
조이할로란 무엇인가요?
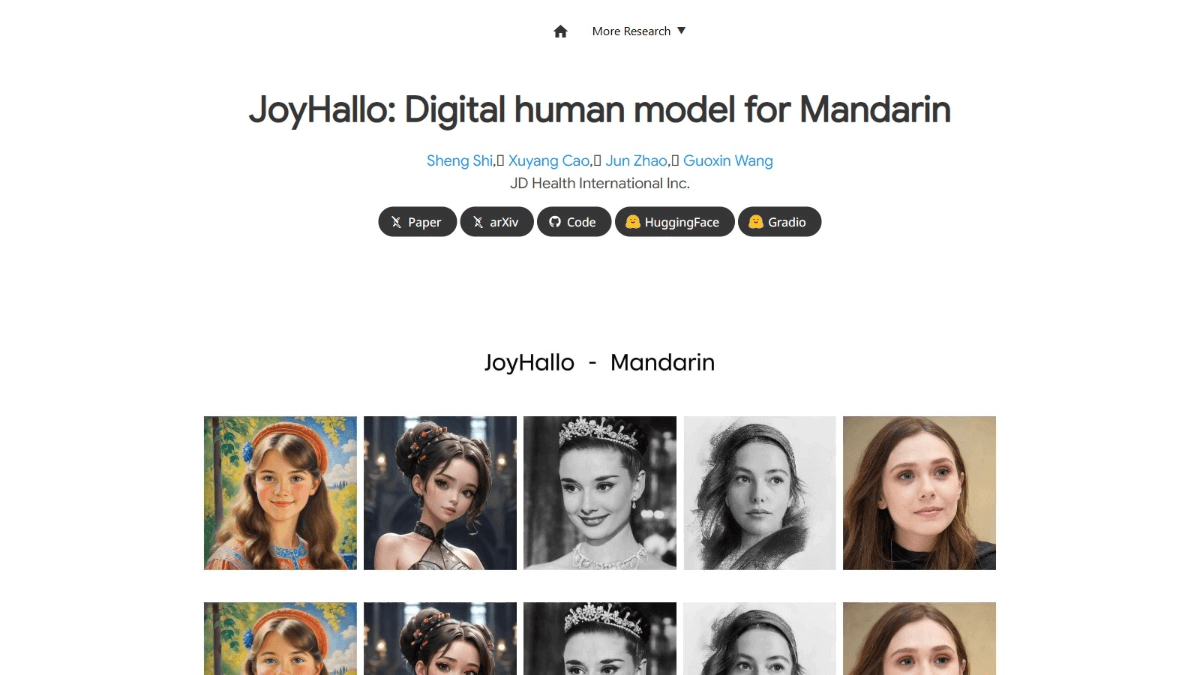
조이할로는 중국어용으로 설계된 징동의 오픈소스 AI 디지털 휴먼 모델로, 오디오를 사실적인 말하기 비디오로 변환하는 것을 지원하며, 조이할로는 반분리 구조의 wav2vec2 모델을 기반으로 오디오 기능을 내장하여 입술 움직임 예측 정확도를 높이고 영어 비디오 생성을 지원하며, 조이할로 학습 데이터 세트는 다양한 연령과 스타일의 중국어 비디오를 다룹니다. 조이할로는 가상 앵커, 온라인 교육, 고객 서비스 및 광고 제작 분야에서 광범위하게 적용되어 효율적이고 생생하며 개인화된 서비스 경험을 제공하고 관련 산업의 지능적인 발전을 촉진할 수 있습니다.
조이할로의 주요 기능
- 오디오 기반 비디오 생성들어오는 오디오 신호에 따라 그에 맞는 말하기 동영상을 자동으로 생성합니다.
- 다국어 생성 능력조이할로는 중국어 동영상 제작에 특화되어 있을 뿐만 아니라 영어 말하기 동영상도 제작할 수 있습니다.
- 립싱크 동기화모델은 오디오와 비디오에서 입술 움직임을 정확하게 동기화합니다.
- 표정 생성오디오의 감정과 목소리 톤에 따라 적절한 얼굴 표정을 생성합니다.
조이할로의 공식 웹사이트 주소
- 프로젝트 웹사이트::https://jdh-algo.github.io/JoyHallo/
- GitHub 리포지토리::https://github.com/jdh-algo/JoyHallo
- 허깅페이스 모델 라이브러리::https://huggingface.co/jdh-algo/JoyHallo-v1
- arXiv 기술 논문::https://arxiv.org/pdf/2409.13268
조이할로 사용 방법
- 환경 준비::
- 하드웨어 요구 사항모델의 추론 프로세스를 가속화하려면 NVIDIA 시리즈 그래픽 카드(예: RTX 30 시리즈 이상)와 같은 고성능 GPU가 탑재된 컴퓨터를 사용하는 것이 좋습니다.
