일반인이 DeepSeek-R1을 올바르게 이해하고 사용하는 방법을 알려주는 튜토리얼

DeepSeek-R1 다른 대형 모델에 비해 특별한 점은 없지만, 사고 과정이나 뛰어난 중국어 표현을 보는 것이 놀랍습니다. 사용하신 적이 있다면 ChatGPT 무미건조하다고 느끼신다면 DeepSeek-R1이 가져다준 놀라움은 환상일 수 있습니다. 매일 아이들과 배달로 바쁘다면 딥시크에 신경 쓸 필요도 없고, 시간 낭비만 할 뿐 아무것도 얻을 수 없습니다.
컨텍스트
DeepSeek-R1에 대한 중요한 배경 정보, 가십이 아니라면 건너 뛸 수 있습니다.DeepSeek-R1은 잘 알려진 양적 투자 회사 인 "Mirage Quantitative"에서 태어 났으며 회사의 전체 이름은 "항저우 딥시크 인공지능 기초 기술 연구 유한회사", 설립자 Liang Wenfeng입니다.
딥시크는 2024년 11월 20일 추론 모델 '딥시크-R1-Lite'를 출시했습니다.DeepSeek-R1-Lite는 사용자 인터페이스에서 '딥씽킹'을 켠 상태에서 사용할 수 있습니다. 그러나 DeepSeek-R1-Lite는 더 작은 기본 모델로 학습되어 주목을 덜 받은 반면, DeepSeek-R1은 더 큰 기본 모델인 DeepSeek-V3-Base로 학습되어 전반적인 기능이 크게 향상되었습니다. 따라서 2개월 전 출시된 DeepSeek-R1-Lite는 DeepSeek-R1의 프리뷰 버전입니다. 사용자가 경험할 수 있도록 출시하는 것이 시급합니다 ...
1월 20일, 렁만펑은 중요한 '회의'에 참석하여 연설했고, 같은 날 다음과 같은 성명을 발표했습니다. DeepSeek-R1 기술 보고서네 자의 폭발처럼 우연의 일치 뒤에 어떤 사연이 있는지 궁금합니다...
딥시크릿-R1이 초기에 폭발적인 인기를 끌었던 이유는 주로 기술적인 부분으로, 저비용(5,576,000달러의 GPU 비용, 즉다른 관점은 다음과 같습니다.) 재현했습니다."o1"추론 모델"을 대규모로 실행할 수 있는 하드웨어 리소스가 적고 동시성이 매우 높습니다. 간단히 설명하면 대형 모델의 가격을 낮춰 누구나 더 나은 대형 모델을 사용할 수 있도록 하는 것입니다.
링 밖에서 두 번째는 네자가 화염에 휩싸이는 등 온갖 종류의 뉴스 보도가 네티즌을 폭격할 때입니다....
서클에서 세 번은 뜨거운 "돈"의 물결이있는 셀프 미디어이므로 360 라인 DeepSeek-R1, DeepSeek-R1 로컬 배포 방법, 칭화 대학교에서 DeepSeek-R1 사용법을 가르치는 등 다양한 그룹에서 볼 수 있습니다.
이제 우리는 이제 마지막 단계인 모두를 위한 DeepSeek-R1에 도달했으며, 국유 기업, 중앙 기업, 심지어 구와 군의 거리에서도 이에 대한 소식을 들었을 것입니다.
DeepSeek-R1 사용처
공식 사이트가 막혀서 DeepSeek-R1 모델을 제공하는 다른 서비스를 찾고 있지만, 알고 있는 내용이 모두 틀릴 수 있다는 분들도 많았습니다....

