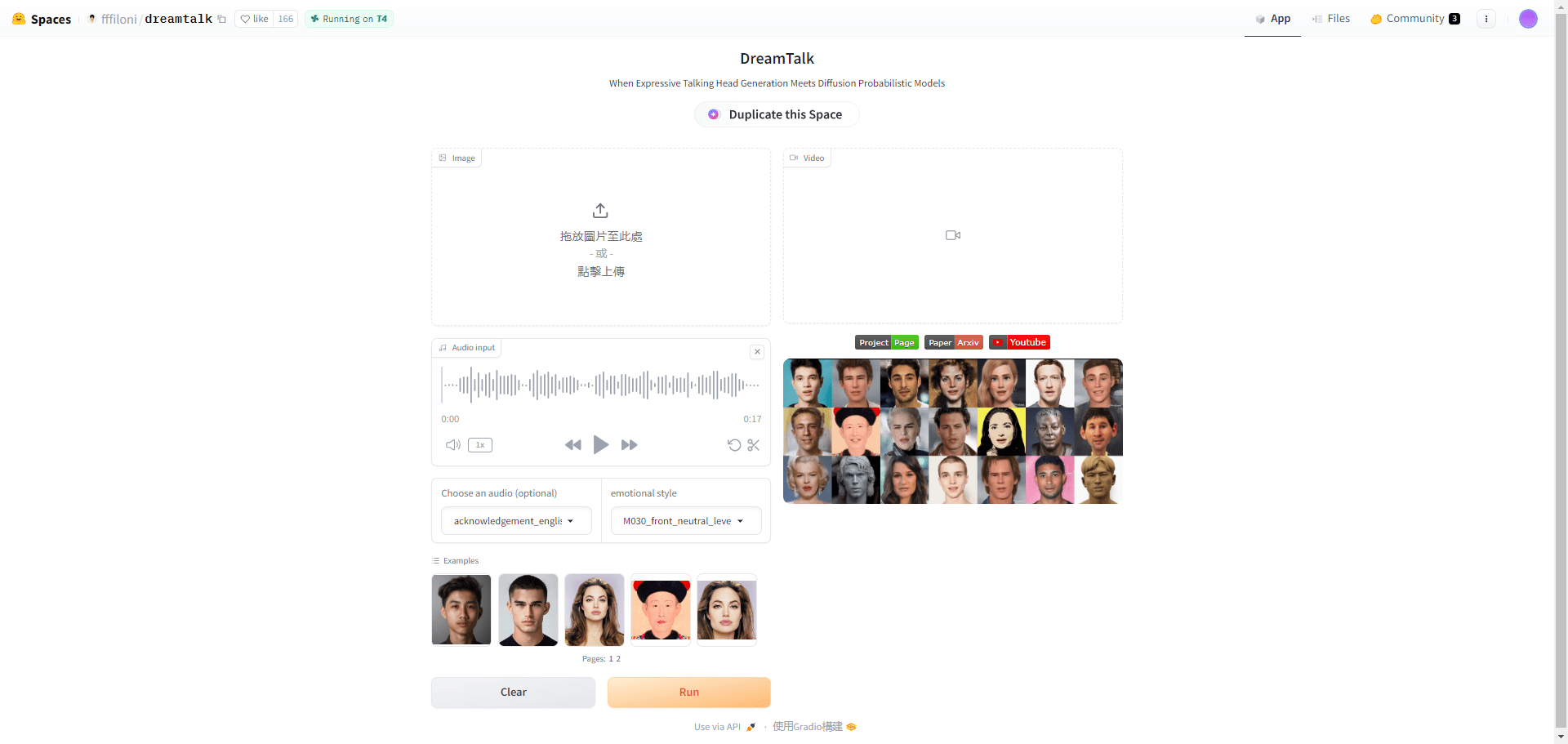

일반 소개
LightLLM 은 경량 설계, 손쉬운 확장, 효율적인 성능으로 잘 알려진 Python 기반의 대규모 언어 모델(LLM) 추론 및 서비스 프레임워크입니다. 이 프레임워크는 FasterTransformer, TGI, vLLM, FlashAttention 등 잘 알려진 다양한 오픈 소스 구현을 활용하며, 다양한 모델과 애플리케이션 시나리오에서 비동기 협업, 동적 배치, 텐서 병렬 처리 등의 기술을 통해 GPU 활용도와 추론 속도를 획기적으로 개선합니다.

