
정밀 의료 Q&A를 지원하기 위한 DeepSeek R1 모델 미세 조정: 오픈 소스 AI의 잠재력 활용하기

DeepSeek OpenAI의 업계 입지에 도전하기 위해 일련의 고급 추론 모델을 도입했습니다.완전 무료, 사용 제한 없음이 프로그램은 모든 사용자에게 혜택을 제공하도록 설계되었습니다.
이 문서에서는 허깅 페이스의 의료 사고 체인 데이터 세트를 사용하여 DeepSeek-R1-Distill-Llama-8B 모델을 미세 조정하는 방법에 대해 설명합니다. 이 라이트 버전은 DeepSeek-R1 DeepSeek-R1에서 생성된 데이터에 대해 Llama 3 8B 모델을 미세 조정하여 얻은 모델은 원본 모델과 유사한 우수한 추론 성능을 보여줍니다.

DeepSeek R1 복호화
딥서치-R1과 딥서치-R1-Zero는 수학, 프로그래밍 및 논리적 추론 작업에서 OpenAI의 o1 모델보다 뛰어난 성능을 발휘합니다.R1과 R1-Zero는 모두 오픈 소스 모델이라는 점을 언급할 가치가 있습니다..
DeepSeek-R1-Zero
DeepSeek-R1-Zero는 초기 단계로 감독 미세 조정(SFT)을 사용하는 기존 모델과 달리 대규모 강화 학습(RL)만을 사용해 훈련된 최초의 오픈 소스 모델입니다. 이 혁신적인 접근 방식은 모델이 독립적으로 CoT(Chain-of-Thought) 추론을 탐색하여 복잡한 문제를 해결하고 반복적으로 결과를 최적화할 수 있도록 지원합니다. 그러나 이 접근 방식은 추론 단계의 중복 가능성, 가독성 저하, 일관성 없는 언어 스타일 등 몇 가지 문제를 야기하며, 이는 결국 모델의 명확성과 유용성에 영향을 미칩니다.
DeepSeek-R1
이번에 출시된 DeepSeek-R1은 DeepSeek-R1-Zero의 단점을 극복하는 것을 목표로 합니다. 강화 학습에 앞서 콜드 스타트 데이터를 도입함으로써 DeepSeek-R1은 추론 및 비추론 작업 모두에 대해 더욱 강력한 기반을 마련합니다. 이러한 다단계 학습 전략을 통해 DeepSeek-R1은 수학, 프로그래밍, 추론 벤치마크에서 OpenAI-o1 대비 최고 수준의 성능을 달성하고 출력의 가독성과 일관성을 크게 개선할 수 있습니다.
딥시크 증류 모델
DeepSeek는 또한 증류 모델 제품군도 도입했습니다. 이 모델들은 뛰어난 추론 성능을 유지하면서 더 작고 효율적입니다. 매개변수 크기는 15억에서 70억까지 다양하지만, 이 모델들은 모두 강력한 추론 기능을 유지합니다. 그중에서도 DeepSeek-R1-Distill-Qwen-32B는 여러 벤치마크에서 OpenAI-o1-mini 모델보다 성능이 뛰어납니다. 더 작은 규모의 모델은 더 큰 규모의 모델의 추론 패턴을 상속하여 증류 기법의 효과를 충분히 보여줍니다.
-1")
실제 작동 중인 DeepSeek R1 미세 조정
1. 환경 설정
이 모델 미세 조정 작업에서 Kaggle이 클라우드 IDE로 선택된 이유는 Kaggle이 제공하는 무료 GPU 리소스 때문이었습니다. 처음에는 두 개의 T4 GPU가 선택되었지만 한 개만 사용되었습니다. 사용자가 로컬 컴퓨터에서 모델 미세 조정을 수행하려면 최소한 다음이 필요합니다.16GB 메모리가 장착된 RTX 3090 그래픽 카드..