공식 사용 채널
공식 웹사이트: https://chat.deepseek.com/ PC 클라이언트 버전은 없으며, 휴대폰 앱은 주요 애플리케이션 스토어에서 'DeepSeek'를 검색하세요.
기타 사용 채널
현재 많은 AI 도구가 DeepSeek-R1을 통합하고 있지만 출력 품질은 동일하지 않으며, 선택의 어려움을 피하기 위해 원본에 가까운 도구만 추천합니다:
텐센트 위안바오: https://yuanbao.tencent.com/ 공식 웹사이트 및 주요 앱 스토어에서 '위안바오'를 검색하여 다운로드할 수 있는 앱도 제공합니다.
웹 버전을 사용할 때는 다음 옵션을 선택해야 합니다:

로컬 컴퓨터 및 휴대폰에 DeepSeek-R1 설치
먼저 컴퓨터의 GPU가DeepSeek-R1 설치 최소 요구 사항? GPU에 대해 잘 모른다면 로컬 설치를 고려하지 마세요.
PC 설치 DeepSeek-R1
추천 Ollama 설치, 그의 URL은 https://ollama.com/ , 설치할 수 있는 관련 모델은 여기에 있습니다: https://ollama.com/search?q=deepseek-r1 , 설치에 대한 자세한 자습서가 필요한 경우 로컬 설치 및 사용을 권장하지 않습니다.
예를 들어 14B(공식 증류 버전) 모델을 간신히 실행할 수 있는 3060 그래픽 카드는 다음 명령을 복사하여 설치할 수 있습니다:

컴퓨터 구성이 "높음"이고 로컬로 배포하려는 경우 다음 로컬 원클릭 설치 프로그램을 권장합니다.
로컬 설치에는 특정 기술 기반이 필요하며, 여기에서는 DeepSeek-R1과 채팅 인터페이스 로컬 원클릭 설치 패키지를 제공합니다:함정 피하기 가이드: 타오바오 딥시크릿 R1 설치 패키지 유료 상향 판매? 로컬 배포를 무료로 알려드립니다(원클릭 설치 프로그램 포함).
컴퓨터 구성이 "낮음"이고 로컬로 배포하려는 경우 다음 클라우드 배포 옵션을 권장합니다.
로컬 GPU가 없는 프라이빗 배포 DeepSeek-R1 32B
휴대폰에 DeepSeek-R1 설치하기
초점을 묘사하세요!휴대폰에 DeepSeek-R1을 설치할 때 공식 앱을 다운로드할 목적인가요, 아니면 휴대폰에서 로컬로 DeepSeek-R1 모델을 실행할 목적인가요? 휴대폰에서 사용하기만 하고 휴대폰에서 로컬로 실행하지 않으려면 앱 스토어에서 "DeepSeek" 또는 "Tencent Yuanbao"를 검색하여 다운로드할 수 있으며, 두 가지 모두 온라인에서 사용할 수 있습니다. 다음은 휴대폰에서 로컬로 DeepSeek-R1 모델을 실행하는 방법만 설명합니다.
휴대폰에 DeepSeek-R1을 로컬로 설치할 때의 단점:설치된 모델은 간단한 복사, 대조 및 요약 정보를 지능적으로 작성하는 기능이 제한되어 있습니다.
설치하기로 결정한 경우:휴대폰에 DeepSeek-R1 모델 로컬 설치, IOS 및 Android 프리미엄 모델용

DeepSeek-R1의 장점
DeepSeek-R1은 매우 훌륭하고 많은 일을 할 수 있으며 제거부터 시작하여 다음을 이해할 수 있습니다. DeepSeek-R1의 용도가 아닌 것. 저는 약 5000개의 질문을 DeepSeek-R1(풀 버전)에 생성하여 참고할 수 있는 경험을 얻었습니다:
1. 잘못된 질문은 환각을 일으킨다 정답: R1환각은 ChatGPT보다 더 심합니다. 그리고 일반인이 올바르게 "질문"할 수 있는 R1 질문을 하는 것은 본질적으로 어렵기 때문에, 여러분이 얻는 답변은 종종 환각적인 경우가 많습니다.

