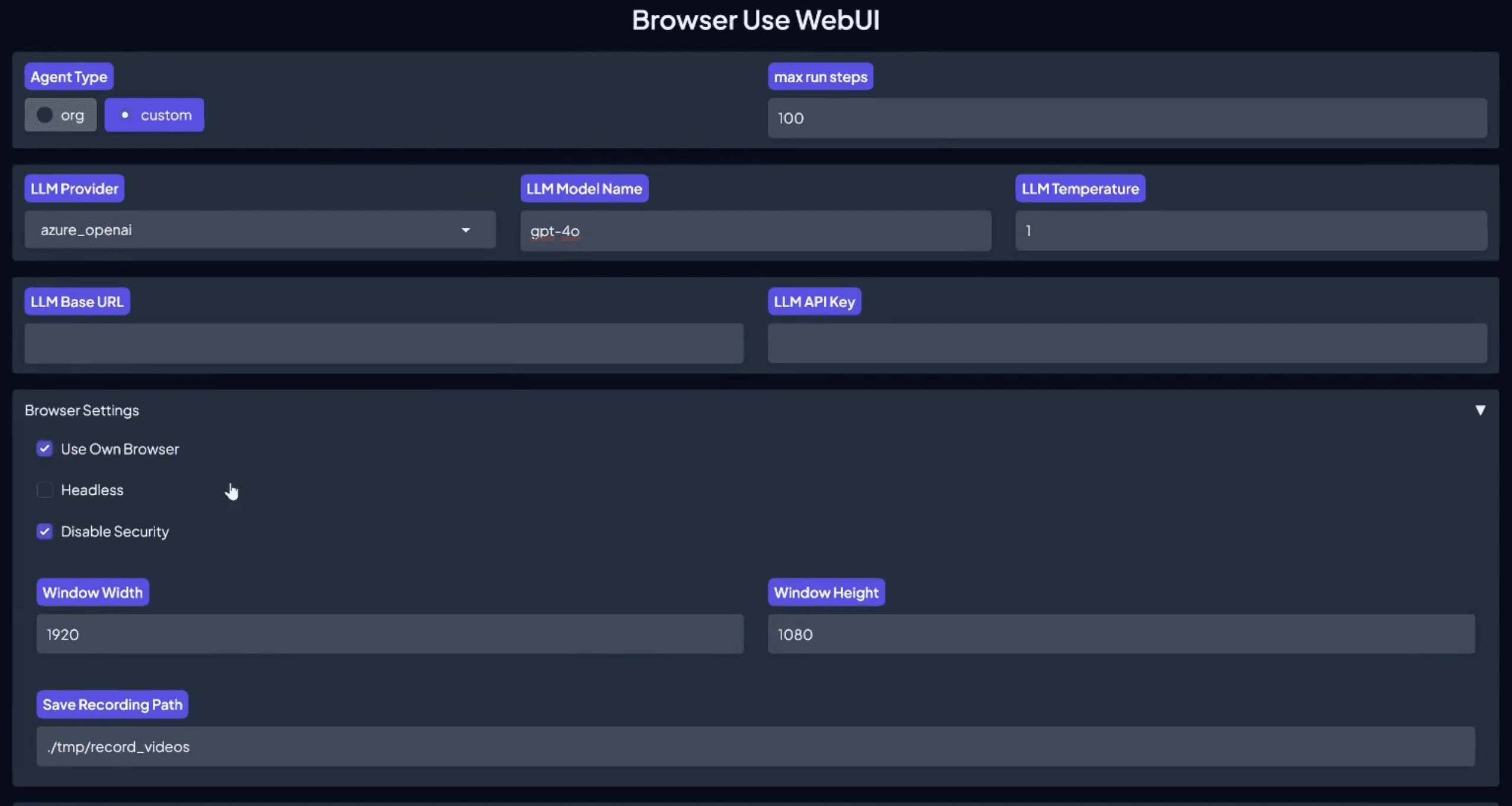

일반 소개
엄청나게 빠른 속삭임은 OpenAI의 속삭임 모델과 다양한 최적화 기술(예: 트랜스포머, 옵티멈, 플래시 어텐션)을 결합하여 대량의 오디오를 빠르고 효율적으로 전사하도록 설계된 명령줄 인터페이스(CLI)를 제공하는 오디오 전사 툴입니다. Whisper Large v3 모델을 사용하며 150분 분량의 오디오 콘텐츠를 98초 이내에 트랜스크립션할 수 있습니다. 자세한 내용, 설치 가이드, 사용 도움말은 GitHub 리포지토리를 통해 확인할 수 있습니다.
