


01.컨텍스트
RAG 애플리케이션 개발에서 첫 번째 단계는 문서를 청크하는 것이며, 효율적인 문서 청크는 후속 리콜 콘텐츠의 정확도를 효과적으로 향상시킬 수 있습니다. 효율적인 청킹 방법은 시맨틱 청킹의 내용에 따라 고정 크기 청킹, 임의 크기 청킹, 슬라이딩 윈도우 리샘플링, 재귀적 청킹 및 기타 방법 등이 논의의 뜨거운 주제입니다. Jina AI가 제안한 후기 청킹은 청킹 문제를 다른 관점에서 다루고 있는데, 이를 살펴보겠습니다.
02.레이트 청킹이란 무엇인가요?
기존의 청킹은 긴 문서를 다룰 때 문서의 장거리 문맥 의존성을 잃을 수 있으며, 이는 정보 검색과 이해에 있어 큰 함정입니다. 즉, 핵심 정보가 여러 텍스트 블록에 흩어져 있는 경우 문맥에서 벗어난 텍스트 청킹 조각은 원래의 의미를 잃게 되어 추후 기억력이 저하될 가능성이 높습니다.
Milvus 2.4.13 릴리스 노트를 예로 들어 다음과 같이 두 개의 문서 블록으로 나뉘어져 있고, 다음과 같이Milvus 2.4.13有哪些新功能?의 경우 직접 관련된 콘텐츠는 청크 2에 있고 Milvus 버전 정보는 청크 1에 있습니다. 이 경우 임베딩 모델이 이러한 참조를 엔티티에 올바르게 연결하기 어렵기 때문에 임베딩 품질이 떨어질 수 있습니다.
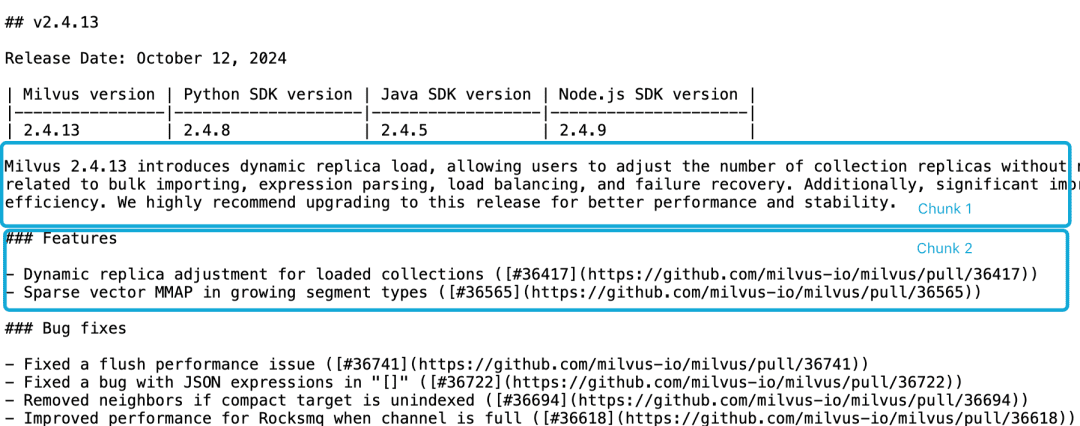
LLM은 기능 설명이 버전 정보와 동일한 청크에 있지 않고 더 큰 컨텍스트 문서가 없기 때문에 이러한 상관관계 문제를 해결하는 데 어려움이 있습니다. 슬라이딩 윈도우 리샘플링, 컨텍스트 윈도우 길이 겹치기, 다중 문서 스캔 등 이 문제를 완화하기 위한 여러 가지 휴리스틱이 있지만 모든 휴리스틱이 그렇듯이 이러한 방법도 경우에 따라서는 효과가 있을 수 있지만 이론적으로 보장할 수는 없습니다.
기존의 청킹은 먼저 청킹한 다음 임베딩 모델을 거치는 사전 청킹 전략을 사용합니다. 텍스트는 먼저 문장, 단락 또는 미리 설정된 최대 길이와 같은 매개변수에 따라 잘립니다. 그런 다음 임베딩 모델은 평균 풀링과 같은 방법을 사용하여 이러한 청크를 하나씩 처리합니다. 토큰 후기 청킹은 먼저 임베딩 모델을 거친 다음 청킹하는 프로세스입니다(이것이 '후기'의 의미입니다). 반면 후기 청킹은 청킹하기 전에 임베딩 모델을 거치는 것으로(여기서 '후기'의 의미는 선 벡터화 후 청킹입니다), 먼저 임베딩 모델의 변압기 이 레이어는 전체 텍스트에 적용되어 풍부한 문맥 정보를 포함하는 각 토큰에 대한 벡터 표현 시퀀스를 생성합니다. 그런 다음 이러한 토큰 벡터 시퀀스를 균등하게 풀링하여 전체 텍스트 컨텍스트를 고려한 최종 블록 임베딩을 얻습니다.