기능 목록
- 비동기 협업: 비동기식 단어 분할, 모델 추론 및 분할 해제 작업을 지원하여 GPU 활용도를 향상시킵니다.
- 필러리스 주의: 여러 모델에 대한 필러리스 주의 작업을 지원하고 길이 차이가 큰 요청을 처리합니다.
- 동적 일괄 처리: 요청의 동적 일괄 예약을 지원합니다.
- 플래시어텐션: 플래시어텐션으로 속도를 높이고 GPU 메모리 공간을 줄입니다.
- 텐서 병렬 처리: 텐서 병렬 처리를 사용하여 여러 GPU에서 추론 속도를 높입니다.
- 토큰 주의: 메모리 낭비가 전혀 없는 KV 캐시에 토큰 기반 메모리 관리 메커니즘을 구현했습니다.
- 고성능 라우터: 토큰 어텐션과 협력하여 시스템 처리량을 최적화하세요.
- Int8KV 캐시: 토큰 용량을 거의 두 배로 늘립니다.
- 여러 모델을 지원합니다: BLOOM, LLaMA, StarCoder, ChatGLM2 등.
도움말 사용
설치 프로세스
- Docker를 사용하여 LightLLM을 설치합니다:
docker pull modeltc/lightllm
docker run -it --rm modeltc/lightllm
- 종속성을 설치합니다:
pip install -r requirements.txt
사용법
- LightLLM 서비스를 시작합니다:
python -m lightllm.server
- 쿼리 모델(콘솔 예제):
python -m lightllm.client --model llama --text "你好,世界!"
- 쿼리 모델(Python 예제):
from lightllm import Client
client = Client(model="llama")
response = client.query("你好,世界!")
print(response)
주요 기능
- 비동기 협업LightLLM은 세분화, 모델 추론, 세분화 해제 작업을 비동기적으로 실행하여 GPU 활용도를 크게 향상시킵니다. 사용자는 서비스를 시작하기만 하면 시스템이 이러한 작업을 자동으로 처리합니다.
- 채워지지 않은 주의 집중 시간길이 차이가 큰 요청을 처리할 때, LightLLM은 패딩 없는 주의 작업을 지원하여 효율적인 처리를 보장합니다. 사용자가 추가로 구성할 필요가 없으며 시스템이 자동으로 최적화됩니다.
- 동적 일괄 처리LightLLM은 동적 배치 스케줄링을 지원하며, 사용자는 구성 파일을 통해 배치 매개 변수를 설정할 수 있으며, 시스템은 요청에 따라 배치 정책을 동적으로 조정합니다.
- 플래시 어텐션플래시어텐션 기술을 통합함으로써 LightLLM은 추론 속도를 개선하고 GPU 메모리 사용 공간을 줄입니다. 사용자는 구성 파일에서 이 기능을 활성화할 수 있습니다.
- 텐서 병렬 처리LightLLM은 여러 GPU에서 텐서 병렬 처리를 지원합니다. 사용자는 구성 파일을 통해 GPU 수와 병렬 처리 매개 변수를 설정할 수 있으며, 시스템이 자동으로 작업을 할당합니다.
- 토큰 주의LightLLM은 KV 캐시를 위한 토큰 기반 메모리 관리 메커니즘을 구현하여 메모리 낭비를 최소화합니다. 추가 사용자 구성이 필요 없으며 시스템이 자동으로 메모리를 관리합니다.
- 고성능 라우터LightLLM의 고성능 라우터는 토큰 어텐션과 함께 작동하여 시스템 처리량을 최적화합니다. 사용자는 구성 파일에서 라우팅 매개변수를 설정할 수 있으며, 시스템이 자동으로 라우팅 정책을 최적화합니다.
- Int8KV 캐시라이트엘엘엠은 토큰 용량을 거의 두 배로 늘리기 위해 Int8KV 캐시를 지원합니다. 사용자는 구성 파일에서 이 기능을 활성화할 수 있으며, 시스템이 자동으로 캐싱 전략을 조정합니다.
지원 모델
LightLLM은 다음을 포함하되 이에 국한되지 않는 다양한 모델을 지원합니다:
- BLOOM
- LLaMA
- 스타코더
- ChatGLM2
- InternLM
- Qwen-VL
- Llava
- Stablelm
- MiniCPM
- Phi-3
- CohereForAI
- DeepSeek-V2
사용자는 필요에 따라 적절한 모델을 선택하고 구성 파일에서 적절하게 설정할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...