

일반 소개
KAG(지식 증강 생성)는 OpenSPG 엔진과 LLM(대규모 언어 모델)을 기반으로 하는 논리적 형식 안내 추론 및 검색 프레임워크입니다. 이 프레임워크는 전문 도메인 지식 기반을 위한 논리적 추론 및 사실 질문 솔루션을 구축하기 위해 특별히 설계되어 기존의 RAG(검색 증강 생성) 벡터 유사도 계산 모델의 단점을 효과적으로 극복하며, KAG는 LLM 친화적인 지식 표현, 지식 그래프와 원시 텍스트 조각 간의 상호 색인, 하이브리드 추론 솔버 및 하이브리드 추론 솔버의 네 가지 양방향 보완적인 강점을 통해 LLM과 지식 그래프를 향상시킵니다. 인덱싱, 하이브리드 추론 솔버, 타당성 평가 메커니즘을 제공합니다. 이 프레임워크는 특히 수치 계산, 시간 관계, 전문가 규칙과 같은 복잡한 지식 논리 문제를 처리하는 데 적합하며, 전문 도메인 애플리케이션에 보다 정확하고 신뢰할 수 있는 질문 답변 기능을 제공합니다.

기능 목록
- 복잡한 논리적 형태의 추론을 지원하는 기능
- 지식 그래프와 벡터 검색의 하이브리드 검색 메커니즘 제공
- LLM 친화적인 지식 표현 변환 구현하기
- 지식 구조 및 텍스트 블록의 양방향 인덱싱 지원
- LLM 추론, 지적 추론 및 수학적 논리적 추론의 통합
- 신뢰성 평가 및 검증을 위한 메커니즘 제공
- 멀티홉 Q&A 및 복잡한 쿼리 처리 지원
- 전문 도메인 지식 기반을 위한 맞춤형 솔루션 제공
도움말 사용
1. 환경 준비
가장 먼저 해야 할 일은 시스템이 다음 요구 사항을 충족하는지 확인하는 것입니다:
- Python 3.8 이상
- OpenSPG 엔진 환경
- 대규모 언어 모델에 지원되는 API 인터페이스
2. 설치 단계
- 프로젝트 웨어하우스 복제:
git clone https://github.com/OpenSPG/KAG.git
cd KAG
- 종속성 패키지를 설치합니다:
pip install -r requirements.txt
3. 프레임워크 사용 프로세스
3.1 지식창고 준비
- 전문 도메인 지식 데이터 가져오기
- 지식 그래프 모델 구성하기
- 텍스트 색인 시스템 구축
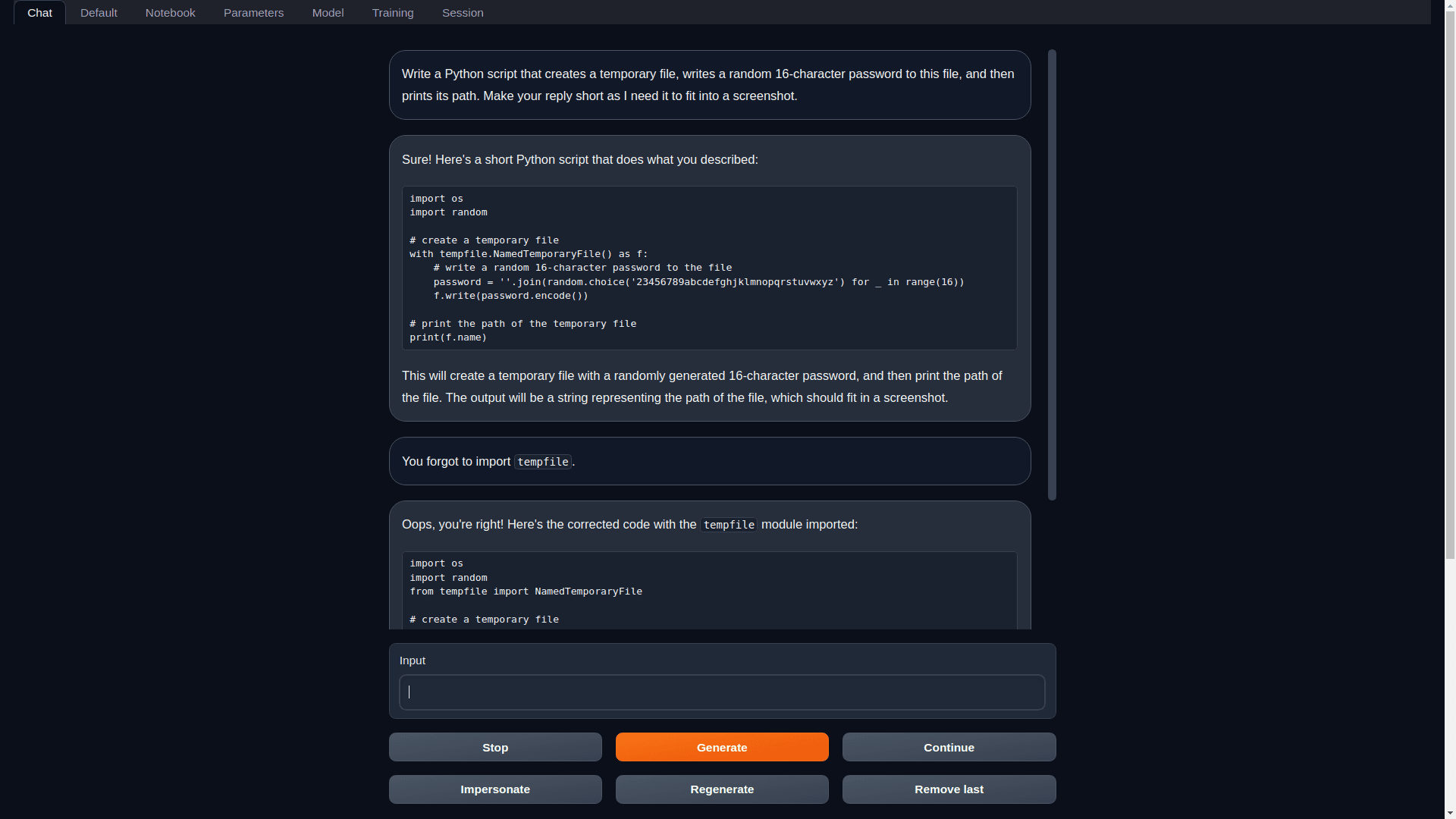
3.2 쿼리 처리
- 질문 입력: 시스템에서 사용자로부터 자연어 질문을 받습니다.
