
Crawl4AI 마스터하기: LLM 및 RAG를 위한 고품질 웹 데이터 준비하기

기존의 웹 크롤러 프레임워크는 다목적이지만 데이터를 처리할 때 추가적인 정리 및 서식 지정이 필요한 경우가 많기 때문에 LLM(대규모 언어 모델)과의 통합이 상대적으로 복잡합니다. 많은 도구의 출력(예: 원시 HTML 또는 구조화되지 않은 JSON)에는 많은 노이즈가 포함되어 있으며 검색 증강 생성(RAG)과 같은 시나리오에서 직접 사용하기에는 성능이 저하될 수 있으므로 적합하지 않습니다. LLM 처리의 효율성과 정확성.
Crawl4AI 는 다른 종류의 솔루션을 제공합니다. 깨끗하고 구조화된 데이터를 직접 생성하는 데 중점을 둡니다. Markdown 포맷된 콘텐츠. 이 형식은 원본 텍스트의 의미 구조(예: 제목, 목록, 코드 블록)는 유지하면서 탐색, 광고, 바닥글 등과 같은 불필요한 요소를 지능적으로 제거하므로 다음과 같이 사용하기에 이상적입니다. LLM 입력 또는 고품질 RAG 데이터 세트.Crawl4AI 는 완전한 오픈 소스 프로젝트로서 API 또한 이 키는 유료 시청 임계값으로 설정되어 있지 않습니다.
설치 및 구성
권장 사용 uv 별도의 Python 가상 환경을 사용하여 프로젝트 종속성을 관리합니다.uv 이는 다음을 기반으로 합니다. Rust 개발 중인 신흥 Python 패키지 관리자는 상당한 속도 우위(종종 pip (3~5배 더 빠름) 및 효율적인 병렬 종속성 해결.
# 创建虚拟环境
uv venv crawl4ai-env
# 激活环境
# Windows
# crawl4ai-env\Scripts\activate
# macOS/Linux
source crawl4ai-env/bin/activate
환경이 활성화된 후 uv 마운팅 Crawl4AI 핵심 라이브러리:
uv pip install crawl4ai
설치가 완료되면 초기화 명령을 실행하여 설치 또는 업데이트를 처리합니다. Playwright 필수 브라우저 드라이버(예 Chromium) 및 환경 검사를 수행합니다.Playwright 다음과 같이 구성되는 것들 중 하나입니다. Microsoft 브라우저 자동화 라이브러리를 개발했습니다.Crawl4AI 이를 사용하여 실제 사용자 상호 작용을 시뮬레이션하여 동적으로 로드된 콘텐츠를 처리할 수 있습니다. JavaScript 무거운 웹사이트.
crawl4ai-setup
브라우저 드라이버와 관련된 문제가 발생하면 수동으로 설치를 시도할 수 있습니다:
# 手动安装 Playwright 浏览器及依赖
python -m playwright install --with-deps chromium
필요에 따라 다음과 같이 수행할 수 있습니다. uv 추가 기능이 포함된 확장 팩을 설치합니다:
# 安装文本聚类功能 (依赖 PyTorch)
uv pip install "crawl4ai[torch]"
# 安装 Transformers 支持 (用于本地 AI 模型)
uv pip install "crawl4ai[transformer]"
# 安装所有可选功能
uv pip install "crawl4ai[all]"
기본 크롤링 예제
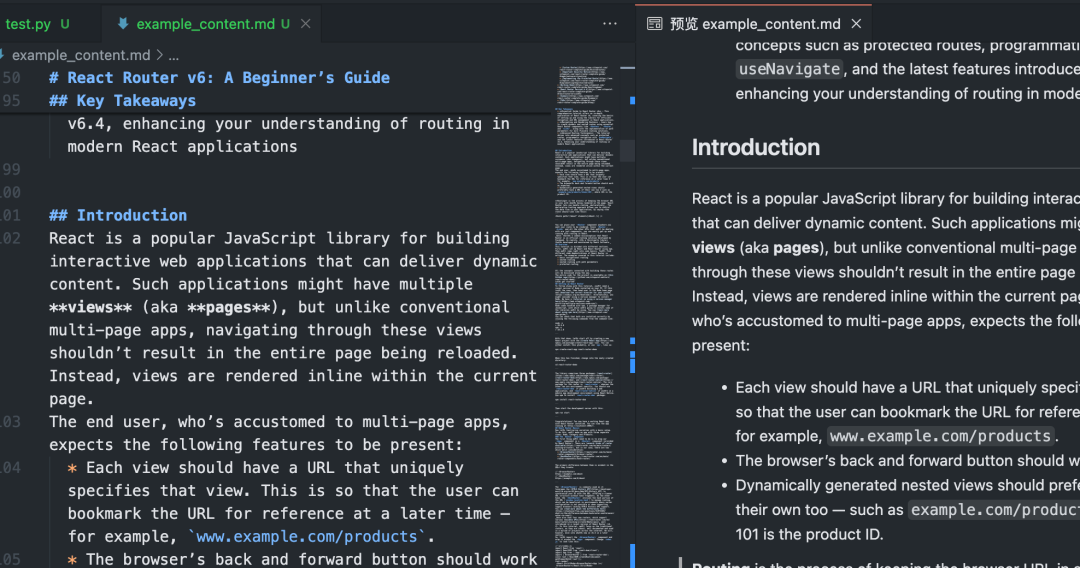
해당 금액 이하 Python 이 스크립트는 Crawl4AI 기본 사용법은 Markdown.
import asyncio
from crawl4ai import AsyncWebCrawler
async def main():
# 初始化异步爬虫
async with AsyncWebCrawler() as crawler:
# 执行爬取任务
result = await crawler.arun(
url="https://www.sitepoint.com/react-router-complete-guide/"
)
# 检查爬取是否成功
if result.success:
# 输出结果信息
print(f"标题: {result.title}")
print(f"提取的 Markdown ({len(result.markdown)} 字符):")
# 仅显示前 300 个字符作为预览
print(result.markdown[:300] + "...")
