
LangExtract란 무엇인가요?
LangExtract는 대규모 언어 모델(LLM)을 사용해 비정형 텍스트에서 구조화된 정보를 추출하는 Google 오픈 소스 Python 라이브러리입니다. 사용자 정의 명령과 소수의 예제를 통해 임상 노트의 약물 이름이나 문헌의 인물 관계 등 주요 세부 정보를 효율적으로 식별하고 정리할 수 있습니다. LangExtract의 핵심 강점은 각 추출을 원본 텍스트의 정확한 위치에 매핑하는 정확한 소스 텍스트 위치 지정과 쉽게 역추적하고 검증할 수 있는 시각적 강조 표시를 지원한다는 점입니다. 클라우드 모델과 로컬 오픈 소스 모델을 포함한 여러 언어 모델을 지원하는 LangExtract는 긴 문서를 처리하고 추출 효율성을 최적화할 수 있으며, 대화형 시각화 기능을 제공하고 독립형 HTML 파일을 생성할 수 있어 사용자가 추출 결과를 원래의 맥락에서 쉽게 보고 검토할 수 있습니다. LangExtract는 의료, 문학, 금융 등 다양한 분야에서 사용할 수 있으며, 복잡한 텍스트에서 가치 있는 정보를 빠르게 추출할 수 있도록 도와줍니다.
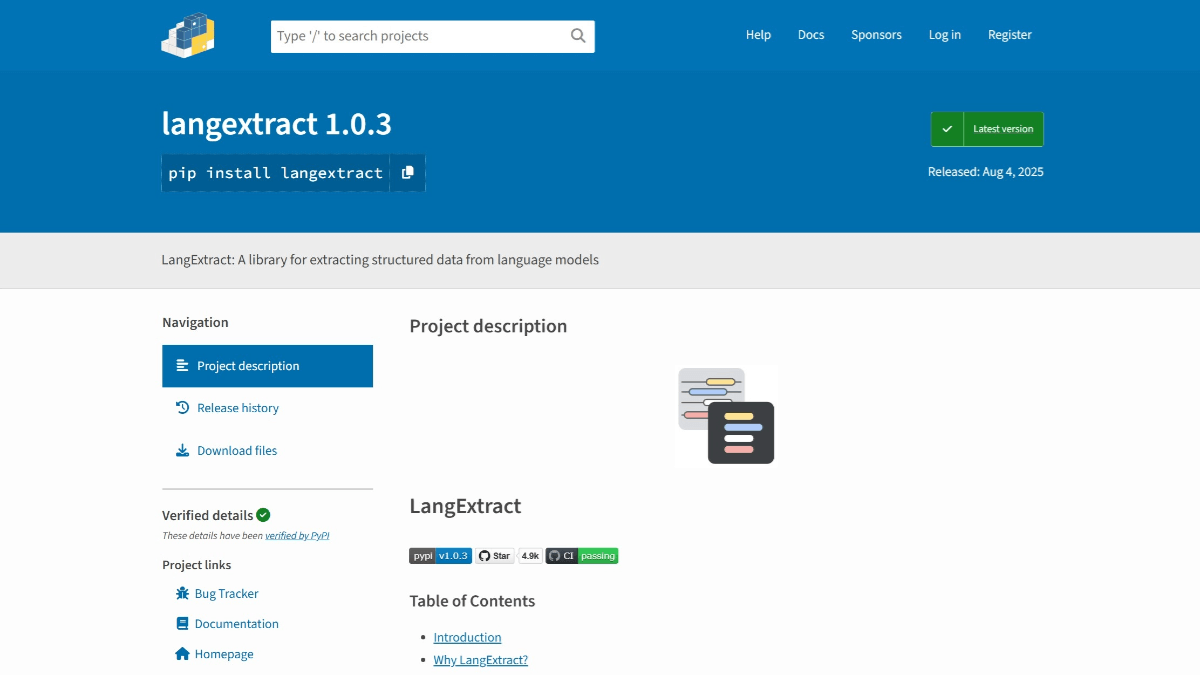
LangExtract의 주요 기능
- 텍스트 추출비정형 텍스트에서 핵심 정보를 추출하고 임상 노트, 보고서 등과 같은 다양한 유형의 데이터를 지원합니다.
- 정확한 포지셔닝추출된 콘텐츠를 소스 텍스트 위치에 정확하게 매핑하고 추적 및 검증을 위한 시각적 강조 표시를 지원합니다.
- 구조화된 출력추출된 정보를 구조화된 형식(예: JSONL)으로 출력하여 후속 처리 및 분석이 용이하도록 합니다.
- 긴 문서 최적화텍스트 청크 및 다중 라운드 추출 전략을 통해 매우 긴 문서를 효율적으로 처리하고 기억력을 향상하세요.