- 논리 형식 변환: 문제를 표준화된 논리 표현으로 변환하기
- 혼합 검색:
- 지식 그래프 검색 수행
- 벡터 유사도 검색 수행
- 검색 결과 통합
3.3 추론 프로세스
- 논리적 추론: 혼합 추론 솔버를 사용한 다단계 추론
- 지식 융합: LLM 추론과 지식 그래프 추론 결과의 결합
- 답변 생성: 최종 답변 형성
3.4 신뢰성 보장
- 답변 확인
- 추론 경로 추적
- 자신감 평가(수학)
4. 고급 기능 사용
4.1 맞춤형 지식 표현
지식 표현 형식은 전문 분야의 필요에 따라 사용자 지정할 수 있으므로 LLM과의 호환성을 보장합니다:
# 示例代码
knowledge_config = {
"domain": "your_domain",
"schema": your_schema_definition,
"representation": your_custom_representation
}
4.2 추론 규칙 구성
도메인별 로직을 처리하도록 특수 추론 규칙을 구성할 수 있습니다:
# 示例代码
reasoning_rules = {
"numerical": numerical_processing_rules,
"temporal": temporal_reasoning_rules,
"domain_specific": your_domain_rules
}
5. 모범 사례
- 지식창고 데이터의 품질과 무결성 보장하기
- 검색 전략 최적화를 통한 효율성 향상
- 지식창고의 정기적인 업데이트 및 유지 관리
- 시스템 성능 및 정확도 모니터링
- 지속적인 개선을 위한 사용자 피드백 수집
6. 일반적인 문제 해결
- 검색 효율성 문제가 발생하면 인덱스 매개변수를 적절히 조정할 수 있습니다.
- 복잡한 쿼리의 경우 단계별 추론 전략을 사용할 수 있습니다.
- 추론 결과가 부정확한 경우 지식 표현 및 규칙 구성 확인
KAG 프로젝트 프레젠테이션
1. 소개
며칠 전 Ant는 지식 그래프와 벡터 검색의 장점을 최대한 활용하여 기존 도메인 지식 서비스 프레임워크의 문제를 해결하는 것을 목표로 하는 전문 도메인 지식 서비스 프레임워크인 지식 증강 생성(KAG: Knowledge Augmented Generation)을 공식적으로 출시했습니다. RAG 기술 스택의 몇 가지 문제점.
이 프레임 워크 워밍업의 개미에서 저는 KAG의 일부 핵심 기능, 특히 논리적 상징 추론과 지식 정렬에 더 관심이 있었으며, 기존 주류 RAG 시스템에서이 두 가지 논의 사항이 너무 많지 않은 것 같고이 오픈 소스를 활용하고 서둘러 물결을 연구했습니다.
- KAG 논문 주소: https://arxiv.org/pdf/2409.13731
- KAG 프로젝트 주소: https://github.com/OpenSPG/KAG
2. 프레임워크 개요
코드를 읽기 전에 프레임워크의 목표와 포지셔닝에 대해 간단히 살펴보겠습니다.
2.1 무엇이며 왜?
사실 KAG 프레임워크를 보면 많은 사람들이 가장 먼저 떠오르는 의문은 왜 RAG가 아닌 KAG라고 부르는가 하는 것입니다. 관련 기사와 논문에 따르면 KAG 프레임워크는 주로 전문 도메인 지식 서비스에서 현재 대규모 모델이 직면하고 있는 몇 가지 문제를 해결하기 위해 설계되었습니다:
- LLM은 비판적으로 사고하는 능력이 없고 추론 능력이 부족합니다.
- 사실, 논리, 정확성 오류, 사전 정의된 도메인 지식 구조를 사용하여 모델의 동작을 제한하지 못하는 경우
- 일반 RAG는 또한 LLM 착각, 특히 은밀하게 잘못된 정보를 다루는 데 어려움을 겪습니다.