# 将完整的 Markdown 内容保存到文件
with open("example_content.md", "w", encoding="utf-8") as f:
f.write(result.markdown)
print(f"内容已保存到 example_content.md")
else:
# 输出错误信息
print(f"爬取失败: {result.url}")
print(f"状态码: {result.status_code}")
print(f"错误信息: {result.error_message}")
if __name__ == "__main__":
asyncio.run(main())
이 스크립트를 실행하면Crawl4AI 이 활성화됩니다. Playwright 지정된 브라우저 액세스 제어 URL실행 페이지 JavaScript그런 다음 주요 콘텐츠 영역을 지능적으로 식별 및 추출하고 방해 요소를 필터링하여 궁극적으로 깨끗한 Markdown 문서화.
배치 및 병렬 크롤링
여러 프로세스 URL 언제Crawl4AI 의 병렬 처리를 통해 효율성을 크게 높일 수 있습니다. 병렬 처리의 CrawlerRunConfig 정곡을 찌르세요 concurrency 매개변수를 사용하여 동시에 처리되는 페이지 수를 제어할 수 있습니다.
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
async def main():
urls = [
"https://example.com/page1",
"https://example.com/page2",
"https://example.com/page3",
# 添加更多 URL...
]
# 浏览器配置:无头模式,增加超时
browser_config = BrowserConfig(
headless=True,
timeout=45000, # 45秒超时
)
# 爬取运行配置:设置并发数,禁用缓存以获取最新内容
run_config = CrawlerRunConfig(
concurrency=5, # 同时处理 5 个页面
cache_mode=CacheMode.BYPASS # 禁用缓存
)
results = []
async with AsyncWebCrawler(browser_config=browser_config) as crawler:
# 使用 arun_many 进行批量并行爬取
# 注意:arun_many 需要将 run_config 列表传递给 configs 参数
# 如果所有 URL 使用相同配置,可以创建一个配置列表
configs = [run_config.clone(url=url) for url in urls] # 为每个URL克隆配置并设置URL
# arun_many 返回一个异步生成器
async for result in crawler.arun_many(configs=configs):
if result.success:
results.append(result)
print(f"已完成: {result.url}, 获取了 {len(result.markdown)} 字符")
else:
print(f"失败: {result.url}, 错误: {result.error_message}")
# 将所有成功的结果合并到一个文件
with open("combined_results.md", "w", encoding="utf-8") as f:
for i, result in enumerate(results):
f.write(f"## {result.title}\n\n")
f.write(result.markdown)
f.write("\n\n---\n\n")
print(f"所有成功内容已合并保存到 combined_results.md")
if __name__ == "__main__":
asyncio.run(main())
다음 사항에 유의하십시오.위 코드는 arun_many 메서드를 호출하는 대신 큰 URL 목록을 처리하는 데 권장되는 방법인 arun 더 효율적입니다.arun_many 각각에 해당하는 구성 목록이 필요합니다. URL. 모두 URL 동일한 기본 구성을 사용하여 clone() 메서드는 복사본을 생성하고 특정 URL.