먼저, 사용자의 허깅 페이스가 있는 새 Kaggle 노트북을 시작합니다. 토큰 노래로 응답 가중치 & Biases 토큰이 키로 추가됩니다.
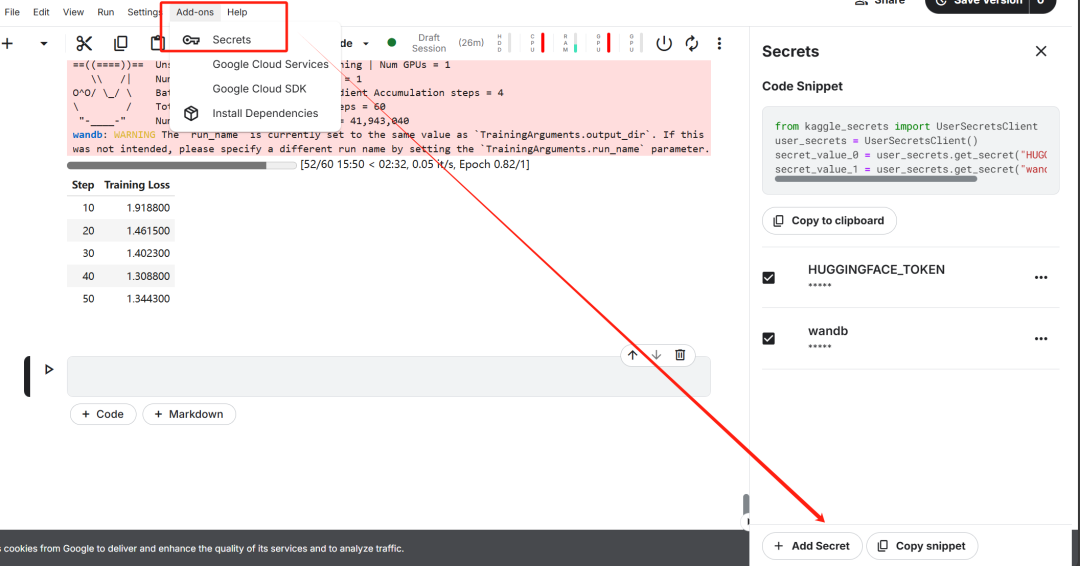
키 설정을 완료한 후 unsloth Unsloth는 대규모 언어 모델(LLM)을 미세 조정하는 속도를 두 배로 높이고 메모리 효율성을 크게 개선하도록 설계된 오픈 소스 프레임워크입니다.
%%capture
!pip install unsloth
!pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
이 단계는 이후 데이터 세트를 다운로드하고 미세 조정된 모델을 업로드하는 데 매우 중요합니다.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)
그런 다음 가중치 및 편향(wandb)에 로그인하고 새 프로젝트를 생성하여 실험 과정을 추적하고 진행 상황을 미세 조정합니다.
import wandb
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune-DeepSeek-R1-Distill-Llama-8B on Medical COT Dataset',
job_type="training",
anonymous="allow"
)
2. 모델 및 토큰화 로딩
이 백서의 실습에서는 DeepSeek-R1-Distill-Llama-8B 모델의 Unsloth 버전이 로드되었습니다.
https://huggingface.co/unsloth/DeepSeek-R1-Distill-Llama-8B
메모리 사용량을 최적화하고 성능을 개선하기 위해 4비트 양자화 방식으로 로드하도록 모델을 선택했습니다.