- 전문 서비스의 과제와 요구 사항, 엄격하고 통제된 의사 결정 프로세스의 부재
따라서 Ant 팀은 전문 지식 서비스 프레임워크가 다음과 같은 특성을 가져야 한다고 생각합니다:
- 지식 경계의 무결성, 지식 구조 및 의미의 명확성 등 지식의 정확성을 보장하는 것이 중요합니다;
- 논리적 엄격성, 시간 민감성, 수치 민감성이 요구됩니다;
- 지식 기반 의사 결정을 내릴 때 완전한 지원 정보에 쉽게 액세스할 수 있으려면 완전한 문맥 정보도 필요합니다;
Ant의 공식적인 KAG 포지셔닝은 전문 도메인 지식 증강 서비스 프레임워크, 특히 현재 대규모 언어 모델과 지식 그래프의 조합을 통해 다음 다섯 가지 영역을 향상시키는 것입니다.
- LLM 친화성에 대한 지식 향상
- 지식 그래프와 원본 텍스트 조각 간의 상호 색인 구조
- 논리 기호 가이드 하이브리드 추론 엔진
- 의미론적 추론에 기반한 지식 정렬 메커니즘
- KAG 모델
이번 오픈 소스 릴리스에는 처음 네 가지 핵심 기능이 모두 포함되어 있습니다.
KAG 명명 문제로 돌아와서, 저는 개인적으로 지식 온톨로지의 개념을 강화하기 위한 것이 아닌가 추측합니다. 공식적인 설명과 실제 코드 구현에서 KAG 프레임워크는 구성 또는 추론 단계에서 지식 자체에서 완전하고 엄격한 논리 링크를 구축하여 RAG 기술 스택의 알려진 문제점을 최대한 개선하기 위해 지속적으로 강조하고 있습니다.
2.2 무엇을 (어떻게) 달성하고 있나요?
KAG 프레임워크는 KAG-빌더, KAG-솔버, KAG-모델의 세 부분으로 구성됩니다:
- KAG-Builder는 오프라인 인덱싱에 사용되며 위에서 언급한 기능 1과 2, 즉 지식 표현 향상, 상호 인덱싱 구조가 포함되어 있습니다.
- KAG-Solver 모듈은 논리적-기호적 하이브리드 추론 엔진, 지식 정렬 메커니즘인 기능 3과 4를 다룹니다.
- 반면 KAG-Model은 엔드투엔드 KAG 모델을 구축하려고 시도합니다.
3. 소스 코드 분석
이 오픈소스는 주로 빌더와 솔버 두 하위 디렉토리의 소스 코드에 직접적으로 해당하는 KAG-Builder와 KAG-Solver 두 모듈로 구성되어 있습니다.
코드를 실제로 공부하는 동안에는 먼저 examples 가장 먼저 해야 할 일은 전체 프레임워크의 흐름을 이해하기 위해 디렉토리로 시작한 다음 특정 모듈을 더 자세히 살펴보는 것입니다. 여러 데모의 엔트리 파일 경로는 다음과 같이 유사합니다. kag/examples/medicine/builder/indexer.py too kag/examples/medicine/solver/evaForMedicine.py빌더는 서로 다른 모듈을 결합하는 반면 솔버의 실제 진입 지점은 kag/solver/logic/solver_pipeline.py.
3.1 KAG-빌더
먼저 전체 카탈로그 구조를 게시해 보겠습니다.
❯ tree .
.
├── __init__.py
├── component
│ ├── __init__.py
│ ├── aligner
│ │ ├── __init__.py
│ │ ├── kag_post_processor.py
│ │ └── spg_post_processor.py
│ ├── base.py
│ ├── extractor
│ │ ├── __init__.py
│ │ ├── kag_extractor.py
│ │ ├── spg_extractor.py
│ │ └── user_defined_extractor.py
│ ├── mapping
│ │ ├── __init__.py
│ │ ├── relation_mapping.py
│ │ ├── spg_type_mapping.py
│ │ └── spo_mapping.py
│ ├── reader
│ │ ├── __init__.py
│ │ ├── csv_reader.py
│ │ ├── dataset_reader.py
│ │ ├── docx_reader.py
│ │ ├── json_reader.py
│ │ ├── markdown_reader.py
│ │ ├── pdf_reader.py
│ │ ├── txt_reader.py
│ │ └── yuque_reader.py
│ ├── splitter
│ │ ├── __init__.py
│ │ ├── base_table_splitter.py
│ │ ├── length_splitter.py
│ │ ├── outline_splitter.py
│ │ ├── pattern_splitter.py
│ │ └── semantic_splitter.py
│ ├── vectorizer
│ │ ├── __init__.py
│ │ └── batch_vectorizer.py
│ └── writer
│ ├── __init__.py
│ └── kg_writer.py
├── default_chain.py
├── model
│ ├── __init__.py
│ ├── chunk.py
│ ├── spg_record.py
│ └── sub_graph.py
├── operator
│ ├── __init__.py
│ └── base.py
└── prompt
├── __init__.py
├── analyze_table_prompt.py
├── default
│ ├── __init__.py
│ ├── ner.py
│ ├── std.py
│ └── triple.py
├── medical
│ ├── __init__.py
│ ├── ner.py
│ ├── std.py
│ └── triple.py
├── oneke_prompt.py
├── outline_prompt.py
├── semantic_seg_prompt.py
└── spg_prompt.py
빌더 섹션에서는 다양한 기능을 다루므로 여기서는 더 중요한 구성 요소 중 하나만 살펴보겠습니다. KAGExtractor 기본 흐름도는 아래와 같습니다:

여기서 주로 하는 일은 대규모 모델을 사용하여 비정형 텍스트에서 정형 지식으로 지식 그래프를 자동으로 생성하는 것이며, 이와 관련된 몇 가지 중요한 단계에 대해 간략하게 설명합니다.
