
일반 소개
Llasa-3B는 홍콩과학기술대학교 오디오 랩(HKUST Audio)에서 개발한 오픈 소스 텍스트 음성 변환(TTS) 모델입니다. 이 모델은 여러 언어를 지원할 뿐만 아니라 감정 표현과 개인화된 음성 복제가 가능한 고품질 음성 생성을 제공하도록 세심하게 조정된 Llama 3.2B 아키텍처를 기반으로 하며, 자연스러운 음성 합성의 표현력과 유연성으로 많은 연구자와 개발자의 주목을 받고 있습니다.

체험: https://huggingface.co/spaces/srinivasbilla/llasa-3b-tts
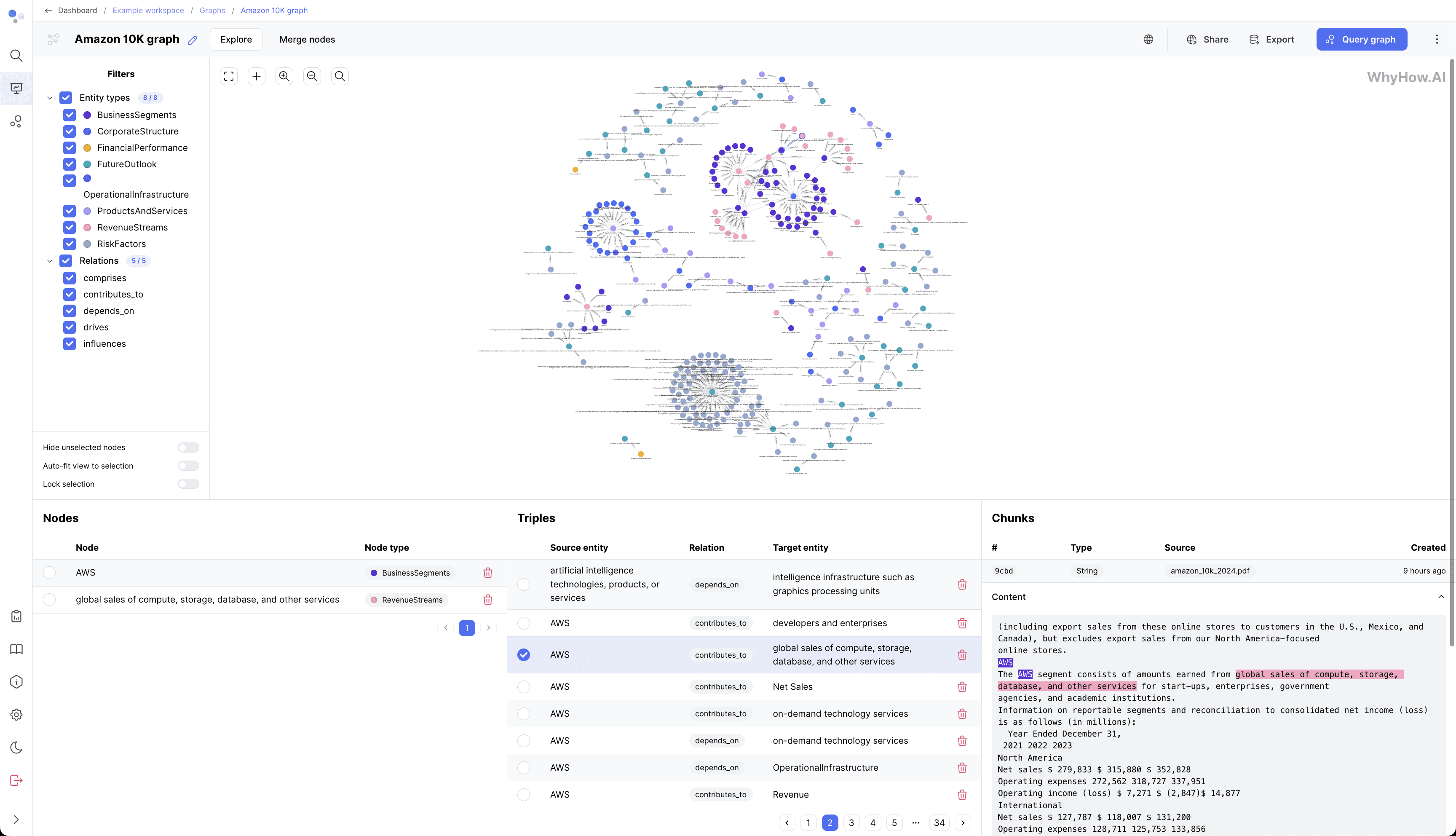
기능 목록
- 텍스트 음성 변환: 텍스트를 자연스럽고 부드러운 소리로 변환합니다.
- 음성 복제음색과 감정을 포함한 특정 보컬을 복제하려면 15초 분량의 오디오 클립만 있으면 됩니다.
- 다국어 지원중국어와 영어가 지원되며, 향후 더 많은 언어로 확대할 예정입니다.