다중 화자 인식
pyannote.audio는 파이썬으로 작성된 화자 일기를 위한 오픈 소스 툴킷입니다. 파이토치 머신 러닝 프레임워크를 기반으로 하며, 사전 학습된 최신 모델과 파이프라인을 통해 자체 데이터를 더욱 미세 조정하여 성능을 향상시킬 수 있습니다.
faster-whisper + pyannote.audio는 실제로 두 가지의 결과를 결합하여 화자 인식을 구현합니다.
공식 창고: https://github.com/pyannote/pyannote-audio
기능 목록
Whisper 대형 v3 모델을 사용한 오디오 트랜스 크립 션
트랜스포머, 옵티멈, 플래시 어텐션 및 기타 기술 채택
CLI 인터페이스 제공
다양한 최적화 유형 지원 및 벤치마크 표시
도움말 사용
설치: pip를 사용한 설치 및 구성
사용법: 명령줄에서 직접 매개변수를 전달하고 전사 작업을 실행합니다.
도움 받기: GitHub 리포지토리를 방문하여 문서를 읽고 커뮤니티에 문의하세요.
https://github.com/SYSTRAN/faster-whisper项目编写的구글 콜라보 코드
# 필요한 라이브러리 설치하기get_ipython().system('pip install faster-whisper')# 필요한 라이브러리 가져오기FROM FASTER_WHISPER 가져오기 가능_모델토치 가져오기위젯으로 ipywidgets 가져오기IPython.display에서 display, clear_output을 가져옵니다.파일 작업 처리를 위한 운영 체제 라이브러리 가져오기 # 가져오기import gc # 쓰레기 수집 라이브러리 가져오기# 장치 유형을 자동으로 감지하고 GPU 또는 CPU를 선택합니다.device = "cuda" if torch.cuda.is_available() else "cpu"model_size = "large-v2" # 모델 사이즈의 기본 선택 사항compute_type = "float16" if device == "cuda" else "float32" # CPU를 사용하는 경우 float32로 전환합니다.# 사용 가능한 모델 목록 보기models_list = available_models()# 기본 언어 목록supported_languages = ['en', 'fr', 'de', 'zh', '...'] #는 기본 언어 목록을 사용합니다.default_language = 'zh' if 'zh'가 supported_언어에 있으면 supported_언어[0] # 목록에 'zh'가 있으면 이를 기본값으로 사용하고, 그렇지 않으면 목록의 첫 번째 값을 사용합니다.