- 먼저, 엔티티 인식 모듈이 있는데, 미리 정의된 지식 그래프 유형에 대해 특정 엔티티 인식이 먼저 수행되고 그다음에 일반 명명된 엔티티 인식이 수행됩니다. 이 2단계 식별 메커니즘은 도메인별 엔티티를 모두 캡처하고 일반 엔티티를 놓치지 않도록 보장해야 합니다.
- 매핑 구축 프로세스는 실제로
assemble_sub_graph_with_spg_records메서드가 수행되며, 시스템이 기본 유형이 아닌 속성을 엔티티의 원래 속성으로 계속 유지하는 대신 그래프의 노드와 에지로 변환한다는 점에서 특별합니다. 이 약간의 변화는 솔직히 잘 이해되지 않으며, 엔티티의 복잡성을 어느 정도 단순화하기 위한 것이지만 실제로 이 전략이 얼마나 많은 이점을 가져다주는지는 명확하지 않으며 빌드의 복잡성은 확실히 증가했습니다. - 엔티티 표준화 기준
named_entity_standardization노래로 응답append_official_name이 두 가지 방법은 함께 수행됩니다. 먼저 엔티티 이름을 정규화한 다음 이 정규화된 이름을 원래 엔티티 정보와 연결합니다. 이 과정은 엔티티 해상도와 비슷하게 느껴집니다.
전반적으로 빌더 모듈의 기능은 현재 일반적인 그래프 작성 기술 스택과 매우 유사하며, 관련 글과 코드도 이해하기 어렵지 않으므로 여기서 반복하지 않겠습니다.
3.2 KAG-Solver
프레임워크의 솔버 부분에는 많은 핵심 기능, 특히 상징적 추론 관련 콘텐츠의 논리가 포함되어 있는데, 먼저 전체적인 구조를 살펴보겠습니다:
❯ tree .
.
├── __init__.py
├── common
│ ├── __init__.py
│ └── base.py
├── implementation
│ ├── __init__.py
│ ├── default_generator.py
│ ├── default_kg_retrieval.py
│ ├── default_lf_planner.py
│ ├── default_memory.py
│ ├── default_reasoner.py
│ ├── default_reflector.py
│ └── lf_chunk_retriever.py
├── logic
│ ├── __init__.py
│ ├── core_modules
│ │ ├── __init__.py
│ │ ├── common
│ │ │ ├── __init__.py
│ │ │ ├── base_model.py
│ │ │ ├── one_hop_graph.py
│ │ │ ├── schema_utils.py
│ │ │ ├── text_sim_by_vector.py
│ │ │ └── utils.py
│ │ ├── config.py
│ │ ├── lf_executor.py
│ │ ├── lf_generator.py
│ │ ├── lf_solver.py
│ │ ├── op_executor
│ │ │ ├── __init__.py
│ │ │ ├── op_deduce
│ │ │ │ ├── __init__.py
│ │ │ │ ├── deduce_executor.py
│ │ │ │ └── module
│ │ │ │ ├── __init__.py
│ │ │ │ ├── choice.py
│ │ │ │ ├── entailment.py
│ │ │ │ ├── judgement.py
│ │ │ │ └── multi_choice.py
│ │ │ ├── op_executor.py
│ │ │ ├── op_math
│ │ │ │ ├── __init__.py
│ │ │ │ └── math_executor.py
│ │ │ ├── op_output
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── get_executor.py
│ │ │ │ └── output_executor.py
│ │ │ ├── op_retrieval
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── get_spo_executor.py
│ │ │ │ │ └── search_s.py
│ │ │ │ └── retrieval_executor.py
│ │ │ └── op_sort
│ │ │ ├── __init__.py
│ │ │ └── sort_executor.py
│ │ ├── parser
│ │ │ ├── __init__.py
│ │ │ └── logic_node_parser.py
│ │ ├── retriver
│ │ │ ├── __init__.py
│ │ │ ├── entity_linker.py
│ │ │ ├── graph_retriver
│ │ │ │ ├── __init__.py
│ │ │ │ ├── dsl_executor.py
│ │ │ │ └── dsl_model.py
│ │ │ ├── retrieval_spo.py
│ │ │ └── schema_std.py
│ │ └── rule_runner
│ │ ├── __init__.py
│ │ └── rule_runner.py
│ └── solver_pipeline.py
├── main_solver.py
├── prompt
│ ├── __init__.py
│ ├── default
│ │ ├── __init__.py
│ │ ├── deduce_choice.py
│ │ ├── deduce_entail.py
│ │ ├── deduce_judge.py
│ │ ├── deduce_multi_choice.py
│ │ ├── logic_form_plan.py
│ │ ├── question_ner.py
│ │ ├── resp_extractor.py
│ │ ├── resp_generator.py
│ │ ├── resp_judge.py
│ │ ├── resp_reflector.py
│ │ ├── resp_verifier.py
│ │ ├── solve_question.py
│ │ ├── solve_question_without_docs.py
│ │ ├── solve_question_without_spo.py
│ │ └── spo_retrieval.py
│ ├── lawbench
│ │ ├── __init__.py
│ │ └── logic_form_plan.py
│ └── medical
│ ├── __init__.py
│ └── question_ner.py
└── tools
├── __init__.py
└── info_processor.py
이전에 솔버 입력 파일에 대해 언급했으므로 관련 코드를 여기에 게시하겠습니다:
class SolverPipeline:
def __init__(self, max_run=3, reflector: KagReflectorABC = None, reasoner: KagReasonerABC = None,
generator: KAGGeneratorABC = None, **kwargs):
"""
Initializes the think-and-act loop class.