2. 타임라인 문제와 관련된 연구 과제에 적합하지 않음(1) 대규모 모델로 학습된 지식은 지연이 있고, (2) 네트워크 모드에서도 '심층 사고'는 네트워크 정보를 일회적으로 불러오는 것이기 때문에 불러오는 정보의 수에 제한이 있고 타임라인 문제에 대한 완전한 정보를 수집할 수 없으며, (3) 너무 많은 맥락에 의해 사고에 방해를 받는다는 세 가지 문제가 있습니다(3) 참조).

3. 깊은 사고는 맥락에 의해 쉽게 산만해집니다.와 같은 문제로 웹 검색을 켜면 웹에서 많은 정보가 유입되고 사고 과정에 혼란을 주기 때문에 더 나쁜 결과를 얻게 됩니다. 이것은 심각한 문제입니다.

4.명확한 질문 지시가 '깊은 생각'에 의해 어떻게 방해받을 수 있는지 알아보세요.사고는 다른 맥락을 우선시하여 '주요 지시'를 무시하여 생각이 점차 분산되고 생각을 위한 대기 시간이 과도하게 길어집니다.
문맥이 거의 없는 매우 간단한 작업 지시가 '생각'에 의해 어떻게 손상될 수 있는지 왼쪽의 DeepSeek와 오른쪽의 ChatGPT를 통해 살펴봅시다.


5. 정보만 검색하는 경우 Google과 Baidu에서 더 나은 결과를 얻을 수 있습니다.검색 결과에서 더 많은 정보를 얻으려면 검색 엔진을 사용하는 것이 더 효율적입니다. 특히 정보의 양이 많은 경우 R1은 제한된 양의 정보를 검색하는 데 도움이되고 제한된 양의 정보, 특히 옳고 그름의 검색 결과를 더 제한적으로 판단 할 수있는 능력을 기억할 수 있기 때문에 많은 수의 웹 페이지 정보를 분석하는 데 도움이되지 않으며 추론에 도움이되는 많은 검색 결과의 머리가되어 답을 줄 것입니다.

논문 작성, "데이터" 정보 수집, 정리, 여러 차례의 정보 수집, 여러 차례의 추론 필요성(수동 작업도 동일한 논리), R1은 정보 수집 및 추론의 한 라운드 일 뿐이며 복잡한 시스템 문제를 한 번에 해결할 수 없는 복잡한 시나리오가 있습니다. 이 사실을 알면 관련 정보를 수동으로 수집하고 요약 한 다음 분석을 위해 R1에 던질 수 있습니다.
DeepSeek-R1 올바르게 사용하기
주의:DeepSeek-R1 모델을 사용하지 않더라도 다른 모델을 사용할 때 문제 앞에 "단계별로 생각해 봅시다"라는 문장을 추가하면 다른 모델에서도 자세한 사고 과정을 알려줍니다. 그러나 추론의 세부 수준과 최종 답변은 DeepSeek-R1만큼 좋지 않을 수 있습니다.
사실 DeepSeek-R1을 사용하는 기술은 다른 모델과 크게 다르지 않으며, 몇 가지 세부 사항만 염두에 두어야 합니다.
1. 검색을 켠 후 질문의 복잡성이나 답변이 만족스럽지 않다면 '깊은 생각'을 끄세요. 이 기능을 끈 후에도 여전히 매우 좋은 V3 모델을 사용했습니다.