구조화된 데이터 추출(선택기 기반)
를 제외하고 Markdown(수학.) 속Crawl4AI 또한 사용 가능 CSS 선택기 또는 XPath 일반 데이터 형식의 사이트에 적합한 구조화된 데이터를 추출합니다.
import asyncio
import json
from crawl4ai import AsyncWebCrawler, ExtractorConfig
async def main():
# 定义提取规则 (CSS 选择器)
extractor_config = ExtractorConfig(
strategy="css", # 明确指定策略为 CSS
rules={
"products": {
"selector": "div.product-card", # 主选择器
"type": "list",
"properties": {
"name": {"selector": "h2.product-title", "type": "text"},
"price": {"selector": ".price span", "type": "text"},
"link": {"selector": "a.product-link", "type": "attribute", "attribute": "href"}
}
}
}
)
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(
url="https://example-shop.com/products",
extractor_config=extractor_config
)
if result.success and result.extracted_data:
extracted_data = result.extracted_data
with open("products.json", "w", encoding="utf-8") as f:
json.dump(extracted_data, f, ensure_ascii=False, indent=2)
print(f"已提取 {len(extracted_data.get('products', []))} 个产品信息")
print("数据已保存到 products.json")
elif not result.success:
print(f"爬取失败: {result.error_message}")
else:
print("未提取到数据或提取规则匹配失败")
if __name__ == "__main__":
asyncio.run(main())
이 접근 방식에는 다음이 필요하지 않습니다. LLM 비용이 저렴하고 빠른 개입은 대상 요소가 명확한 시나리오에 적합합니다.
AI로 강화된 데이터 추출
구조가 복잡하거나 고정된 패턴이 없는 페이지의 경우 다음을 사용할 수 있습니다. LLM 지능형 추출을 수행합니다.
import asyncio
import json
from crawl4ai import AsyncWebCrawler, BrowserConfig, AIExtractorConfig
async def main():
# 配置 AI 提取器
ai_config = AIExtractorConfig(
provider="openai", # 或 "local", "anthropic" 等
model="gpt-4o-mini", # 使用 OpenAI 的模型
# api_key="YOUR_OPENAI_API_KEY", # 如果环境变量未设置,在此提供
schema={
"type": "object",
"properties": {
"article_summary": {"type": "string", "description": "A brief summary of the article."},
"key_topics": {"type": "array", "items": {"type": "string"}, "description": "List of main topics discussed."},
"sentiment": {"type": "string", "enum": ["positive", "negative", "neutral"], "description": "Overall sentiment of the article."}
},
"required": ["article_summary", "key_topics"]
},
instruction="Extract the summary, key topics, and sentiment from the provided article text."
)
browser_config = BrowserConfig(timeout=60000) # AI 处理可能需要更长时间
async with AsyncWebCrawler(browser_config=browser_config) as crawler:
result = await crawler.arun(
url="https://example-news.com/article/complex-analysis",
ai_extractor_config=ai_config
)
if result.success and result.ai_extracted:
ai_extracted = result.ai_extracted
print("AI 提取的数据:")
print(json.dumps(ai_extracted, indent=2, ensure_ascii=False))
# 也可以选择保存到文件
# with open("ai_extracted_data.json", "w", encoding="utf-8") as f:
# json.dump(ai_extracted, f, ensure_ascii=False, indent=2)
elif not result.success:
print(f"爬取失败: {result.error_message}")
else:
print("AI 未能提取所需数据。")
if __name__ == "__main__":
asyncio.run(main())
AI 추출은 콘텐츠를 이해하고 필요에 따라 구조화된 결과물을 생성할 수 있는 뛰어난 유연성을 제공하지만, 추가 비용이 발생합니다. API 통화 비용(클라우드 서비스를 사용하는 경우) LLM) 및 처리 시간을 선택합니다. 로컬 모델을 선택합니다(예 Mistral, Llama)는 비용을 절감하고 개인 정보를 보호할 수 있지만 로컬 하드웨어 요구 사항이 있습니다.