- 대화형 시각화사용자가 원래의 컨텍스트에서 추출 결과를 보고 검토할 수 있는 대화형 HTML 파일을 생성합니다.
- 유연한 모델 지원클라우드 기반 모델(예: Google Gemini) 및 로컬 오픈 소스 모델을 포함하여 여러 언어 모델이 지원됩니다.
- 도메인 적응의료, 문학, 금융 등과 같은 여러 도메인에 대해 모델을 미세 조정할 필요 없이 적은 수의 예제로 모든 도메인에 대한 추출 작업을 정의할 수 있습니다.
- 효율적인 처리병렬 처리를 지원하고 추출 효율을 향상시키며 대규모 텍스트 처리 작업에 적합합니다.
LangExtract 프로젝트 주소
- 프로젝트 웹사이트:: https://pypi.org/project/langextract/
- GitHub 리포지토리:: https://github.com/google/langextract
LangExtract 사용 방법
- LangExtract 설치파이썬의 패키지 관리 도구인 pip로 LangExtract 라이브러리를 설치합니다.
- 추출 작업 정의요구 사항에 따라 추출 지침을 개발하고, 추출할 정보 유형을 지정하고, 소량의 샘플 데이터를 준비합니다.
- 구성 모델클라우드 모델(예: Google Gemini) 또는 로컬 모델(예: 다음을 통해) 중 적합한 언어 모델을 선택합니다. Ollama (인터페이스).
- 코드 작성: LangExtract에서 제공하는 API를 사용하여 모델을 로드하고 추출 함수를 호출하는 코드를 작성합니다.
- 추출 실행: 대상 텍스트에서 추출 작업을 수행하는 코드를 실행하면 LangExtract가 정의된 작업과 모델에 따라 정보 추출을 수행합니다.
- 결과 저장추출 결과를 구조화된 형식(예: JSONL 파일)으로 저장하여 나중에 쉽게 처리할 수 있도록 합니다.
- 시각화 보고서 생성LangExtract에서 제공하는 도구를 사용하여 대화형 HTML 시각화 보고서를 생성하여 추출 결과를 쉽게 보고 검증할 수 있습니다.
- 최적화 및 조정추출 지침 또는 모델 매개변수를 조정하여 추출 결과의 정확도와 수요에 따라 추출 결과를 최적화합니다.
LangExtract의 핵심 강점
- 정확한 소스 텍스트 위치 지정각 추출을 원본 텍스트의 해당 위치에 정확하게 매핑하고 시각적 강조 표시를 지원하며 추적 및 검증을 용이하게 합니다.
- 유연한 모델 적용다양한 시나리오의 요구에 맞게 클라우드 모델(예: Google Gemini) 및 로컬 오픈 소스 모델(예: Ollama 인터페이스)을 포함한 여러 언어 모델이 지원됩니다.
- 긴 문서 처리 최적화매우 긴 문서에 최적화되어 텍스트 청크, 병렬 처리 및 다중 라운드 추출 전략을 통해 추출 효율과 회상률을 향상시킵니다.
- 대화형 시각화클릭 한 번으로 생성된 대화형 HTML 시각화 보고서를 제공하여 사용자가 원래의 컨텍스트에서 추출 결과를 쉽게 보고 검토할 수 있습니다.
- 효율적인 구조화된 출력적은 수의 예제를 기반으로 일관된 출력 패턴을 적용하면 추출 결과가 체계적이고 견고해집니다.
- 현장 적응력이 뛰어납니다.의료, 문학, 금융 등과 같은 광범위한 도메인에 대해 모델을 미세 조정하지 않고도 몇 가지 예제만으로 모든 도메인에 대한 추출 작업을 정의할 수 있습니다.
LangExtract의 대상
- 데이터 분석가데이터 분석 및 보고서 작성을 위해 대량의 텍스트 데이터에서 가치 있는 정보를 추출해야 할 필요성.
- 의료 업계 종사자예: 의사, 간호사, 의료 연구원, 임상 노트, 의료 기록 등과 같은 의료 텍스트 처리용
- 법률 전문가변호사, 법무 담당자 등 법률 문서, 계약서 등을 분석하고 주요 용어와 정보를 추출하는 경우.
- 금융 업계 담당자:: 재무 분석가, 리스크 관리자, 재무 보고서 및 거래 기록 처리를 위한 경우.
- 학술 연구자연구 및 종합을 위해 학술 문헌에서 데이터와 결론을 추출해야 합니다.
- 문학 연구자문학 작품을 분석하고 등장인물, 줄거리, 주제 등에 대한 정보를 추출하는 데 사용됩니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서

댓글 없음...