2. 간단한 지침을 사용하면 딥씽크가 생각에 도움이 됩니다!
정답입니다:번역해 주세요.
오류:중국어로 번역하는 데 도움을 주고, 중국 사용자의 습관과 일치하는 단어를 사용하여 번역하고, 중요한 용어는 원래 언어로 유지해야 하며, 번역은 레이아웃에주의를 기울여야합니다.
더 많은 오류 예시:
1. 여기 많은 내용과 정보가 담긴 매우 중요한 시장 조사 보고서가 있습니다. 주의 깊고 신중하게 읽고 깊이 생각한 다음 분석해 주시기 바랍니다. 이 보고서에서 가장 중요한 시장 동향은 무엇인가요? 가장 중요한 트렌드 세 가지를 나열하고 왜 가장 중요하다고 생각하는지 설명하는 것이 가장 좋을 것 같습니다.
2. 질병 진단 예시: [예시 1], [예시 2] 이제 다음 진료 기록 정보를 바탕으로 환자가 앓고 있을 수 있는 질병을 진단해 주세요. [병력 정보 붙여넣기] 버튼을 클릭합니다.
3. 복잡한 명령을 사용하여 '깊은 사고'를 활성화합니다(복잡한 명령과 너무 많은 컨텍스트를 전달하면 R1 모델에 혼란을 줄 수 있으므로 경험 없이 복잡한 명령을 구성하는 것은 권장하지 않습니다).
정답입니다:중국어로 번역하는 데 도움을 주고, 중국 사용자의 습관과 일치하는 단어를 사용하여 번역하고, 중요한 용어는 원래 언어로 유지해야 하며, 번역은 레이아웃에주의를 기울여야합니다.
오류:번역해 주세요.
참고: 2와 3에서 발생하는 충돌을 변증법적으로 살펴보기 위해 간단한 명령어부터 시도해보고, 특정 요구 사항을 충족하지 못하면 명령어 조건을 적절히 늘려보세요.
다음 텍스트로 자신을 테스트해 보세요.
**# How does better chunking lead to high-quality responses? **If you’re reading this, I can assume you know what chunking and RAG are. Nonetheless, here is what it is, in short.** **LLMs are trained on massive public datasets. Yet, they aren’t updated afterward. Therefore, LLMs don’t know anything after the pretraining cutoff date. Also, your use of LLM can be about your organization’s private data, which the LLM had no way of knowing.** **Therefore, a beautiful solution called RAG has emerged. RAG asks the LLM to ** answer questions based on the context provided in the prompt itself** . We even ask it not to answer even if the LLM knows the answer, but the provided context is insufficient.** **How do we get the context? You can query your database and the Internet, skim several pages of a PDF report, or do anything else.** **But there are two problems in RAGs.** * **LLM’s **context windows sizes** are limited (Not anymore — I’ll get to this soon!)** * **A large context window has a high ** signal-to-noise ratio** .** **First, early LLMs had limited window sizes. GPT 2, for instance, had only a 1024 token context window. GPT 3 came up with a 2048 token window. These are merely the **size of a typical blog post** .** **Due to these limitations, the LLM prompt cannot include an organization’s entire knowledge base. Engineers were forced to reduce the size of their input to the LLM to get a good response.** **However, various models with a context window of 128k tokens showed up. This is usually **the size of an annual report** for many listed companies. It is good enough to upload a document to a chatbot and ask questions.** **But, it didn’t always perform as expected. That’s because of the noise in the context. A large document easily contains many unrelated information and the necessary pieces. This unrelated information drives the LLM to lose its objective or hallucinate.** **This is why we chunk the documents. Instead of sending a large document to the LLM, we break it into smaller pieces and only send the most relevant pieces.** **However, this is easier said than done.** **There are a million possible ways to break a document into chunks. For instance, you may break the document paragraph by paragraph, and I may do it sentence by sentence. Both are valid methods, but one may work better than the other in specific circumstances.** **However, we won’t discuss sentence and paragraph breaks, as they are trivial and have little use in chunking. Instead, we will discuss slightly more complex ones that break documents for RAGs.** **In the rest of the post, I’ll discuss a few chunking strategies I’ve learned and applied.********
4. 큐 단어 프레임이 유효하게 유지됩니다.
좋은 단서를 입력하는 습관을 들이기 위해서는 [캐릭터] [큰 모델이 수행할 행동] [미션 목표] [미션 맥락](미션 맥락은 필요 없음)의 네 가지 조건만 있으면 됩니다.
예시:공식 문서 작성에서 전문가로서의 역할을 수행합니다."올해의 직원 컨퍼런스"에서의 연설에 대한 보고서를 작성하는 데 도움을 주세요. 연설은 5분 정도이며 성실하고 겸손하게 작성해야 합니다.회사 이름은 PetroChina, 상사의 이름은 Li Fugui, 저는 석유 탐사 분야에서 일하고 있으며 직원들의 투표에서 2위를 차지해 상을 받았습니다.