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit,
token=hf_token,
)
3. 모델 추론 기능 사전 미세 조정 입문서
모델에 대한 프롬프트 템플릿을 구성하기 위해 질문 및 답변 생성을 위한 자리 표시자를 사용하여 시스템 프롬프트를 정의했습니다. 이 프롬프트는 모델이 단계별로 사고하고 궁극적으로 논리적으로 엄격하고 정확한 답변을 생성하는 과정을 안내하기 위한 것입니다.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""
이 예에서는 다음 주소로 메시지가 전송됩니다. prompt_style 의료 문제를 제공하고 토큰으로 변환 한 후 이러한 토큰 를 모델에 전달하여 답을 생성합니다.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
위 의학적 질문의 핵심은 다음과 같습니다:
61세 여성으로 기침이나 재채기 등의 활동 중 불수의적인 소변 누출의 오랜 병력이 있지만 야간 누출은 없습니다. 이 여성은 부인과 검사와 큐팁 검사를 받았습니다. 이러한 결과를 바탕으로 방광 내압 검사를 통해 잔뇨량과 배뇨근 수축 상태에 대해 어떤 정보를 알 수 있을까요?
미세 조정 없이도 모델은 성공적으로 사고의 사슬을 생성하고 최종 답변을 제공하기 전에 엄격한 추론을 수행하며 전체 추론 프로세스는 <think></think> 내 태그.
그렇다면 여전히 미세 조정이 필요한 이유는 무엇일까요? 이 모델은 상세한 추론 과정을 보여 주지만, 그 표현이 다소 길고 간결하지 않습니다. 또한 최종 답변이 글머리 기호 목록으로 표시되어 미세 조정이 예상되는 데이터 집합의 구조와 스타일에서 벗어납니다.
4. 데이터 세트 로드 및 사전 처리
프롬프트 템플릿에서 복잡한 생각의 사슬 열에 세 번째 자리 표시자를 추가하여 데이터 집합의 처리 요구 사항을 수용하도록 프롬프트 템플릿을 미세 조정했습니다.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""
데이터 세트에 '텍스트' 열을 생성하기 위해 Python 함수가 작성되었습니다. 열의 콘텐츠는 각각 질문, 사고 연쇄, 답변으로 채워진 자리 표시자가 있는 교육 프롬프트 템플릿으로 구성됩니다.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}
프리덤인텔리전스/의료-o1-추론-SFT 데이터 세트의 첫 500개 샘플이 허깅 페이스 허브에서 로드되었습니다.
https://huggingface.co/datasets/FreedomIntelligence/medical-o1-reasoning-SFT?row=46
그런 다음 formatting_prompts_func 함수는 데이터 집합의 '텍스트' 열을 매핑합니다.
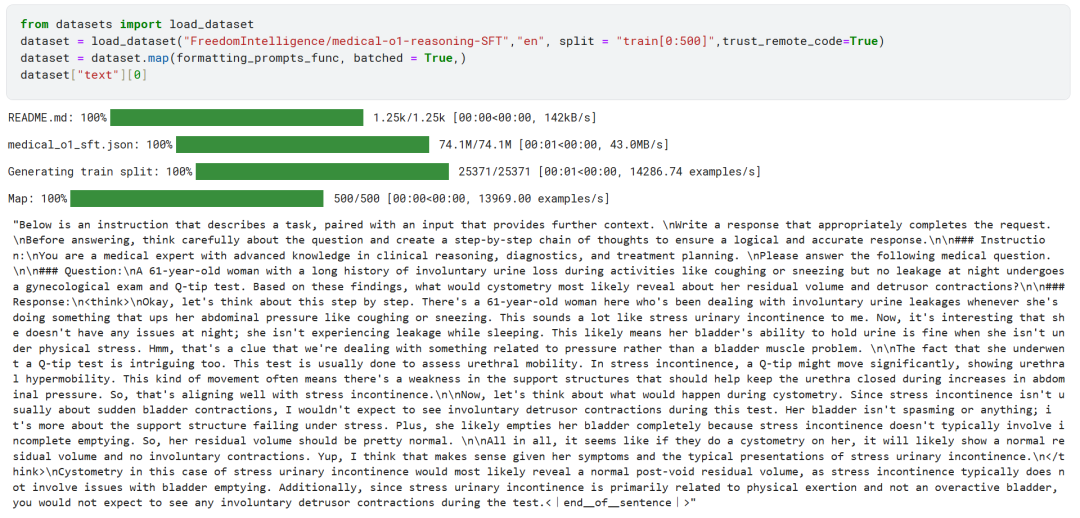
위에서 볼 수 있듯이 '텍스트' 열에는 시스템 힌트, 지침, 사고 사슬, 최종 정답이 성공적으로 통합되어 있습니다.
