캡처 능력을 향상시킵니다.
- 다국어 지원다국어 이해 및 생성 기능을 통해 다국어 입력 및 출력을 지원하여 국제화된 애플리케이션의 요구 사항에 맞게 조정할 수 있습니다.
- 투명하고 개방적인 프레임워크완전한 코드, 데이터 및 모델 리소스를 제공하여 커뮤니티를 위한 저비용 재생산 및 검증 가능한 확장을 보장하고 학술 및 산업 응용을 용이하게 합니다.
- 롱테일 식별 능력데이터에서 빈도가 낮은 범주나 개념을 효과적으로 식별하고 이해할 수 있어 모델의 일반화 능력을 향상시킬 수 있습니다.
- 교차 모드 검색 기능텍스트 기반 쿼리 이미지 또는 이미지 기반 쿼리 텍스트를 지원하여 효율적인 교차 모달 정보 검색을 달성합니다.
LLaVA-OneVision-1.5의 핵심 이점
- 고성능: 이미지와 텍스트 정보를 효율적으로 처리하여 고품질 출력을 생성하는 멀티모달 작업에서 뛰어난 성능을 발휘합니다.
- 저렴한최적화된 교육 전략과 데이터 패킹 기법을 통해 교육 비용을 대폭 절감하고 비용 효율성을 개선합니다.
- 높은 재현성완전한 코드, 데이터 및 교육 스크립트를 제공함으로써 커뮤니티가 저렴한 비용으로 모델 성능을 재현하고 검증할 수 있습니다.
- 효율적인 교육오프라인 병렬 데이터 패킹과 하이브리드 병렬 기법을 사용하여 학습 효율을 높이고 컴퓨팅 리소스 낭비를 줄입니다.
- 고품질 데이터모델이 풍부한 의미 정보를 학습할 수 있도록 대규모의 고품질 사전 학습 및 인스트럭션 미세 조정 데이터 세트가 구축됩니다.
- 유연한 입력 지원비주얼 인코더는 가변 입력 해상도를 지원하므로 해상도별 미세 조정이 필요 없고 다양한 이미지 크기 요구 사항에 맞게 조정할 수 있습니다.
- 영역 인식 기능지역 인식 주의 메커니즘을 통해 이미지의 로컬 영역에 대한 의미론적 이해가 향상되고 디테일 캡처가 개선되었습니다.
LLaVA-OneVision-1.5의 공식 웹사이트는 무엇인가요?
- 깃허브 주소:: https://github.com/EvolvingLMMs-Lab/LLaVA-OneVision-1.5
- 허깅페이스 모델 라이브러리:: https://huggingface.co/collections/lmms-lab/llava-onevision-15-68d385fe73b50bd22de23713
- arXiv 기술 논문:: https://arxiv.org/pdf/2509.23661
- 온라인 경험 데모:: https://huggingface.co/spaces/lmms-lab/LLaVA-OneVision-1.5
LLaVA-OneVision-1.5가 적합한 사람
- 연구 작업자멀티모달 학습, 컴퓨터 비전 및 자연어 처리를 연구하는 학자들은 이 모델을 최첨단 연구 및 알고리즘 개발에 사용할 수 있습니다.
- 개발자소프트웨어 엔지니어와 애플리케이션 개발자는 다양한 애플리케이션에 LLaVA-OneVision-1.5를 통합하여 지능형 고객 서비스, 콘텐츠 추천 등을 개발할 수 있습니다.
- 교육자교사 및 교육 기술자: 이미지 해석, 멀티미디어 콘텐츠 제작 등 교육 현장에서 교수 및 학습을 지원하는 데 사용할 수 있습니다.
- 의료 전문가의사 및 의료 연구원, 의료 이미지 분석 및 보조 진단에 사용하여 의료 효율성과 정확성을 향상시킬 수 있습니다.
- 콘텐츠 크리에이터작가, 디자이너 및 미디어 제작자는 이 모델을 사용하여 창의적인 콘텐츠, 카피 및 이미지 설명을 생성하여 창작 효율성을 향상시킵니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...