고급 구성 및 팁
Crawl4AI 복잡한 시나리오를 처리할 수 있는 다양한 구성 옵션을 제공합니다.
브라우저 구성(BrowserConfig)
BrowserConfig 브라우저 자체의 시작 및 동작을 제어합니다.
from crawl4ai import BrowserConfig
config = BrowserConfig(
browser_type="firefox", # 使用 Firefox 浏览器
headless=False, # 显示浏览器界面,方便调试
user_agent="MyCustomCrawler/1.0", # 设置自定义 User-Agent
proxy_config={ # 配置代理服务器
"server": "http://proxy.example.com:8080",
"username": "proxy_user",
"password": "proxy_password"
},
ignore_https_errors=True, # 忽略 HTTPS 证书错误 (开发环境常用)
use_persistent_context=True, # 启用持久化上下文
user_data_dir="./my_browser_profile", # 指定用户数据目录,用于保存 cookies, local storage 等
timeout=60000, # 全局浏览器操作超时 (毫秒)
verbose=True # 打印更详细的日志
)
# 在初始化 AsyncWebCrawler 时传入
# async with AsyncWebCrawler(browser_config=config) as crawler:
# ...
런타임 구성 크롤링(CrawlerRunConfig)
CrawlerRunConfig 컨트롤 싱글 arun() 어쩌면 arun_many() 통화의 특정 동작.
from crawl4ai import CrawlerRunConfig, CacheMode
run_config = CrawlerRunConfig(
cache_mode=CacheMode.READ_ONLY, # 只读缓存,不写入新缓存
check_robots_txt=True, # 检查并遵守 robots.txt 规则
wait_until="networkidle", # 等待网络空闲再提取,适合JS动态加载内容
wait_for="css:div#final-content", # 等待特定 CSS 选择器元素出现
js_code="window.scrollTo(0, document.body.scrollHeight);", # 页面加载后执行 JS 代码 (例如滚动到底部触发加载)
scan_full_page=True, # 尝试自动滚动页面以加载所有内容 (用于无限滚动)
screenshot=True, # 截取页面截图 (结果在 result.screenshot,Base64编码)
pdf=True, # 生成页面 PDF (结果在 result.pdf,Base64编码)
word_count_threshold=50, # 过滤掉少于 50 个单词的文本块
excluded_tags=["header", "nav", "footer", "aside"], # 从 Markdown 中排除特定 HTML 标签
exclude_external_links=True # 不提取外部链接
)
# 在调用 arun() 或创建配置列表给 arun_many() 时传入
# result = await crawler.arun(url="...", config=run_config)
자바스크립트 및 동적 콘텐츠 처리
덕분에 Playwright(수학.) 속Crawl4AI 종속성을 잘 처리합니다. JavaScript 렌더링된 웹사이트. 키 구성:
wait_until: 설정"networkidle"어쩌면"load"일반적으로 기본값보다 조금 더 효율적입니다."domcontentloaded"동적 페이지에 더 적합합니다.wait_for특정 요소를 기다리거나JavaScript조건이 충족되었습니다.js_code페이지 로드 후 사용자 지정 실행JavaScript버튼을 클릭하고 페이지를 스크롤하는 등의 작업을 수행합니다.scan_full_page:: 일반적인 무한 스크롤 페이지를 자동으로 처리합니다.delay_before_return_html모든 스크립트가 실행되도록 추출 전에 짧은 지연 시간을 추가합니다.
오류 처리 및 디버깅
- 프로브
result.success: 크롤링할 때마다 이 속성을 확인해야 합니다. - 체크 아웃
result.status_code노래로 응답result.error_message실패 원인을 파악합니다. - 설정
headless=False: InBrowserConfig브라우저 작동을 관찰하고 문제를 시각적으로 진단할 수 있습니다. - 사용 시작
verbose=True: InBrowserConfig더 자세한 런타임 로그를 얻으려면 설정하세요. - 활용
try...except: 소포arun()어쩌면arun_many()가능한 호출을 캡처하는Python예외.