# GUI 인터페이스 만들기model_label = widgets.Label('모델 선택:')모델_드롭다운 = widgets.드롭다운(옵션=모델_리스트, 값=모델_크기)language_label = widgets.Label('언어:')언어_드롭다운 = widgets.Dropdown(옵션=지원되는_언어, 값=기본_언어)beam_size_label = widgets.Label('빔 크기:')beam_size_slider = widgets.IntSlider(value=5, min=1, max=10, step=1)compute_type_label = widgets.Label('계산 유형:')만약 장치 == "쿠다".compute_type_options = ['float16', 'int8']else.compute_type_options = ['float32'] # CPU인 경우, float32로 잠급니다.계산 유형 드롭다운 = widgets.드롭다운(옵션=계산 유형_옵션, 값=계산 유형)mode_label = widgets.Label('포맷 모드:')mode_dropdown = widgets.Dropdown(options=['normal', 'timeline', 'subtitle'], value='normal')initial_prompt_label = widgets.Label('초기 프롬프트:') # 새 초기 프롬프트 라벨 추가됨initial_prompt_text = widgets.Text(value='') # 초기 프롬프트 입력 상자가 추가되었습니다.file_name_text = widgets.Text(description='파일 이름:', value='/content/') # 사용자가 파일 이름 입력 허용트랜스크립트_버튼 = widgets.Button(description='트랜스크립트')output_area = widgets.Output()
# 번역 기능 정의하기def transcribe_audio(b).출력_영역.clear_output()인쇄("전사 시작...")faster_whisper에서 WhisperModel # 가져오기 WhisperModel의 동적 가져오기: RAM을 절약하기 위해 필요할 때 가져오기시도해 보세요.file_name = file_name_text.value # 사용자가 입력한 파일 이름 사용initial_prompt = initial_prompt_text.value # 사용자 입력을 사용한 초기 프롬프트# 문서가 있는지 확인if not os.path.exists(file_name):: if not os.path.exists(file_name).print(f "{파일_이름} 파일이 존재하지 않습니다. 파일 이름과 경로가 올바른지 확인하세요.")반환# 일부 모델 인수선택된 모델 = 모델_드롭다운.값선택된_계산 유형 = 계산 유형_드롭다운.값선택된 언어 = 언어_드롭다운.값# 새 모델 인스턴스를 생성하고 번역을 수행합니다.model = WhisperModel(selected_model, device=장치, compute_type=선택된_컴펙트_type)시도해 보세요.# 번역된 오디오세그먼트, 정보 = model.transcribe(파일_이름, 빔크기=빔크기_슬라이더.값, 언어=선택된 언어, 초기 프롬프트=초기 프롬프트) ) #에 초기 프롬프트 매개변수 추가# 인쇄 결과print("%f 확률로 언어 '%s'를 감지했습니다." % (info.language, info.language_probability))세그먼트의 세그먼트에 대해if mode_dropdown.value == 'normal'.print("%s " % (segment.text))엘리프 모드_드롭다운.값 == '타임라인'.print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))else: # 자막start_time = "{:02d}:{:02d}:{:02d},{:03d}".format(int(segment.start // 3600), int((segment.start % 3600) // 60), int(segment.start % 60), int((segment.start % 1) * 1000))end_time = "{:02d}:{:02d}:{:02d},{:03d}".format(int(segment.end // 3600), int((segment.end % 3600) // 60), int(segment.end % 60), int((segment. segment.end % 1) * 1000)))print("%d\n%s --> %s\n%s\n" % (segment.id, start_time, end_time, segment.text))마침내.# 모델 인스턴스를 삭제하여 RAM을 확보합니다.델 모델예외는 e로 제외합니다.print("전사 중 오류가 발생했습니다:")print(str(e))마침내.# 가비지 컬렉션 호출하기gc.collect()print("전사 완료.")
# 어셈블리 GUI 인터페이스디스플레이(모델_라벨, 모델_드롭다운, 언어_라벨, 언어_드롭다운, 빔사이즈_라벨, 빔사이즈_슬라이더, 컴퓨트_유형_라벨, 컴퓨트_. type_dropdown, mode_label, mode_dropdown, initial_prompt_label, initial_prompt_text, file_name_text, transcribe_button, output_area)트랜스크라이브_버튼.on_click(트랜스크라이브_오디오)
다중 화자 코드 인식 예시
pyannote.core에서 세그먼트 가져오기
def get_text_with_timestamp(transcribe_res).
timestamp_texts = []에 대한 항목의 트랜스크라이브_res.