5. 모델 구성
대상 모듈을 설정하여 로우랭크 어댑터 기법을 사용하여 모델을 구성합니다.
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407,
use_rslora=False,
loftq_config=None,
)
다음으로 트레이닝 파라미터와 트레이너(트레이너)를 구성했습니다. 모델, 토큰화 도구, 데이터 세트 및 기타 주요 학습 매개변수가 트레이너에 제공되어 모델 미세 조정 프로세스를 최적화했습니다.
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
# Use num_train_epochs = 1, warmup_ratio for full training runs!
warmup_steps=5,
max_steps=60,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)
6. 모델 교육
trainer_stats = trainer.train()
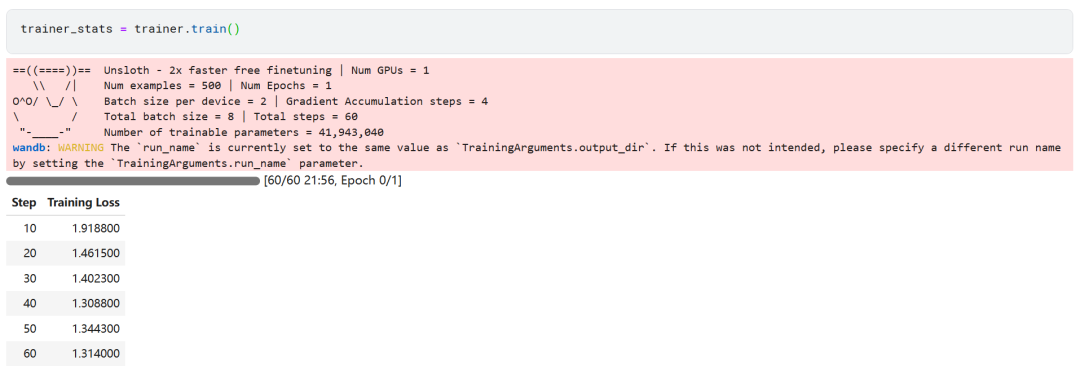
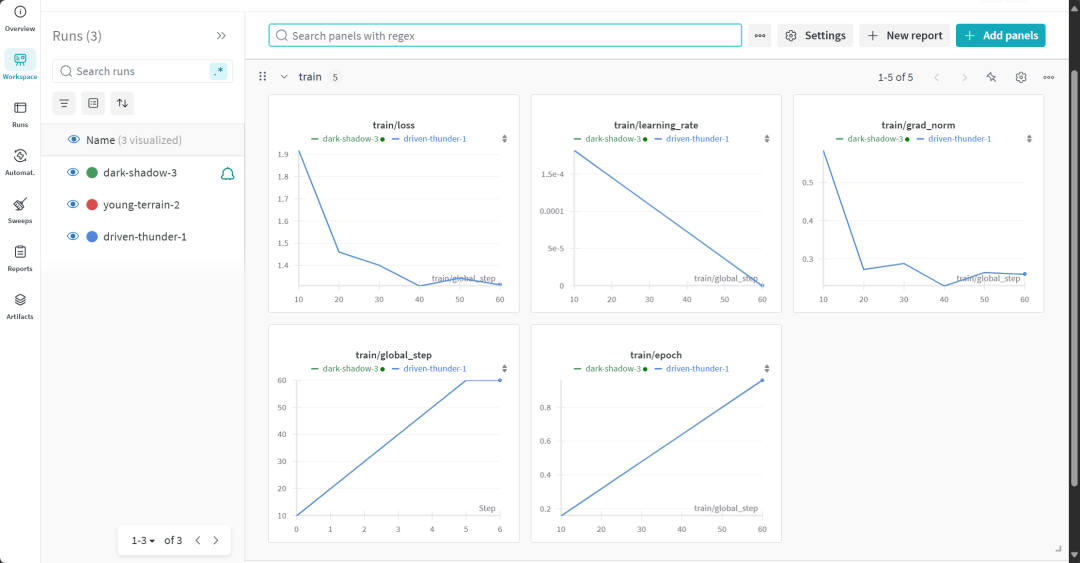
모델 훈련 과정은 22분이 소요되었습니다. 학습 손실(손실)이 점차 감소하여 모델 성능이 향상되었다는 긍정적인 신호입니다.