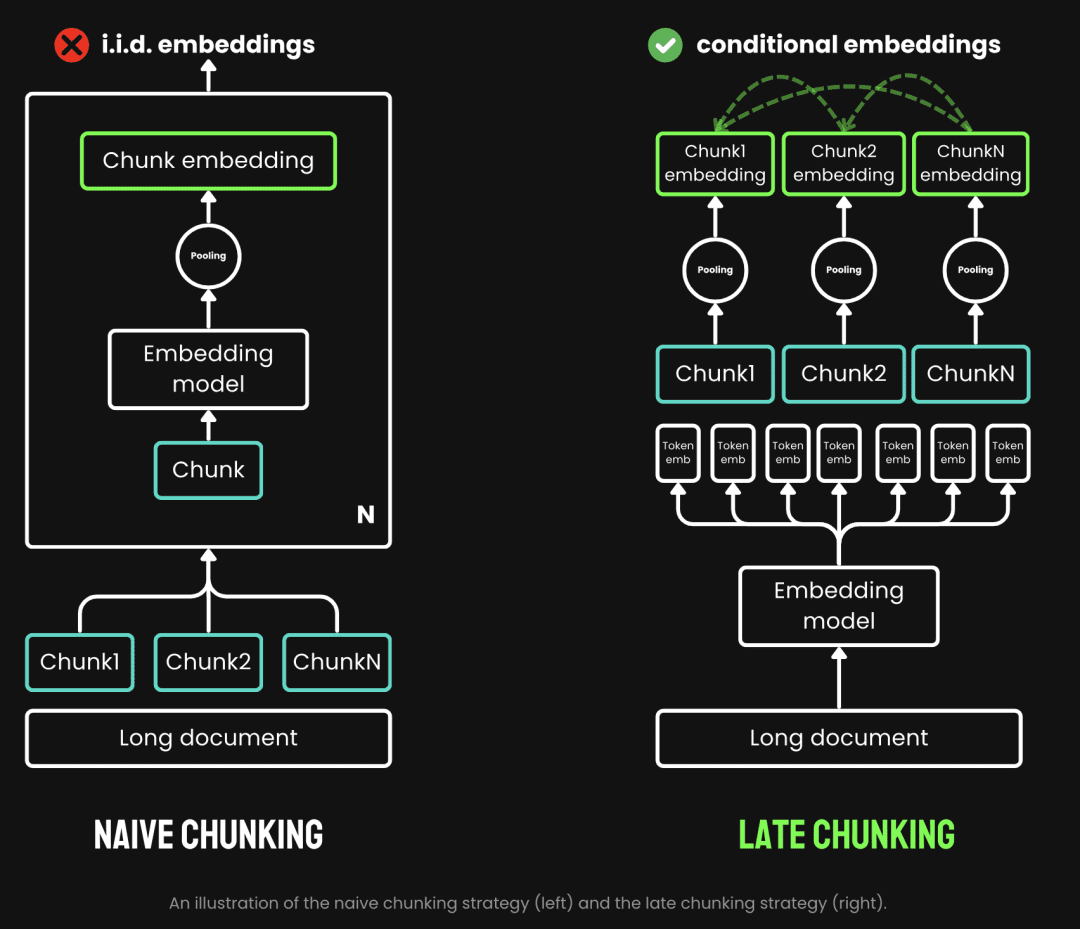
(이미지 출처: https://jina.ai/news/late-chunking-in-long-context-embedding-models/)
후기 청킹은 각 블록이 더 많은 컨텍스트 정보를 인코딩하는 블록 임베딩을 생성하여 인코딩의 품질과 정확성을 향상시킵니다. 다음과 같은 긴 컨텍스트를 지원하여 긴 컨텍스트 임베딩 모델을 지원할 수 있습니다. jina-embeddings-v2-base-en최대 8192토큰의 텍스트(A4 용지 10페이지에 해당)를 처리할 수 있으며, 이는 기본적으로 대부분의 긴 텍스트의 문맥 요구 사항을 충족합니다.
요약하면, RAG 애플리케이션에서 후기 청킹의 이점을 확인할 수 있습니다:
- 정확도 향상: 후기 청킹은 문맥 정보를 보존함으로써 단순 청킹보다 쿼리에 더 관련성 높은 콘텐츠를 반환합니다.
- 효율적인 LLM 호출: 후기 청킹은 더 적은 수의 관련성 있는 청크를 반환하므로 LLM으로 전달되는 텍스트의 양을 줄입니다.