- 소프트웨어 환경파이썬이 시스템에 설치되어 있는지 확인합니다(권장 버전 3.8 이상). 다음 명령어에 따라 PyTorch를 설치합니다(CUDA 버전에 따라 적절한 설치 명령어 선택):
pip install torch torchvision torchaudio- 종속성 설치::
- JoyHallo의 GitHub 리포지토리 복제::
git clone https://github.com/jdh-algo/JoyHallo.git
cd JoyHallo- 프로젝트 종속성 설치::
pip install -r requirements.txt- 데이터 준비트레이닝이나 미세 조정을 위해 자체 데이터를 사용하는 경우, 조이할로의 데이터 형식에 따라 데이터를 준비해야 하며, 조이할로의 데이터 세트에는 일반적으로 오디오 파일과 해당 비디오 파일이 포함되어 있습니다. 오디오 파일은 wav 형식이어야 하고 동영상 파일은 MP4 형식이어야 합니다. 추론에 사전 학습된 모델만 사용하는 경우에는 이 단계를 바로 건너뛰세요.
- 모델 로드 및 추론::
- 사전 학습된 모델 로드조이할로의 사전 학습된 모델은 허깅 페이스 모델 라이브러리를 기반으로 로드됩니다.
from transformers import AutoModelForAudioToVideo, AutoProcessor
model_name = "jdh-algo/JoyHallo-v1"
processor = AutoProcessor.from_pretrained(model_name)
model = AutoModelForAudioToVideo.from_pretrained(model_name)- 오디오 전처리: 오디오 파일을 모델에 필요한 형식으로 변환합니다.::
from datasets import load_dataset
dataset = load_dataset("audiofolder", data_dir="path/to/your/audio/files")
inputs = processor(dataset[0]["audio"], return_tensors="pt")- 비디오 생성모델과 함께 추론하여 동영상을 생성합니다:
outputs = model(**inputs)
video = processor.postprocess_video(outputs)
video.save("output_video.mp4")조이할로의 핵심 강점
- 만다린 최적화조이할로는 중국어용으로 설계되었으며 입술 움직임을 정확하게 일치시켜 중국어에서 "zh", "ch", "sh"와 같은 복잡한 모음과 운율 소리를 정확하게 시뮬레이션할 수 있습니다. zh", "ch", "sh" 등. 오디오의 감정과 억양에 따라 풍부한 표정 생성을 지원하여 영상에 생동감을 더합니다.
- 다국어 역량조이할로는 중국어 외에도 영어 동영상을 생성할 수 있으며 다국적 기업의 고객 서비스, 국제 교육 등 다국어 적용 시나리오를 지원하여 활용도가 넓습니다.
- 효율적인 구조세미 디커플링 구조를 기반으로 오디오 기능 임베딩과 비디오 생성 프로세스가 분리되어 추론 속도가 크게 향상되어 기존 완전 결합 모델보다 14.31 TP3T 빨라졌습니다.
- 다양한 애플리케이션 시나리오조이할로는 가상 앵커(뉴스 방송, 일기 예보, 스포츠 경기 해설), 온라인 교육(어학 학습, 온라인 강좌), 고객 서비스(가상 고객 서비스 담당자) 등 다양한 산업과 시나리오에 적용할 수 있습니다.
- 오픈 소스 리소스일상 대화와 전문 의료 주제를 다루는 다양한 연령과 말하기 스타일의 중국어 비디오 데이터 세트(jdh-Hallo 데이터 세트)가 포함된 오픈 소스 데이터 세트를 제공합니다. 이 프로젝트는 개발자의 커스터마이징 및 최적화를 용이하게 하기 위해 상세한 모델 훈련 방법과 코드를 제공합니다.
조이할로의 대상
- 콘텐츠 크리에이터동영상 제작자와 소셜 미디어 전문가가 고품질의 개인화된 동영상 콘텐츠를 빠르게 생성하여 시간과 비용을 절약하고 콘텐츠의 매력을 높일 수 있습니다.
- 교육자온라인 교육 플랫폼, 학교 및 교육 기관을 위한 가상 교사 이미지를 생성하여 교육 리소스를 풍부하게 하고 생생한 교육 경험을 제공하세요.
- 기업 및 브랜드기업 고객 서비스 부서에서는 서비스 만족도를 높이기 위해 가상 고객 서비스 담당자를 생성하고, 마케팅 팀에서는 광고 효과를 높이기 위해 개인 맞춤형 광고 동영상을 제작합니다.
- 엔터테인먼트 업계 종사자영화 및 TV 제작사, 게임 개발사에서는 제작 효율성을 높이고 제작비를 절감하며 작품의 몰입도와 사실감을 높이기 위해 캐릭터 페이셜 애니메이션을 제작합니다.
- 연구자 및 개발자인공지능 연구자 및 소프트웨어 개발자는 기술 발전을 촉진하고 적용 시나리오를 확장하기 위해 연구 개발을 수행합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...