- 감정 표현생성된 음성에 감정을 주입하는 기능은 음성의 진정성을 높여줍니다.
- 다중 모델 지원1B 및 3B 파라메트릭 스케일 모델 사용 가능, 향후 8B 모델 도입 예정
- 오픈 가중치모든 모델에는 개발자가 직접 사용하거나 두 번 미세 조정할 수 있는 오픈 웨이트가 제공되며, 트랜스포머 및 vLLM 프레임.
도움말 사용
설치 및 환경 준비
Llasa-3B 모델을 사용하려면 먼저 다음 환경을 준비해야 합니다:
Python 환경Python 3.9 이상을 권장합니다.
관련 라이브러리설치 필요torch, transformers, xcodec2등 라이브러리.
conda create -n xcodec2 python=3.9
conda activate xcodec2
pip install transformers torch xcodec2==0.1.3
모델 다운로드 및 로드
허깅 페이스 방문하기Llasa-3B 페이지허깅 페이스의 모델 다운로드 기능을 바로 사용할 수 있습니다:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import soundfile as sf
llasa_3b = 'HKUST-Audio/Llasa-3B'
tokenizer = AutoTokenizer.from_pretrained(llasa_3b)
model = AutoModelForCausalLM.from_pretrained(llasa_3b)
model.eval()
model.to('cuda') # 如果有GPU
텍스트 음성 변환 프로세스
- 준비된 텍스트::
- 음성으로 변환하려는 텍스트를 입력합니다.
- 텍스트 전처리::
- 예를 들어 특정 형식의 텍스트를 사용하여 음성 생성을 위한 모델을 안내할 수 있습니다:
input_text = "这是一个测试文本,请转成语音。" formatted_text = f"<|TEXT_UNDERSTANDING_START|>{input_text}<|TEXT_UNDERSTANDING_END|>"
- 예를 들어 특정 형식의 텍스트를 사용하여 음성 생성을 위한 모델을 안내할 수 있습니다:
- 음성 생성::
- 텍스트를 모델이 이해할 수 있는 토큰으로 변환합니다:
chat = [ {"role": "user", "content": "Convert the text to speech:" + formatted_text}, {"role": "assistant", "content": "<|SPEECH_GENERATION_START|>"} ] input_ids = tokenizer.apply_chat_template(chat, tokenize=True, return_tensors='pt', continue_final_message=True) input_ids = input_ids.to('cuda') - 음성 토큰을 생성합니다:
speech_end_id = tokenizer.convert_tokens_to_ids('<|SPEECH_GENERATION_END|>') outputs = model.generate(input_ids, max_length=2048, eos_token_id=speech_end_id, do_sample=True, top_p=1, temperature=0.8)
- 텍스트를 모델이 이해할 수 있는 토큰으로 변환합니다:
- 음성 디코딩::
- 생성된 토큰을 다시 오디오로 변환합니다:
from xcodec2.modeling_xcodec2 import XCodec2Model model_path = "HKUST-Audio/xcodec2" Codec_model = XCodec2Model.from_pretrained(model_path).eval().cuda() generated_ids = outputs[0][input_ids.shape[1]:-1] speech_tokens = tokenizer.batch_decode(generated_ids, skip_special_tokens=True) speech_ids = [int(token[4:-2]) for token in speech_tokens if token.startswith('<|s_') and token.endswith('|>')] speech_tokens_tensor = torch.tensor(speech_ids).cuda().unsqueeze(0).unsqueeze(0) gen_wav = Codec_model.decode_code(speech_tokens_tensor) sf.write("output.wav", gen_wav[0, 0, :].cpu().numpy(), 16000)
- 생성된 토큰을 다시 오디오로 변환합니다:
음성 복제
- 약 15초 분량의 원본 사운드 트랙을 녹음하거나 준비합니다.::
- 녹음 장치를 사용하거나 기존 오디오 파일을 제공하세요.
- 음성 복제 프로세스::
- 원본 사운드 주파수를 모델이 사용할 수 있는 코드북으로 인코딩합니다:
prompt_wav = sf.read("your_source_audio.wav")[0] # 必须是16kHz采样率 vq_code_prompt = Codec_model.encode_code(torch.from_numpy(prompt_wav).unsqueeze(0).unsqueeze(0).cuda()) - 텍스트 생성 프로세스에 오디오 단서를 추가합니다:
speech_ids_prefix = [f"<|s_{id}|>"foridin vq_code_prompt[0, 0, :].tolist()] chat = [ {"role": "user", "content": "Convert the text to speech:" + formatted_text}, {"role": "assistant", "content": "<|SPEECH_GENERATION_START|>" + ''.join(speech_ids_prefix)} ] # 后续步骤与文本转语音相同
- 원본 사운드 주파수를 모델이 사용할 수 있는 코드북으로 인코딩합니다:
주의
- 오디오 입력 형식이 올바른지 확인하세요. Llasa-3B는 16kHz 오디오만 지원합니다.
- 모델의 성능은 입력 텍스트와 오디오의 품질에 직접적인 영향을 받아 입력 품질을 보장합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...