5. 큰 모델을 통해 질문하는 법 배우기, 좋은 질문은 좋은 답변으로 이어집니다.
제시된 프롬프트의 예시인 "4번"을 다시 살펴보면 어떤 문제가 있나요?
직접 사용할 수 없는 보고서를 작성할 만큼 설명이 상세하지 않고, 대부분의 사람들이 큰 모델에서 겪는 어려움은 질문을 할 수 없거나 머릿속에 질문을 추가하는 것을 귀찮아한다는 것입니다.
완벽한 질문을 구성하기 전에 큰 모델을 통해 질문을 다듬는 방법을 배우면 질문을 구체화하는 데 도움이 됩니다.

6. 질문을 유도하거나 R1의 사고 과정을 유도하는 것은 R1에게만 적용되는 매우 오래된 방법입니다.
다음 방법은 일반적으로 R1과 같은 추론 모델에서 사용할 필요는 없지만 문제에 따라 다르며, 문제가 매우 직접적인 경우 다음 방법 중 일부를 포함할 수 있습니다.논리적으로 간단하고 짧은 문맥을 설명하세요..
| Prompt_ID | 유형 | 트리거 문장 | 중국어 |
|---|---|---|---|
| 101 | CoT | 차근차근 생각해 봅시다. | 단계별로 생각합니다. |
| 201 | PS | 먼저 문제를 이해하고 문제 해결을 위한 계획을 세운 다음, 단계별로 문제 해결을 위한 계획을 실행해 봅시다. | 먼저 문제를 이해하고 이를 해결하기 위한 계획을 세웁니다. 그런 다음 계획에 따라 단계별로 문제를 해결해 봅시다. |
| 301 | PS+ | 먼저 문제를 이해하고 관련 변수와 해당 숫자를 추출하여 계획을 세운 다음 계획을 실행하고 중간 변수를 계산하고 (정확한 숫자 계산과 상식에주의하고 문제를 단계별로 해결하고 답을 보여주세요.) 계획을 실행하고 중간 변수를 계산하고 (정확한 숫자 계산과 상식에주의하고) 문제를 단계별로 해결하고 답을 보여주세요. 그런 다음 계획을 수행하고 중간 변수를 계산하고 (정확한 숫자 계산과 상식에주의) 문제를 단계별로 해결하고 답을 보여 드리겠습니다. | 먼저 문제를 이해하고 관련 변수와 해당 값을 추출한 다음 계획을 세웁니다. 그런 다음 계획을 실행하고 중간 변수를 계산하고(적절한 숫자 계산과 상식에 유의) 문제를 단계별로 풀고 답을 표시합니다. |