:param max_run: Maximum number of runs to limit the thinking and acting loop, defaults to 3.
:param reflector: Reflector instance for reflect tasks.
:param reasoner: Reasoner instance for reasoning about tasks.
:param generator: Generator instance for generating actions.
"""
self.max_run = max_run
self.memory = DefaultMemory(**kwargs)
self.reflector = reflector or DefaultReflector(**kwargs)
self.reasoner = reasoner or DefaultReasoner(**kwargs)
self.generator = generator or DefaultGenerator(**kwargs)
self.trace_log = []
def run(self, question):
"""
Executes the core logic of the problem-solving system.
Parameters:
- question (str): The question to be answered.
Returns:
- tuple: answer, trace log
"""
instruction = question
if_finished = False
logger.debug('input instruction:{}'.format(instruction))
present_instruction = instruction
run_cnt = 0
while not if_finished and run_cnt < self.max_run:
run_cnt += 1
logger.debug('present_instruction is:{}'.format(present_instruction))
# Attempt to solve the current instruction and get the answer, supporting facts, and history log
solved_answer, supporting_fact, history_log = self.reasoner.reason(present_instruction)
# Extract evidence from supporting facts
self.memory.save_memory(solved_answer, supporting_fact, instruction)
history_log['present_instruction'] = present_instruction
history_log['present_memory'] = self.memory.serialize_memory()
self.trace_log.append(history_log)
# Reflect the current instruction based on the current memory and instruction
if_finished, present_instruction = self.reflector.reflect_query(self.memory, present_instruction)
response = self.generator.generate(instruction, self.memory)
return response, self.trace_log
합계 SolverPipeline.run() 방법론에는 3가지 주요 모듈이 포함됩니다:Reasoner, Reflector 노래로 응답 Generator전체적인 논리는 여전히 매우 명확합니다. 먼저 질문에 답을 시도한 다음 문제가 해결되었는지 생각해보고, 그렇지 않은 경우 만족스러운 답을 얻거나 최대 시도 횟수에 도달할 때까지 계속 깊이 생각한다는 것입니다. 이는 기본적으로 복잡한 문제를 해결하는 인간의 일반적인 사고 방식을 모방한 것입니다.
다음 섹션에서는 위에서 언급한 세 가지 모듈에 대해 자세히 분석합니다.
3.3 추론자
추론 모듈은 전체 프레임워크에서 가장 복잡한 부분으로, 핵심 코드는 다음과 같습니다:
class DefaultReasoner(KagReasonerABC):
def __init__(self, lf_planner: LFPlannerABC = None, lf_solver: LFSolver = None, **kwargs):
def reason(self, question: str):
"""
Processes a given question by planning and executing logical forms to derive an answer.
Parameters:
- question (str): The input question to be processed.
Returns:
- solved_answer: The final answer derived from solving the logical forms.
- supporting_fact: Supporting facts gathered during the reasoning process.
- history_log: A dictionary containing the history of QA pairs and re-ranked documents.
"""
# logic form planing
lf_nodes: List[LFPlanResult] = self.lf_planner.lf_planing(question)
# logic form execution
solved_answer, sub_qa_pair, recall_docs, history_qa_log = self.lf_solver.solve(question, lf_nodes)
# Generate supporting facts for sub question-answer pair
supporting_fact = '\n'.join(sub_qa_pair)
# Retrieve and rank documents
sub_querys = [lf.query for lf in lf_nodes]
if self.lf_solver.chunk_retriever:
docs = self.lf_solver.chunk_retriever.rerank_docs([question] + sub_querys, recall_docs)
else:
logger.info("DefaultReasoner not enable chunk retriever")
docs = []
history_log = {
'history': history_qa_log,
'rerank_docs': docs
}
if len(docs) > 0:
# Append supporting facts for retrieved chunks
supporting_fact += f"\nPassages:{str(docs)}"
return solved_answer, supporting_fact, history_log
추론 모듈의 전체 흐름도는 다음과 같습니다(오류 처리와 같은 로직은 생략됨).