03.후기 청킹 테스트
3.1. 청킹 기반 구현 지연
원본 문서에서 문단 청크에 대한 문장_청커 함수는 청크의 콘텐츠와 청크 마킹 정보 span_annotations(즉, 청크 마킹의 시작과 끝)를 반환합니다.
def sentence_chunker(document, batch_size=10000):
nlp = spacy.blank("en")
nlp.add_pipe("sentencizer", config={"punct_chars": None})
doc = nlp(document)
docs = []
for i in range(0, len(document), batch_size):
batch = document[i : i + batch_size]
docs.append(nlp(batch))
doc = Doc.from_docs(docs)
span_annotations = []
chunks = []
for i, sent in enumerate(doc.sents):
span_annotations.append((sent.start, sent.end))
chunks.append(sent.text)
return chunks, span_annotations
document_to_token_embeddings 함수는 모델을 전달합니다. jinaai/jina-embeddings-v2-base-en 모델과 전체 문서의 임베딩을 반환하는 토큰라이저를 사용할 수 있습니다.
def document_to_token_embeddings(model, tokenizer, document, batch_size=4096): tokenized_document = tokenizer(document, return_tensors="pt") tokens = tokenized_document.tokens() outputs = [] for i in range(0, len(tokens), batch_size): start = i end = min(i + batch_size, len(tokens)) batch_inputs = {k: v[:, start:end] for k, v in tokenized_document.items()} with torch.no_grad(): model_output = model(**batch_inputs) outputs.append(model_output.last_hidden_state) model_output = torch.cat(outputs, dim=1) return model_output
늦은_청킹 함수는 전체 문서의 임베딩과 원본 청크의 마크업 정보 스팬 주석을 청크화합니다.
def late_chunking(token_embeddings, span_annotation, max_length=None): outputs = [] for embeddings, annotations in zip(token_embeddings, span_annotation): if ( max_length is not None ): annotations = [ (start, min(end, max_length - 1)) for (start, end) in annotations if start < (max_length - 1) ] pooled_embeddings = [] for start, end in annotations: if (end - start) >= 1: pooled_embeddings.append( embeddings[start:end].sum(dim=0) / (end - start) ) pooled_embeddings = [ embedding.detach().cpu().numpy() for embedding in pooled_embeddings ] outputs.append(pooled_embeddings) return outputs
모델을 사용하는 경우jinaai/jina-embeddings-v2-base-en후기 청크 수행
tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
# First chunk the text as normal, to obtain the beginning and end points of the chunks.
chunks, span_annotations = sentence_chunker(document)
# Then embed the full document.
token_embeddings = document_to_token_embeddings(model, tokenizer, document)
# Then perform the late chunking
chunk_embeddings = late_chunking(token_embeddings, [span_annotations])[0]
3.2. 기존 임베딩 방법과의 비교
밀버스 2.4.13 릴리스 노트를 예로 들어보겠습니다.
Milvus 2.4.13에는 동적 복제본 로드 기능이 도입되어 사용자가 컬렉션을 해제하고 다시 로드할 필요 없이 컬렉션 복제본의 수를 조정할 수 있습니다. 컬렉션.
이 버전에서는 대량 가져오기, 표현식 구문 분석, 로드 밸런싱 및 장애 복구와 관련된 몇 가지 중요한 버그도 해결되었습니다.
또한 MMAP 리소스 사용량과 가져오기 성능이 크게 개선되어 전반적인 시스템 효율성이 향상되었습니다.
더 나은 성능과 안정성을 위해 이번 릴리스로 업그레이드하는 것을 적극 권장합니다.
전통적인 임베딩, 즉 청킹 후 임베딩과 후기 청킹 접근 방식 임베딩, 즉 임베딩 후 청킹이 각각 수행됩니다. 그런 다음 milvus 2.4.13 두 가지 임베딩 접근 방식의 결과를 각각 비교합니다.
cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
milvus_embedding = model.encode('milvus 2.4.13')
for chunk, late_chunking_embedding, traditional_embedding in zip(chunks, chunk_embeddings, embeddings_traditional_chunking):
print(f'similarity_late_chunking("milvus 2.4.13", "{chunk}")')
print('late_chunking: ', cos_sim(milvus_embedding, late_chunking_embedding))
print(f'similarity_traditional("milvus 2.4.13", "{chunk}")')
print('traditional_chunking: ', cos_sim(milvus_embedding, traditional_embeddings))
결과에서 단어 milvus 2.4.13 후기 청킹 결과와 청킹된 문서의 유사성이 기존 임베딩보다 높은 이유는 후기 청킹이 전체 텍스트 구절에 대해 임베딩을 먼저 수행하므로 전체 텍스트 구절이 다음과 같이 되기 때문입니다. milvus 2.4.13 정보를 사용하여 후속 텍스트 비교에서 유사성을 크게 향상시킵니다.
