HtmlRAG: 효율적인 HTML 검색 강화 생성 시스템 구축, RAG 시스템에서 HTML 문서 검색 및 처리 최적화

일반 소개
HtmlRAG는 향상된 세대 검색 개선에 초점을 맞춘 혁신적인 오픈 소스 프로젝트입니다(RAG) 시스템에서 HTML 문서 처리에 대한 접근 방식을 제시합니다. 이 프로젝트는 RAG 시스템에서 HTML 형식을 사용하는 것이 일반 텍스트보다 더 효율적이라는 새로운 접근 방식을 제시합니다. 이 프로젝트는 쿼리 재작성부터 HTML 문서 크롤링, 답변 생성을 위한 평가 시스템에 이르기까지 전체 데이터 처리 흐름을 포괄합니다. ASQA, HotpotQA, NQ 등 여러 주요 데이터 세트의 처리를 지원하며 시스템 성능을 측정하기 위한 상세한 평가 메트릭을 제공합니다. 이 프로젝트는 소스 코드 구현뿐만 아니라 사전 처리된 데이터 세트와 평가 도구도 포함되어 있어 연구자가 결과를 쉽게 재현하고 추가 개선을 할 수 있습니다.
논문 주소: https://arxiv.org/pdf/2411.02959

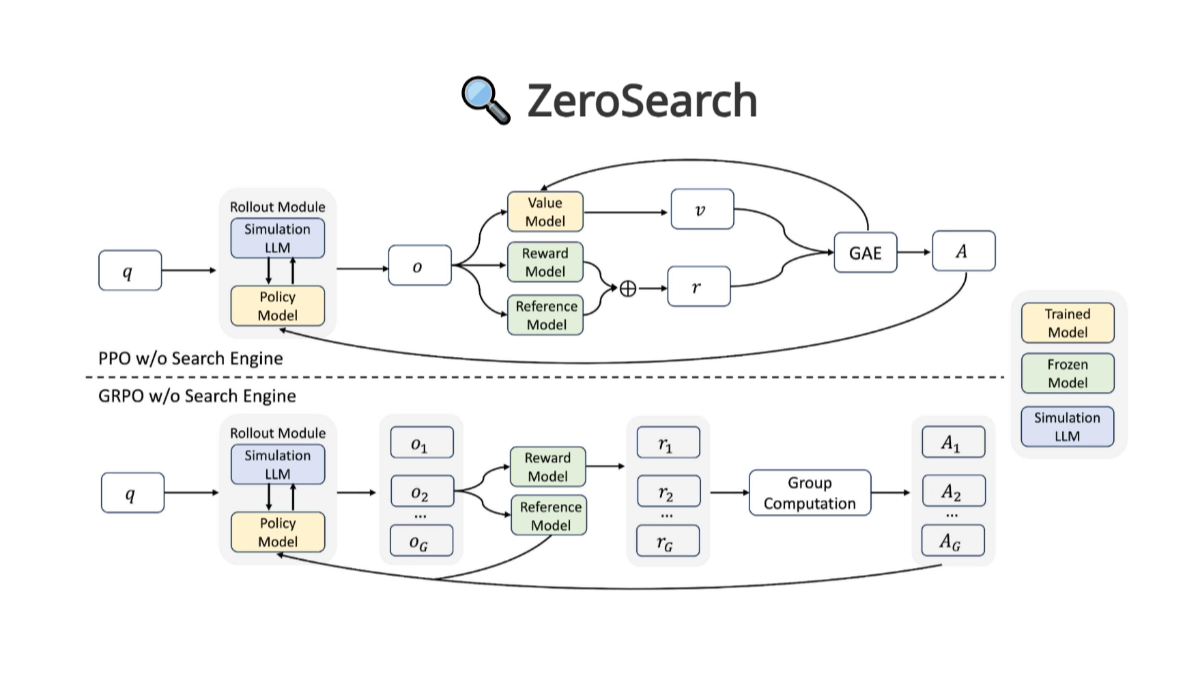
RAG 시스템에서 외부 지식의 포맷으로 일반 텍스트가 아닌 HTML을 사용하는 HtmlRAG 를 제안합니다. HTML이 가져오는 긴 컨텍스트에 대처하기 위해 무손실 HTML 정리와 2단계 블록 트리 기반 HTML 가지치기가 제안됩니다.
비파괴 HTML 정리이 정리 프로세스는 완전히 관련이 없는 콘텐츠만 제거하고 중복 구조를 압축하여 원본 HTML의 모든 의미 정보를 보존합니다. 무손실 HTML 정리 압축 HTML은 컨텍스트 LLM이 길고 생성 전에 정보를 손실하지 않으려는 RAG 시스템에 적합합니다. 2단계 블록 트리 기반 HTML 가지치기: 블록 트리 기반 HTML 가지치기는 두 단계로 구성되며, 두 단계 모두 블록 트리 구조에서 수행됩니다.첫 번째 가지치기 단계에서는 임베딩 모델을 사용하여 블록의 점수를 계산합니다.그러나 (아닌)두 번째 단계에서는 경로를 사용하여 모델을 생성합니다.. 첫 번째 단계는 무손실 HTML 정리 결과를 다루고, 두 번째 단계는 첫 번째 가지치기 단계의 결과를 다룹니다.

