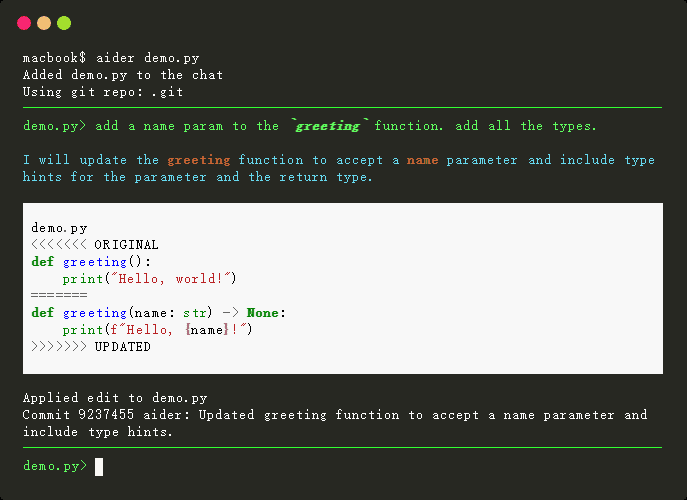

InternSVG是什么
InternSVG 是上海AI实验室联合上海交通大学、南京大学等机构推出的统一矢量图形智能系统,系统基于多模态大语言模型(MLLM),首次实现了SVG理解、编辑、生成三大任务的统一建模,包含1600万样本的SAgoge数据集、SArena评测基准及InternSVG核心模型,在语义理解准确率高达99.7%,显著超越GPT-4o和Claude-4-Sonnet等商业模型。
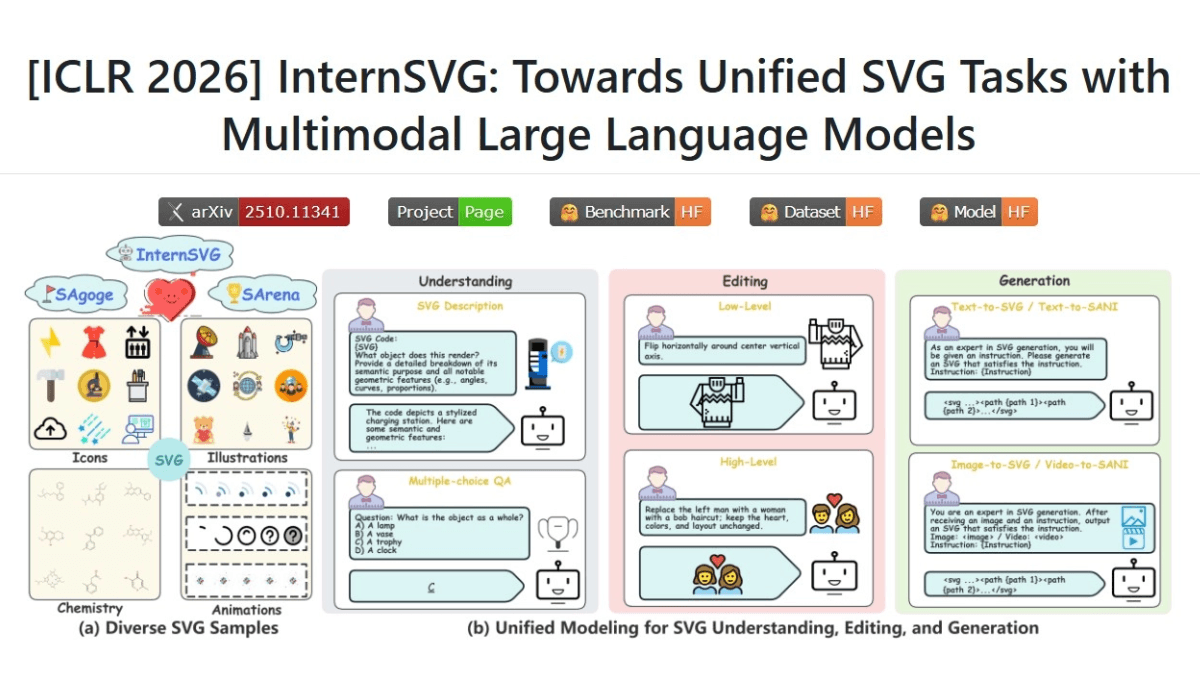
InternSVG的功能特色:
- 统一任务建模:单模型同时支持SVG代码理解(问答/描述)、图形编辑(颜色/样式/几何变换)和文生图/图生图生成。
- 专用Token体系:设计55种SVG标签Token和42种属性Token,结合-128至128整数Token及小数Token,精准表示SVG语法结构,显著压缩序列长度。
- 双模态处理:支持静态图形(图标、插图、化学结构)和动态动画(SMIL动画、视频转动画)的生成与理解。
- 代码高效生成:生成的SVG图标平均仅需约1000字符,远低于传统方法的万级字符量,优化存储与渲染性能。
- 正向迁移学习:统一训练使理解、编辑、生成任务相互促进,实现"1+1+1>3"的协同效应。
InternSVG的核心优势
- 首创统一任务框架:首个将SVG理解、编辑、生成三大任务统一在单一MLLM模型中的系统,实现任务间的正向迁移,达到"1+1+1>3"的协同效果,无需为不同任务切换多个专用模型。
- 专用SVG Token体系:设计55种SVG标签Token和42种属性Token,结合整数/小数Token精准表示SVG语法结构,相比通用文本编码显著压缩序列长度,提升模型对矢量语法的解析能力。
- 超大规模训练数据:构建1600万样本的SAgoge数据集,涵盖图标、插图、化学结构、动画四大领域,是迄今规模最大的SVG多模态数据集,为模型泛化能力提供数据支撑。
- 性能超越商业模型:在SVG理解任务中准确率高达99.7%,显著优于GPT-4o、Claude-4-Sonnet等商业多模态大模型,在编辑和生成任务上同样保持领先。
- 静态与动态双支持:支持静态矢量图形(图标、插图、化学结构),首创支持SMIL动画生成、视频转SVG动画等动态内容创作,覆盖完整SVG应用场景。
- 极致代码压缩率:生成的SVG图标平均仅需约1000字符,相比传统矢量化管线产生的万级字符量,存储效率提升10倍以上,直接降低网络传输和渲染开销。
InternSVG官网是什么
- GitHub 리포지토리:https://github.com/hmwang2002/InternSVG
