
시각적 모델을 사용하여 이미지 텍스트 추출을 위한 OCR 프롬프트

복잡한 텍스트 구조 또는 혼합 텍스트 콘텐츠가 있는 경우 시각적 모델 OCR 기능을 사용하여 콘텐츠를 추출하는 것이 좋습니다.
멀티모달 매크로 모델 또는 특수 시각 모델은 이미지의 내용을 이해하고 인식 작업을 수행하라는 지시를 받을 수 있으며, 이 기능을 사용하여 요구 사항에 맞는 결과물을 만들 수 있습니다.
OCR 프롬프트는 다음 도구에서 테스트하는 것이 좋습니다: ChatGPT , Kimi 및 Qwen2-VL(현재 가장 정확함)
테스트 이미지:
이 이미지의 복잡성은 다른 대형 모델에서 서로 다른 방식으로 이해되는 가려진 json 부분에 있습니다.
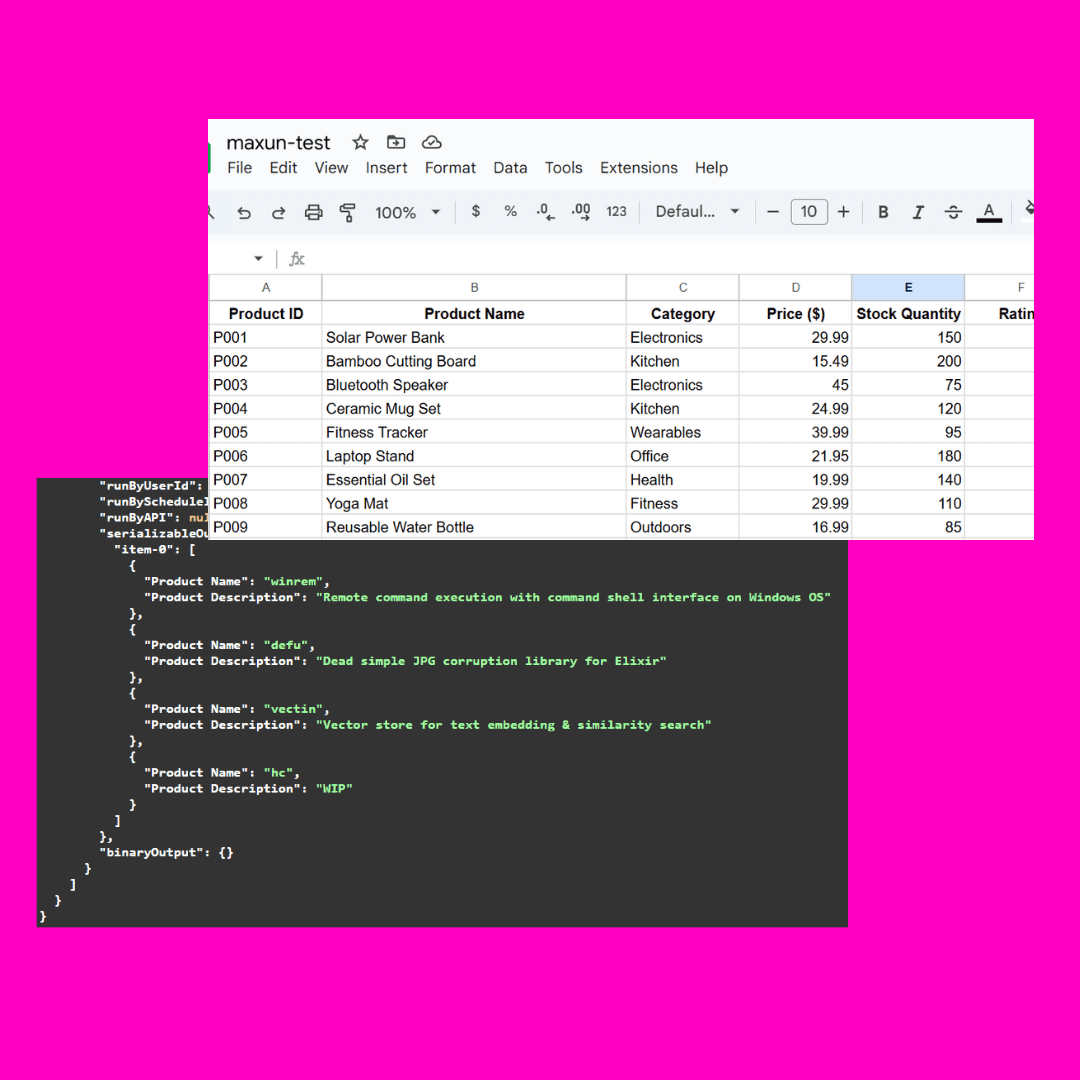
간단한 명령은 보통 괜찮습니다:
按照原文格式提取
콘텐츠의 일부만 추출됩니다:
仅提取图片中的表格部分
추출하여 고정 형식 텍스트로 변환합니다:
识别图片后整理为MARKDOWN格式表格,请保持表格原始顺序、格式和语言
구조화된 추출:
您的任务是将文件内容转录并格式化为 markdown。您的目标是创建一个结构良好、可读性强的 markdown 文档,该文档准确表示原始内容,同时添加适当的格式和标签。 请按照以下说明完成任务: 1. 仔细阅读整个文件内容。 2. 将内容转录为 markdown 格式,密切关注现有的格式和结构。 3. 如果您在原始内容中发现任何不清楚的格式,请自行判断添加适当的 markdown 格式以提高可读性和结构。 4. 对于表格、标题和目录,请添加以下标签: - 表格:将整个表格括在 [TABLE] 和 [/TABLE] 标签中。如果表格内容在下一页继续,请合并表格内容。 - 标题(在每页开头重复的完整字符串):括在 markdown 文件内的 [HEADER] 和 [/HEADER] 标签中。 - 目录:用 [TOC] 和 [/TOC] 标签括起来 5. 转录表格时: - 如果表格跨越多页,请将内容合并为一个连贯的表格。 - 使用适当的 markdown 表格格式,表格结构使用竖线 (|) 和连字符 (-)。 6. 不要在转录中包含分页符。 7. 保持文档的逻辑流程和结构,确保使用 markdown 标题正确格式化章节和小节(# 表示主标题,## 表示副标题等)。 8. 根据需要对其他格式元素(如粗体、斜体、列表和代码块)使用适当的 markdown 语法。 10. 仅返回 markdown 格式的解析内容,包括表格、标题和目录的指定标签。
추출 및 번역:
제가 가장 자주 사용하는 번역 명령은 여기에 사용되며, 복잡한 구조의 텍스트를 추출하는 OCR에도 훌륭하게 작동합니다:원본 서식을 유지하면서 '영어 지침 템플릿'을 '중국어 지침'으로 번역합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...