| 302 | PS+ | 먼저 문제를 이해하고 관련 변수와 해당 숫자를 추출하고 완전한 계획을 수립 한 다음 계획을 수행하고 중간 변수를 계산하고 (올바른 수치 계산 및 상식에주의) 문제를 단계별로 해결하고 다음을 보여 드리겠습니다. 그런 다음 계획을 수행하고 중간 변수를 계산하고 (올바른 수치 계산과 상식에주의) 문제를 단계별로 해결하고 답을 보여주세요. | 먼저 문제를 이해하고 관련 변수와 해당 값을 추출한 후 완전한 계획을 세웁니다. 그런 다음 계획을 실행하고 중간 변수를 계산하고(정확한 수치 계산과 상식에 주의) 문제를 단계별로 해결하고 답을 표시합니다. |
| 303 | PS+ | 계획을 세우고 단계별로 문제를 해결해 봅시다. | 계획을 세우고 한 번에 한 단계씩 문제를 해결해 보세요. |
| 304 | PS+ | 먼저 문제를 이해하고 완전한 계획을 세운 다음, 계획과 추론 문제를 단계별로 수행해 봅시다. 각 단계마다 "사람이 동전을 뒤집고 동전의 현재 상태는 무엇인가?"라는 하위 질문에 답하세요. 동전의 마지막 상태에 따라 최종 답을 제시하세요(모든 뒤집기와 동전의 회전 상태에 주의를 기울이세요). | 먼저 문제를 이해하고 완전한 계획을 세웁니다. 그런 다음 계획을 실행하고 문제를 단계별로 해결합니다. 각 단계는 "사람이 동전을 뒤집는가, 동전의 현재 상태는 무엇인가?"라는 하위 질문에 답합니다. . 동전의 최종 상태를 기준으로 최종 답을 제시합니다(각 뒤집기와 동전의 뒤집힌 상태를 기록하세요). |
| 305 | PS+ | 먼저 문제를 이해하고 관련 변수와 해당 숫자를 추출하고 완전한 계획을 세운 다음 계획을 수행하고 중간 변수를 계산하고 (정확한 수치 계산과 상식에주의) 문제를 단계별로 해결하고 다음을 보여 주겠습니다. 그런 다음 계획을 수행하고 중간 변수를 계산하고 (올바른 수치 계산과 상식에주의) 문제를 단계별로 해결하고 답을 보여주세요. | 먼저 문제를 이해하고 관련 변수와 해당 값을 추출한 후 완전한 계획을 세웁니다. 그런 다음 계획을 실행하고 중간 변수를 계산하고(정확한 수치 계산과 상식에 주의) 문제를 단계별로 해결하고 답을 표시합니다. |
| 306 | PS+ | 먼저 관련 정보를 준비하고 계획을 세운 다음, 상식과 논리적 일관성에 주의하여 단계별로 질문에 답해 봅시다. 그런 다음 단계별로 질문에 답해 봅시다(상식과 논리적 일관성에 주의하세요). | 먼저 관련 정보를 준비하고 계획을 세우세요. 그런 다음 상식과 논리적 일관성에 주의를 기울여 단계별로 질문에 답하세요. |
