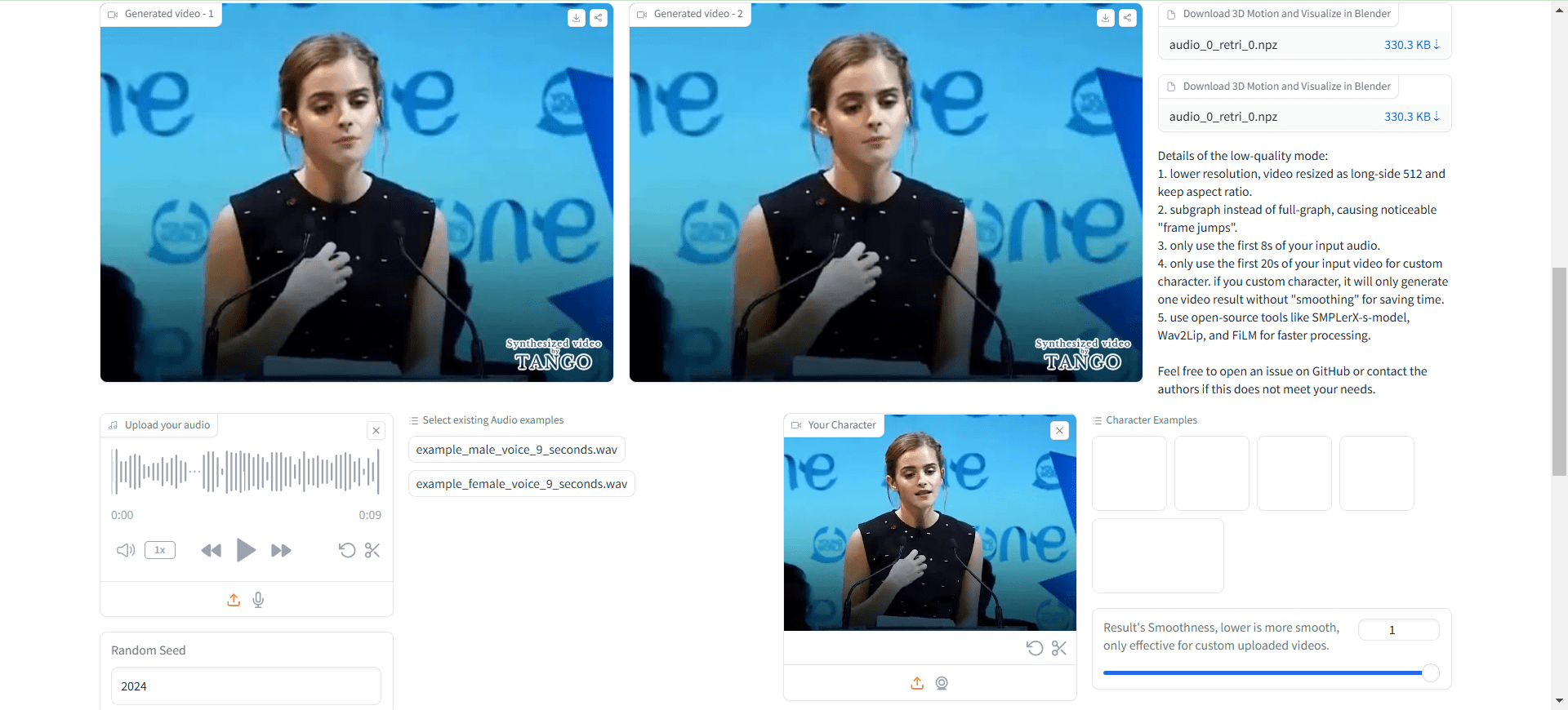

일반 소개
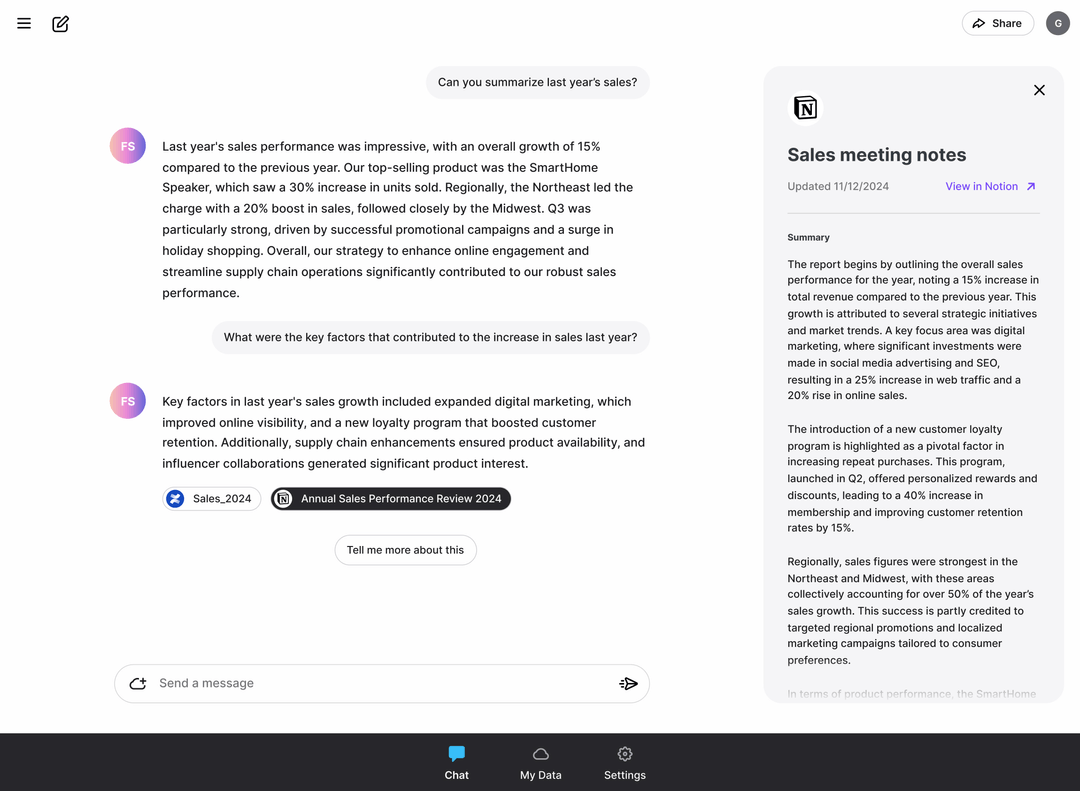
IMS Toucan은 독일 슈투트가르트 대학교의 자연어 처리 연구소(IMS)에서 개발한 최첨단 텍스트 음성 변환(TTS) 툴킷입니다. 7000개 이상의 언어를 지원하는 이 툴킷은 빠르고 제어 가능하며 컴퓨팅 리소스 요구 사항이 낮으며, 연구, 교육 및 실제 애플리케이션을 위한 효율적인 음성 합성 솔루션을 제공하도록 설계되었습니다. 툴킷을 통해 사용자는 최첨단 음성 합성 기술을 훈련하고, 사용하고, 가르칠 수 있으며, IMS Toucan은 다양한 기능 모듈과 유연한 제어 인터페이스를 제공하여 사용자가 필요에 따라 고품질 음성 출력을 생성할 수 있도록 지원합니다.
文本转语音工具-1")
데모: https://huggingface.co/spaces/Flux9665/MassivelyMultilingualTTS
기능 목록
- 다국어 지원7000개 이상의 언어로 텍스트 음성 합성을 지원합니다.
- 빠른 합성실시간 애플리케이션을 위한 효율적인 음성 생성 속도.
- 제어 가능사용자가 음성의 높낮이, 리듬, 음색을 정밀하게 제어할 수 있습니다.
- 낮은 컴퓨팅 성능실행에 많은 컴퓨팅 리소스가 필요하지 않으며 다양한 하드웨어 환경에 적합합니다.
- 대화형 프레젠테이션음성 합성 기능을 직접 체험할 수 있도록 온라인 데모를 제공합니다.
- 오픈 소스간편한 2차 개발 및 사용자 지정을 위한 완벽한 오픈 소스 코드 기반입니다.
- 사전 교육 모델사용자가 직접 사용하거나 추가로 미세 조정할 수 있는 사전 학습된 음성 합성 모델을 제공합니다.
도움말 사용
설치 프로세스
- 기본 요구 사항파이썬 버전 3.10을 권장합니다. 다음 종속성을 설치해야 합니다: libsndfile1, espeak-ng, ffmpeg, libasound-dev, libportaudio2, libsqlite3-dev.