- 허깅페이스 모델 라이브러리:https://huggingface.co/InternSVG/InternSVG-8B
- arXiv 기술 논문:https://arxiv.org/pdf/2510.11341
使用InternSVG的操作步骤
- 환경 준비:通过GitHub项目页获取代码,配置InternViT-300M视觉编码器与Qwen2.5-7B语言模型基础环境。
- 데이터 준비:使用SAgoge数据集进行训练,或加载预训练权重(8B参数版本),支持图标、插图、化学分子、动画四类数据格式。
- 任务调用:通过API或代码输入SVG代码/文本描述/光栅图像,模型直接输出SVG代码字符串或回答。
- 推理应用:使用SArena基准进行性能评估,或通过Hugging Face等平台加载模型进行自定义SVG任务推理。
InternSVG的适用人群
- 프런트엔드 개발 엔지니어:需要批量生成或优化网页图标、插图SVG代码,减少手写工作量。
- UI/UX 디자이너:通过自然语言描述快速生成矢量图形原型,实现"所想即所得"的创意表达。
- 科研教育人员:制作化学分子结构、科学图表等精确SVG图形,支持学术可视化需求。
- AI研究者:从事多模态大模型、矢量图形理解、代码生成等领域的学术研究。
- 애니메이터:需要将文本或视频转换为SVG动画(SMIL格式)的动态内容创作者。
InternSVG的常见问题FAQ
Q:InternSVG与现有矢量图形工具(如Adobe Illustrator)有什么区别?
A:InternSVG是首个基于MLLM的统一SVG智能模型,能直接通过自然语言理解、编辑和生成SVG代码,而传统工具依赖人工操作。在代码简洁度(平均1000字符)和语义理解(99.7%准确率)上显著优于传统矢量化管线。
Q:支持哪些SVG任务类型?
A:覆盖三大类任务:理解(描述、问答)、编辑(颜色/描边/几何变换/语义编辑/风格迁移)、生成(文生SVG、图生SVG、文生动画、视频生动画),支持图标、长序列插图、化学结构、动画四种数据域。
Q:InternSVG的模型架构是什么?
A:采用"ViT-MLP-LLM"架构,使用InternViT-300M作为视觉编码器,Qwen2.5-7B作为语言模型,配备SVG专用特殊Token和基于子词的嵌入初始化策略。
Q:训练数据规模有多大?
A:核心数据集SAgoge包含超过1600万个训练样本,涵盖静态图形和动态动画,是目前最大规模的SVG多模态数据集。
Q:是否需要商业授权?
A:作为学术研究项目,代码和模型权重通常遵循开源协议(具体需查看GitHub仓库License),但商用需关注上海AI实验室的相关授权条款。
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...