다음과 같은 사실을 쉽게 알 수 있습니다.DefaultReasoner.reason() 방법론은 크게 세 단계로 나뉩니다:
- 논리 양식 계획(LFP): 주로 다음을 포함합니다.
LFPlanner.lf_planing - 논리 형식 실행(LFE): 주로 다음을 포함합니다.
LFSolver.solve - 문서 재랭크: 주로 다음이 포함됩니다.
LFSolver.chunk_retriever.rerank_docs
아래에서 세 단계 각각에 대해 자세히 분석합니다.
3.3.1 논리 양식 계획
DefaultLFPlanner.lf_planing() 메서드는 주로 쿼리를 일련의 독립적인 논리 형식으로 분해하는 데 사용됩니다(lf_nodes: List[LFPlanResult]).
lf_nodes: List[LFPlanResult] = self.lf_planner.lf_planing(question)
구현 로직은 다음에서 찾을 수 있습니다. kag/solver/implementation/default_lf_planner.py주요 초점은 다음과 같습니다. llm_output 정규화된 구문 분석을 수행하거나, 제공되지 않은 경우 LLM을 호출하여 새로운 논리 형식을 생성합니다.
주목해야 할 사항은 다음과 같습니다. kag/solver/prompt/default/logic_form_plan.py 관련 사항 LogicFormPlanPrompt 프로젝트의 세부 설계는 복잡한 문제를 여러 개의 하위 쿼리와 그에 해당하는 논리 형식으로 분해하는 방법에 중점을 둡니다.
3.3.2 논리 양식 실행
LFSolver.solve() 메서드는 특정 논리적 형식 문제, 정답 반환, 하위 문제 정답 쌍, 관련 리콜 문서 및 기록 등을 해결하는 데 사용됩니다.
solved_answer, sub_qa_pair, recall_docs, history_qa_log = self.lf_solver.solve(question, lf_nodes)
심층kag/solver/logic/core_modules/lf_solver.py소스 코드 섹션을 찾을 수 있습니다. LFSolver 클래스(논리적 형식 해결사)는 전체 추론 과정의 핵심 클래스로, 논리적 형식(LF)을 실행하고 답을 생성하는 역할을 담당합니다:
- 주요 방법은 다음과 같습니다.
solve쿼리와 논리 형식 노드 세트(List[LFPlanResult]). - 활용
LogicExecutor를 사용하여 답변, 지식 그래프 경로 및 기록을 생성하는 논리적 형태를 수행합니다. - 하위 쿼리 및 답변 쌍과 관련 문서를 처리합니다.
- 오류 처리 및 대체 전략: 답변이나 관련 문서를 찾을 수 없는 경우 다음과 같이 시도합니다.
chunk_retriever관련 문서를 불러옵니다.
주요 프로세스는 다음과 같습니다:

여기에는 다음이 포함됩니다. LogicExecutor 는 더 중요한 클래스 중 하나이며, 핵심 코드는 여기에 게시되어 있습니다:
executor = LogicExecutor(
query, self.project_id, self.schema,
kg_retriever=self.kg_retriever,
chunk_retriever=self.chunk_retriever,
std_schema=self.std_schema,
el=self.el,
text_similarity=self.text_similarity,
dsl_runner=DslRunnerOnGraphStore(...),
generator=self.generator,
report_tool=self.report_tool,
req_id=generate_random_string(10)
)
kg_qa_result, kg_graph, history = executor.execute(lf_nodes, query)
- 구현 로직
LogicExecutor클래스의 관련 코드는 다음과 같습니다.kag/solver/logic/core_modules/lf_executor.py. 그것의execute메서드의 주요 실행 흐름은 아래와 같습니다.
이 실행 흐름은 검색 및 추론에 구조화된 그래프 데이터를 우선적으로 사용하고, 그래프에서 답을 찾을 수 없는 경우 비정형 텍스트 정보 검색으로 되돌아가는 이중 검색 전략을 보여 줍니다.
시스템은 먼저 지식 그래프를 통해 각 논리 표현식 노드에 대해 다양한 액추에이터(deduce및math및sort및retrieval및output등)를 처리하고, 검색 프로세스는 후속 답변 생성을 위해 SPO(주어-술어-객체) 트리플을 수집하며, 그래프가 만족스러운 답변을 제공하지 못하면("모르겠습니다"를 반환), 시스템은 텍스트 블록 검색으로 되돌아가 이전에 얻은 명명된 개체(NER) 결과를 검색 앵커 지점으로 사용하고, 과거 Q&A 기록과 결합하여 문맥 강화 쿼리를 구성한 다음, 이를 통해chunk_retriever검색된 문서를 기반으로 답변을 다시 생성합니다.