| 307 | PS+ | 먼저 문제를 이해하고 관련 변수와 해당 숫자를 추출하고 완전한 계획을 세우고 고안 한 다음 계획을 수행하고 중간 변수를 계산하고 (정확한 수치 계산과 상식에주의) 문제를 단계별로 해결하고 단계별로 문제를 해결합시다. 그런 다음 계획을 수행하고 중간 변수를 계산하고 (정확한 수치 계산과 상식에주의) 문제를 단계별로 해결하고 답을 보여주세요. | 먼저 문제를 이해하고 관련 변수와 해당 값을 추출한 후 완전한 계획을 세웁니다. 그런 다음 계획을 실행하고 중간 변수를 계산하고(정확한 수치 계산과 상식에 주의) 문제를 단계별로 해결하고 답을 표시합니다. |
7. 질문의 모호성 해소
앞서 언급한 잘못된 예와 같이 잘못된 질문이 잘못된 가정과 잘못된 답변으로 이어지는 경우, 추론의 큰 모델은 질문을 '가정'하는 데 도움이 되므로 경험을 바탕으로 질문의 모호성을 적극적으로 배제하는 것이 중요합니다.
8. 입력 길이와 추론의 깊이 중에서 선택합니다.
너무 긴 입력은 추론을 억제하고 추론 문제를 확산시키며, 짧은 입력은 추론을 강화하고 집중력을 유지하며 상호 배타적입니다.
9. 출력 콘텐츠 형식 제어
큐 워드 프레임워크인 "4"를 참조하세요. 마지막 섹션에 [출력 형식]을 추가하여 대형 모델의 출력 콘텐츠 형식을 제한할 수 있습니다.
제어 출력 콘텐츠 형식에는 두 가지 유형이 있습니다:
1. 타이포그래피
예 1: 콘텐츠의 마크다운 서식 및 레이아웃을 사용한 출력
예 2: 출력 문서를 워드에 붙여넣어 사용할 수 있습니다.
2.템플릿
예 1: 소개, 설명, 요약의 세 부분으로 나눌 글 생성하기
예 2:프롬프트: 그룹 채팅 요약, 회의 노트, 다자간 대화 요약 등
DeepSeek-R1에서 확장된 읽기
DeepSeek-R1 WebGPU: 브라우저에서 로컬로 DeepSeek R1 1.5B를 실행하세요!
Tifa-DeepsexV2-7b-MGRPO: 32b 이상의 성능으로 롤플레잉 및 복잡한 대화를 지원하는 모델(원클릭 인스톨러 사용)
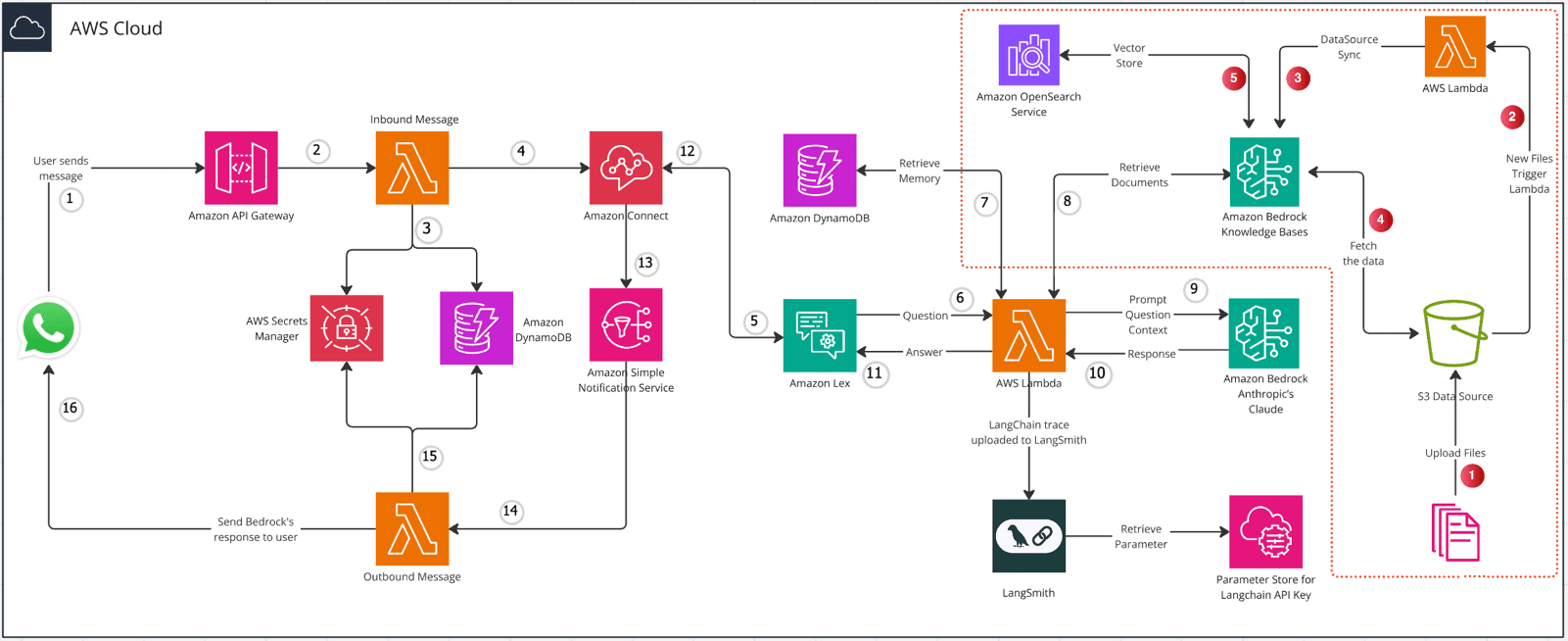
DeepSeek-R1을 기반으로 로컬/API 지식 베이스를 구현하고 WeChat BOT에 액세스하기
딥시크 공식 추천: 딥시크 R1이 통합된 실용적인 AI 도구 가이드
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...