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig
async def debug_crawl():
# 启用调试模式:显示浏览器,打印详细日志
debug_browser_config = BrowserConfig(headless=False, verbose=True)
async with AsyncWebCrawler(browser_config=debug_browser_config) as crawler:
try:
result = await crawler.arun(url="https://problematic-site.com")
if not result.success:
print(f"Crawl failed: {result.error_message} (Status: {result.status_code})")
else:
print("Crawl successful.")
# ... process result ...
except Exception as e:
print(f"An unexpected error occurred: {e}")
if __name__ == "__main__":
asyncio.run(debug_crawl())
준수 robots.txt
웹 크롤링을 수행할 때는 사이트의 robots.txt 문서화는 기본적인 에티켓이며 IP 차단을 방지하는 역할도 합니다.Crawl4AI 자동으로 처리할 수 있습니다.
존재 CrawlerRunConfig 설정 check_robots_txt=True::
respectful_config = CrawlerRunConfig(
check_robots_txt=True
)
# result = await crawler.arun(url="https://example.com", config=respectful_config)
# if not result.success and result.status_code == 403:
# print("Access denied by robots.txt")
Crawl4AI 자동 다운로드, 캐시 및 구문 분석 robots.txt 파일에 대한 액세스를 금지하는 규칙이 있는 경우 URL(수학.) 속arun() 은 실패합니다.result.success 때문에 False(수학.) 속status_code 일반적으로 적절한 오류 메시지와 함께 403이 표시됩니다.
세션 관리(Session Management)
로그인 또는 상태 유지가 필요한 다단계 작업(예: 양식 제출, 페이지 탐색)의 경우 세션 관리를 사용할 수 있습니다. 이 작업은 새 세션 관리자를 CrawlerRunConfig 에서 동일하게 지정하십시오. session_id이 시스템은 둘 이상의 arun() 호출 간에 동일한 브라우저 페이지 인스턴스가 재사용되어 cookies 노래로 응답 JavaScript 상태.
import asyncio
from crawl4ai import AsyncWebCrawler, CrawlerRunConfig, CacheMode
async def session_example():
async with AsyncWebCrawler() as crawler:
session_id = "my_unique_session"
# Step 1: Load login page (hypothetical)
login_config = CrawlerRunConfig(session_id=session_id, cache_mode=CacheMode.BYPASS)
await crawler.arun(url="https://example.com/login", config=login_config)
print("Login page loaded.")
# Step 2: Execute JS to fill and submit login form (hypothetical)
login_js = """
document.getElementById('username').value = 'user';
document.getElementById('password').value = 'pass';
document.getElementById('loginButton').click();
"""
submit_config = CrawlerRunConfig(
session_id=session_id,
js_code=login_js,
js_only=True, # 只执行 JS,不重新加载页面
wait_until="networkidle" # 等待登录后跳转完成
)
await crawler.arun(config=submit_config) # 无需 URL,在当前页面执行 JS
print("Login submitted.")
# Step 3: Crawl a protected page within the same session
protected_config = CrawlerRunConfig(session_id=session_id, cache_mode=CacheMode.BYPASS)
result = await crawler.arun(url="https://example.com/dashboard", config=protected_config)
if result.success:
print("Successfully crawled protected page:")
print(result.markdown[:200] + "...")
else:
print(f"Failed to crawl protected page: {result.error_message}")
# 清理会话 (可选,但推荐)
# await crawler.crawler_strategy.kill_session(session_id)
if __name__ == "__main__":
asyncio.run(session_example())
고급 세션 관리에는 브라우저의 저장소 상태 내보내기 및 가져오기(cookies, localStorage)를 사용하여 스크립트 실행 사이에 로그인을 유지할 수 있습니다.
Crawl4AI 적절하게 구성하면 다양한 웹사이트에서 필요한 정보를 효율적이고 안정적으로 추출하고 다운스트림 AI 애플리케이션을 위한 고품질 데이터를 준비할 수 있는 강력하고 유연한 기능 세트를 제공합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...