- 클론 창고IMS Toucan 리포지토리를 로컬 머신에 복제합니다(모델 학습에는 CUDA 지원 GPU가 권장되며, 추론에는 GPU가 필요하지 않습니다).
git clone https://github.com/DigitalPhonetics/IMS-Toucan.git
cd IMS-Toucan
- 가상 환경 만들기: 가상 환경을 만들고 활성화하여 기본 종속성을 설치합니다.
python -m venv <path_to_env>
source <path_to_env>/bin/activate
pip install --no-cache-dir -r requirements.txt
- 데모 스크립트 실행설치가 완료되면 데모 목적으로 다음 스크립트를 실행할 수 있습니다.
python run_advanced_GUI_demo.py
기능 작동 흐름
- 텍스트 음성 변환대화형 인터페이스에 텍스트를 입력하고 언어 및 음성 매개변수를 선택한 다음 생성 버튼을 클릭하여 음성을 생성합니다.
- 음성 제어음높이 및 지속 시간 슬라이더를 드래그하여 생성된 음성의 음높이와 리듬을 정밀하게 조정할 수 있습니다.
- 음성 대체음성 매개 변수를 동일하게 유지하면서 다른 음성 모델로 변경할 수 있습니다.
- 모델 교육사용자는 자체 데이터 세트를 사용하여 새로운 음성 모델을 학습할 수 있으며, 학습 스크립트는 리포지토리에 있는 학습 스크립트와 설명서를 참조하세요.
주요 기능
- 다국어 지원7,000개 이상의 언어를 지원하는 IMS Toucan은 사용자가 필요에 따라 음성 합성을 위해 다양한 언어를 선택할 수 있습니다.
- 효율적인 합성IMS Toucan은 컴퓨팅 리소스가 부족한 환경에서도 고품질 음성을 빠르게 생성할 수 있습니다.
- 유연한 제어사용자는 대화형 인터페이스를 통해 음성의 파라미터를 정밀하게 제어하여 요구 사항을 충족하는 음성 출력을 생성할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...