전체 프로세스는 우아한 분해 전략으로 볼 수 있으며, 구조화된 지식 그래프와 구조화되지 않은 텍스트 데이터를 결합함으로써 이 하이브리드 검색은 정확성을 유지하면서 최대한 완전하고 맥락적으로 일관된 답변을 제공할 수 있습니다. - 핵심 구성 요소
위에서 설명한 구체적인 구현 로직 외에도, 다음 사항에 유의하세요.LogicExecutor초기화에는 여러 컴포넌트를 전달해야 합니다. 지면 관계상 여기서는 각 컴포넌트의 핵심 기능에 대한 간략한 설명만 하고, 구체적인 구현은 소스 코드를 참조하세요.- kg_retriever: 지식 그래프 리트리버
상담kag/solver/implementation/default_kg_retrieval.py가운데KGRetrieverByLlm(KGRetrieverABC)는 정확/퍼지 및 원홉 하위 그래프와 같은 여러 매칭 방법을 포함하는 엔티티 및 관계 검색을 구현합니다. - 청크 리트리버: 텍스트 청크 리트리버
상담kag/common/retriever/kag_retriever.py가운데DefaultRetriever(ChunkRetrieverABC)여기서의 코드는 먼저 엔티티 처리 측면에서 표준화되어 있으며, 여기서 검색은 HippoRAG를 참조하여 DPR(Dense Passage Retrieval)과 PPR(Personalized PageRank)을 결합한 하이브리드 검색 전략을 채택한 다음 DPR과 PPR Score의 융합에 기반하여 추가로 검색을 수행합니다. 또한, 여기에서는 DPR(Dense Passage Retrieval)과 PPR(Personalised PageRank)을 결합한 하이브리드 검색 전략을 채택하고, 이후 DPR과 PPR 기반 점수를 융합하여 두 검색 방법의 동적 가중치 배분을 추가로 달성합니다. - 엔티티_링커(EL): 엔티티 링커
상담kag/solver/logic/core_modules/retriver/entity_linker.py가운데DefaultEntityLinker(EntityLinkerBase)에서 엔티티 링크 처리를 병렬화하기 전에 피처를 구성하는 아이디어가 사용됩니다. - dsl_runner: 그래프 데이터베이스 쿼리기
상담kag/solver/logic/core_modules/retriver/graph_retriver/dsl_executor.py가운데DslRunnerOnGraphStore(DslRunner)는 구조화된 쿼리 정보를 특정 그래프 데이터베이스 쿼리 문으로 변환하는 역할을 담당하며, 이 부분에는 기본이 되는 특정 그래프 데이터베이스가 포함되며 세부 사항은 비교적 복잡하지만 너무 많이 관여하지는 않습니다.
- kg_retriever: 지식 그래프 리트리버
위의 코드와 순서도를 살펴보면 전체 LFE(논리 양식 실행) 루프가 계층적 처리 아키텍처를 채택하고 있음을 알 수 있습니다:
- 건물 꼭대기
LFSolver전체 프로세스 책임 - 중권역
LogicExecutor특정 논리 형식(LF) 구현을 담당합니다. - (더미의) 바닥
DSL Runner그래프 데이터베이스와의 상호 작용을 담당합니다.
3.3.3 문서 순위 재조정
이 기능을 활성화하면 chunk_retriever를 클릭하면 리콜된 문서도 다시 정렬됩니다.
if self.lf_solver.chunk_retriever:
docs = self.lf_solver.chunk_retriever.rerank_docs(
[question] + sub_querys, recall_docs
)
3.4 리플렉터
Reflector 클래스는 주로 _can_answer 와 함께 _refine_query 전자는 질문에 대한 답변이 가능한지 여부를 결정하는 방법이고, 후자는 멀티홉 쿼리의 중간 결과를 최적화하여 최종 답변의 생성을 유도하는 방법입니다.
관련 구현 참조 kag/solver/prompt/default/resp_judge.py 와 함께 kag/solver/prompt/default/resp_reflector.py 이 두 개의 프롬프트 파일은 이해하기 쉽습니다.
3.5 생성기
스테이플 LFGenerator 클래스를 사용하면 다양한 시나리오(지식 그래프 포함 여부, 문서 포함 여부 등)에 따라 프롬프트 단어 템플릿을 동적으로 선택하고 해당 질문에 대한 답변을 생성할 수 있습니다.
관련 구현은 kag/solver/logic/core_modules/lf_generator.py를 사용하면 코드가 비교적 직관적이며 반복되지 않습니다.
4. 몇 가지 반성
상징적 추론, 지식 정렬 및 일련의 혁신적인 포인트, 포괄적 인 연구를 다루는 전문 도메인 지식 향상 서비스에 초점을 맞춘이 오픈 소스 KAG 프레임 워크는 인덱싱 또는 쿼리 단계에서 시나리오의 전문 지식 스키마에 대한 엄격한 제약의 필요성에 특히 적합하며 전체 워크 플로가 지식 기반의 제약에서 벗어나야한다는 관점을 반복적으로 강화한다고 생각합니다. 그래프를 작성하거나 논리적 추론을 수행해야 합니다. 이러한 사고방식은 도메인 지식이 누락되는 문제와 대규모 모델에 대한 착각을 어느 정도 완화할 수 있습니다.