사용자는 가중치 및 편향성 웹사이트를 방문하여 모델 평가 보고서 전문을 확인할 수 있습니다.
7. 미세 조정된 모델의 추론 능력 평가
비교 분석을 위해 미세 조정된 모델에 미세 조정 전과 동일한 질문을 다시 던져 모델 성능의 변화를 관찰했습니다.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
실험 결과에 따르면 미세 조정된 모델의 출력 품질이 크게 향상되고 답변이 더 정확해졌습니다. 생각의 연결 고리가 더 간결하게 제시되고 최종 답은 단 한 단락으로 더 직접적이고 명확하게 답변되어 이 모델 미세 조정의 성공을 나타냅니다.

8. 모델의 로컬 저장
이제 다른 프로젝트에서 사용할 수 있도록 어댑터, 전체 모델, 토큰라이저를 로컬에 저장합니다.
new_model_local = "DeepSeek-R1-Medical-COT"
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
model.save_pretrained_merged(new_model_local, tokenizer, save_method="merged_16bit")
9. 허깅 페이스 허브에 업로드된 모델
AI 커뮤니티가 이 미세 조정된 모델을 최대한 활용하고 시스템에 쉽게 통합할 수 있도록 하기 위해 어댑터, 토큰라이저 및 전체 모델도 허깅 페이스 허브에 푸시되었습니다.
new_model_online = "realyinchen/DeepSeek-R1-Medical-COT"
model.push_to_hub(new_model_online)
tokenizer.push_to_hub(new_model_online)
model.push_to_hub_merged(new_model_online, tokenizer, save_method="merged_16bit")
요약
인공지능(AI) 분야는 급격한 변화를 겪고 있습니다. 오픈 소스 커뮤니티의 부상은 지난 3년간 독점적인 모델이 지배해 온 AI 환경에 강력한 도전을 제기하고 있습니다. 오픈 소스 대규모 언어 모델(LLM)은 점점 더 빠르고 효율적이므로 적은 계산 및 메모리 리소스로도 그 어느 때보다 쉽게 미세 조정할 수 있습니다.
이 백서에서는 다음과 같이 심층적으로 살펴봅니다. DeepSeek R1 추론 모델을 소개하고, 의료 Q&A 시나리오에 적용하기 위해 라이트 버전을 미세 조정하는 방법을 자세히 설명합니다. 미세 조정된 추론 모델은 성능이 크게 향상되었을 뿐만 아니라 의학, 응급 서비스, 헬스케어와 같은 주요 영역에서 실용적으로 사용할 수 있습니다.
DeepSeek R1의 출시에 맞춰 OpenAI는 두 가지 중요한 도구, 즉 고급 추론 모델인 o3와 연산자 AI 에이전트. 후자는 새로운 컴퓨터 사용 에이전트(컴퓨터 사용 에이전트, CUA)에 의존합니다. 컴퓨터 에이전트 사용) 모델은 웹사이트를 자율적으로 탐색하고 복잡한 작업을 수행할 수 있는 기능을 보여줍니다.
소스 코드:
https://www.kaggle.com/code/realyinchen/deepseek-r1-medical-cot
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서

댓글 없음...