similarity_late_chunking("milvus 2.4.13", "Milvus 2.4.13 introduces dynamic replica load, allowing users to adjust the number of collection replicas without needing to release and reload the collection.")
late_chunking: 0.8785206
similarity_traditional("milvus 2.4.13", "Milvus 2.4.13 introduces dynamic replica load, allowing users to adjust the number of collection replicas without needing to release and reload the collection.")
traditional_chunking: 0.8354263
similarity_late_chunking("milvus 2.4.13", "This version also addresses several critical bugs related to bulk importing, expression parsing, load balancing, and failure recovery.")
late_chunking: 0.84828955
similarity_traditional("milvus 2.4.13", "This version also addresses several critical bugs related to bulk importing, expression parsing, load balancing, and failure recovery.")
traditional_chunking: 0.7222632
similarity_late_chunking("milvus 2.4.13", "Additionally, significant improvements have been made to MMAP resource usage and import performance, enhancing overall system efficiency.")
late_chunking: 0.84942204
similarity_traditional("milvus 2.4.13", "Additionally, significant improvements have been made to MMAP resource usage and import performance, enhancing overall system efficiency.")
traditional_chunking: 0.6907381
similarity_late_chunking("milvus 2.4.13", "We highly recommend upgrading to this release for better performance and stability.")
late_chunking: 0.85431844
similarity_traditional("milvus 2.4.13", "We highly recommend upgrading to this release for better performance and stability.")
traditional_chunking: 0.71859795
3.3. 밀버스에서 후기 청킹 테스트하기
밀버스로 후기 청킹 데이터 가져오기
batch_data=[]
for i in range(len(chunks)):
data = {
"content": chunks[i],
"embedding": chunk_embeddings[i].tolist(),
}
batch_data.append(data)
res = client.insert(
collection_name=collection,
data=batch_data,
)
쿼리 테스트
코사인 유사도 쿼리 방법과 후기 청킹을 위한 Milvus 네이티브 쿼리 방법을 각각 정의합니다.
def late_chunking_query_by_milvus(query, top_k = 3):
query_vector = model(**tokenizer(query, return_tensors="pt")).last_hidden_state.mean(1).detach().cpu().numpy().flatten()
res = client.search(
collection_name=collection,
data=[query_vector.tolist()],
limit=top_k,
output_fields=["id", "content"],
)
return [item.get("entity").get("content") for items in res for item in items]
def late_chunking_query_by_cosine_sim(query, k = 3):
cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
query_vector = model(**tokenizer(query, return_tensors="pt")).last_hidden_state.mean(1).detach().cpu().numpy().flatten()
results = np.empty(len(chunk_embeddings))
for i, (chunk, embedding) in enumerate(zip(chunks, chunk_embeddings)):
results[i] = cos_sim(query_vector, embedding)
results_order = results.argsort()[::-1]
return np.array(chunks)[results_order].tolist()[:k]
결과를 보면 두 방법 모두 동일한 콘텐츠를 반환하므로 Milvus의 후기 청킹 쿼리 결과가 정확하다는 것을 알 수 있습니다.
> late_chunking_query_by_milvus("What are new features in milvus 2.4.13", 3)
['nn### Featuresnn- Dynamic replica adjustment for loaded collections ([#36417](https://github.com/milvus-io/milvus/pull/36417))n- Sparse vector MMAP in growing segment types ([#36565](https://github.com/milvus-io/milvus/pull/36565))...
> late_chunking_query_by_cosine_sim("What are new features in milvus 2.4.13", 3)
['nn### Featuresnn- Dynamic replica adjustment for loaded collections ([#36417](https://github.com/milvus-io/milvus/pull/36417))n- Sparse vector MMAP in growing segment types ([#36565](https://github.com/milvus-io/milvus/pull/36565))...
04.요약
후기 청킹의 등장 배경, 기본 개념, 기본 구현을 소개한 다음 Mivlus에서 테스트를 통해 후기 청킹이 잘 작동하는 것을 확인했습니다. 전반적으로 정확성, 효율성, 구현 용이성이 결합된 후기 청킹은 RAG 애플리케이션에 효과적인 접근 방식입니다.
참조.
- https://stackoverflow.blog/2024/06/06/breaking-up-is-hard-to-do-chunking-in-rag-applications
- https://jina.ai/news/late-chunking-in-long-context-embedding-models/
- https://jina.ai/news/what-late-chunking-really-is-and-what-its-not-part-ii/
샘플 코드:
링크: https://pan.baidu.com/s/1cYNfZTTXd7RwjnjPFylReg?pwd=1234 추출 코드: 1234 코드가 aws g4dn.xlarge 머신에서 실행됩니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...