start = item.start
end = item.end
text = item.text.strip()
timestamp_texts.append((Segment(start, end), text))
타임스탬프_텍스트 반환def add_speaker_info_to_text(timestamp_texts, ann).
spk_text = []에 대한 세그, 타임스탬프_텍스트의 텍스트:
spk = ann.crop(seg).argmax()
spk_text.append((seg, spk, text))
반환 spk_textdef merge_cache(text_cache).
sentence = ''.join([text_cache의 항목에 대해 항목[-1]])
spk = text_cache[0][1]start = round(text_cache[0][0].start, 1)
end = round(text_cache[-1][0].end, 1)
반환 세그먼트(시작, 끝), spk, 문장punc_sent_end = [',', '.' , '? , '!' , ",", "." , "?" , "!"]
def merge_sentence(spk_text).
merged_spk_text = []pre_spk = 없음
text_cache = []에 대해 세그, spk, 텍스트는 spk_text:
if spk! = pre_spk이고 pre_spk가 None이 아니며 len(text_cache) > 0:.
merged_spk_text.append(merge_cache(text_cache))
text_cache = [(seg, spk, text)]pre_spk = spk텍스트와 len(text) > 0 및 text[-1]이 PUNC_SENT_END에 있는 경우:
text_cache.append((seg, spk, text))
merged_spk_text.append(merge_cache(text_cache))
text_cache = []pre_spk = spk
else.
text_cache.append((seg, spk, text))
PRE_SPK = SPK
len(text_cache) > 0.
merged_spk_text.append(merge_cache(text_cache))
반환된_spk_textdef diarize_text(transcribe_res, diarisation_결과).
timestamp_texts = get_text_with_timestamp(transcribe_res)
spk_text = add_speaker_info_to_text(timestamp_texts, diarisation_결과)
res_processed = merge_sentence(spk_text)
반환 res_processeddef write_to_txt(spk_sent, file).
열다(파일, 'w')를 fp로 사용합니다.
세그, SPK, SPK_SENT의 문장에 대해.
line = f'{seg.start:.2f} {seg.end:.2f} {spk} {sentence}\n'
fp.write(line)
토치 가져오기
가져오기 속삭임
NUMPY를 NP로 가져옵니다.
pydub에서 오디오 세그먼트 가져오기
로구루에서 로거 가져오기
faster_whisper에서 WhisperModel을 가져옵니다.
pyannote.audio에서 파이프라인 가져오기
pyannote.audio에서 오디오 가져오기에서 common.error.import ErrorCode
model_path = config["asr"]["faster-whisper-large-v3"]
# 테스트 오디오: https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_speaker_demo.wav
audio = ". /test/asr/data/asr_speaker_demo.wav"
asr_model = WhisperModel(model_path, device="cuda", compute_type="float16")
spk_rec_pipeline = Pipeline.from_pretrained("pyannote/스피커-diarisation-3.1", use_auth_token="당신의 포옹 얼굴 토큰")
spk_rec_pipeline.to(torch.device("cuda"))asr_result, info = asr_model.transcribe(audio, language="zh", beam_size=5)
일기_결과 = spk_rec_pipeline(audio)final_result = diarize_text(asr_result, diarisation_result)
세그먼트, SPK의 경우 final_result로 전송됩니다:
print("[%.2fs -> %.2fs] %s %s" % (segment.start, segment.end, sent, spk))
관련 리소스
주요 프로젝트: https://github.com/SYSTRAN/faster-whisper
단축 코드: https://www.letswrite.tw/colab-faster-whisper/
자막으로 변환하는 튜브 동영상: https://github.com/lewangdev/faster-whisper-youtube
빠른 속삭임 실시간 음성 녹음: https://www.kaggle.com/code/xiu0714/faster-whisper
원클릭 설치 패키지
https://pan.quark.cn/s/1b74d4cec6d6
암호 해독 코드 1434
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...