Microsoft의 GraphRAG 프레임워크가 오픈소스화된 이후 커뮤니티에서는 지식 그래프와 RAG 기술 스택의 통합에 대해 더 많은 고민을 해왔고, 최근 LightRAG, StructRAG 등의 작업으로 많은 유용한 탐색을 해왔습니다.KAG는 기술적 경로에서 GraphRAG와 약간의 차이가 있지만, 특히 지식 정렬 및 추론의 단점을 보완하기 위해 GraphRAG의 전문 영역에서 지식 강화 서비스 방향으로 어느 정도 실천한 것으로 간주할 수 있습니다. KAG와 GraphRAG는 기술적인 측면에서 약간의 차이가 있지만, 특히 지식 정렬과 추론의 단점을 보완하기 위한 전문 영역에서의 지식 강화 서비스 방향의 GraphRAG의 실천이라고 볼 수 있습니다. 이러한 관점에서 저는 개인적으로 이를 지식 제약형 GraphRAG라고 부르는 것을 선호합니다.
다양한 커뮤니티에 기반한 계층적 요약 기능을 갖춘 네이티브 GraphRAG는 비교적 추상적인 상위 수준의 질문에 답할 수 있지만, 쿼리 중심 요약(QFS)에 지나치게 집중하기 때문에 세분화된 사실적인 질문에는 프레임워크가 잘 작동하지 않을 수 있으며 비용 문제를 고려할 때 네이티브 GraphRAG는 펜던트 영역에서 많은 과제를 안고 있는 반면, KAG 프레임워크는 그래프 구성 단계부터 특정 스키마에 기반한 엔티티 정렬 및 표준화 작업 등 최적화를 더 진행했고, 쿼리 단계에서는 기호 논리에 기반한 지식 그래프 추론도 도입했는데, 기호 추론은 그래프 분야에서 꽤 오래 연구되어 왔지만 아직 RAG 시나리오에 실제로 적용된 적은 없습니다. RAG 추론 능력의 강화는 필자가 더 낙관적으로 생각하는 연구 방향이며, 얼마 전 Microsoft는 RAG 기술 스택의 추론 능력을 네 가지 계층으로 요약한 바 있습니다:
- 레벨 1 명시적 사실, 명시적 사실
- 레벨 2 암묵적 사실, 숨겨진 사실
- 레벨 3 해석 가능한 근거, 해석 가능한 (펜던트) 근거
- 레벨 4 숨겨진 이유, 보이지 않는(펜던트 도메인) 이유
현재 대부분의 RAG 프레임 워크의 추론 능력은 여전히 레벨 1 수준에 머물러 있으며 위의 레벨 3 및 레벨 4 수준은 수직 추론의 중요성을 강조하고 있으며 수직 영역의 대형 모델에 대한 지식이 부족하다는 어려움이 있으며 KAG 프레임 워크의 쿼리 단계에서 기호 추론을 도입 한 것은 이러한 방향을 어느 정도 탐구 한 것으로 볼 수 있으며 향후 RAG 추론 영역에서 새로운 연구 물결이 진행될 것으로 예상 할 수 있습니다. RAG 추론은 RL이나 CoT 등과 같은 모델 자체의 추론 능력을 더욱 융합하는 등 새로운 연구의 물결을 일으킬 것으로 예상됩니다. 현 단계에서는 현장 착륙에서 일부 시도가 이루어졌지만 아직 어느 정도 한계가 있습니다.
추론 세션 외에도 검색의 KAG 참조 HippoRAG 하이브리드 DPR 및 PPR 검색 전략의 채택과 PageRank의 효율적인 사용은 기존 벡터 검색에 비해 지식 그래프의 장점을 더욱 잘 보여주며, 앞으로 더 많은 그래프 검색 알고리즘이 RAG 기술 스택에 통합될 것으로 예상됩니다.
물론 KAG 프레임워크는 아직 초기 빠른 반복 단계로, 기존의 논리 형태 계획과 논리 형태 실행이 설계 수준에서 이론적 뒷받침을 완벽하게 하고 있는지, 복잡한 문제에 직면했을 때 불충분한 분해와 실행 실패는 없을지 등 기능의 구체적인 구현에 대해서는 아직 논의의 여지가 있을 것으로 판단됩니다. 불충분 한 분해, 실행 실패가 있을지 여부,이 경계 정의 및 견고성 문제는 일반적으로 처리하기가 매우 어렵지만 많은 시행 착오 비용이 필요하며 전체 추론 체인이 너무 복잡하면 궁극적 인 실패율이 높아질 수 있으며 결국 전략으로의 다양한 분해는 문제를 어느 정도 완화 할뿐입니다. 또한 프레임워크 하단의 GraphStore에는 실제로 증분 업데이트 인터페이스가 예약되어 있지만 상위 계층 애플리케이션에는 관련 기능이 표시되지 않는 것을 발견했는데, 이는 개인적으로 GraphRAG 커뮤니티에서 더 많이 요구하는 기능이기도 합니다.
전반적으로 KAG 프레임워크는 최근 매우 하드코어한 작업으로 여겨지며, 혁신적인 점이 많이 포함되어 있고, 코드의 세부적인 다듬기가 많이 이루어졌으며, 이는 RAG 기술 스택의 연착륙 과정에 중요한 원동력이 될 것으로 여겨집니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서

댓글 없음...