블록 점수 계산. 블록 트리는 스플리터에 의해 토큰 트리로 변환되며, 해당 HTML 태그와 토큰은 같은 색상으로 표시됩니다. 토큰 생성 확률은 오른쪽 상단에 표시되며, 점선 상자 안의 토큰은 추론이 필요하지 않습니다. 블록 트리의 오른쪽 상단 모서리에는 블록 확률이 표시되며, 해당 토큰 확률에서 확률을 도출할 수 있습니다.
명령 예시:
**HTML**: “{HTML}”
**问题**: **{Question}**
您的任务是从 HTML 文档中识别与给定问题最相关的文本片段。该文本片段可以是对事实的直接释义,或可用作推断该事实的支持性证据。
文本片段的整体长度应超过 20 个单词且少于 300 个单词。您需要提供该文本片段在 HTML 文档中的路径。
输出示例为:
<html1><body><div2><p>一些关键信息...
输出:
<html1><body><div2><p>在历史性的 2018 年皇家大战中,Shinsuke Nakamura 赢得了男子皇家大战. . .


HTML을 일반 텍스트로 변환할 때 정보 손실
기능 목록
- 복잡한 문제를 하위 쿼리로 분해하는 쿼리 처리 및 재작성 기능을 지원하는 쿼리 처리 및 재작성 기능
- HTML 문서 크롤링 및 처리 시스템, 문서 구조 정보 보유
- 다중 데이터 세트 지원(ASQA, HotpotQA, NQ, TriviaQA, MuSiQue, ELI5)
- 정답 정확도, 관련성 등 여러 차원을 포함하는 완벽한 평가 프레임워크입니다.
- 사용자 지정 데이터 세트 처리 지원으로 사용자가 자신의 데이터로 작업할 수 있습니다.
- 관련 웹페이지 검색을 위한 통합 Bing 검색 기능
- ROUGE 점수와 같은 다양한 평가 지표를 포함한 세부 채점 시스템을 제공합니다.
- LangChain 프레임워크와의 통합 지원
- 결과 시각화 및 분석 도구
도움말 사용
1. 환경 설정
먼저 프로젝트 리포지토리를 복제하고 필요한 종속 요소를 설치해야 합니다:
git clone https://github.com/plageon/HtmlRAG
cd HtmlRAG
pip install -r requirements.txt
2. 데이터 세트 준비
이 프로젝트는 두 가지 데이터 사용 방법을 지원합니다:
- 사전 처리된 데이터 집합을 사용합니다:
- 데이터 세트는 html_data 폴더에 저장됩니다.
- 전체 테스트 데이터 세트는 허깅페이스에서 다운로드할 수 있습니다: HtmlRAG-test
- 지원되는 데이터 세트 형식에는 ASQA, HotpotQA, NQ 등이 있습니다.
- 사용자 지정 데이터를 사용합니다:
- 각 줄에 다음 필드가 포함된 .jsonl 형식의 쿼리 파일을 준비합니다:
{ "id": "unique_id", "question": "query_text", "answers": ["answer_text_1", "answer_text_2"] }
- 각 줄에 다음 필드가 포함된 .jsonl 형식의 쿼리 파일을 준비합니다:
3. 주요 기능의 흐름
쿼리 처리
- 쿼리 재작성:
- 시스템이 복잡한 질문을 여러 개의 하위 질문으로 자동 분류합니다.
- 재작성 결과는 json 객체의 재작성_방법_결과 필드에 저장됩니다.
HTML 문서 처리
- 페이지 크롤링:
- 시스템은 Bing을 사용하여 관련 URL을 검색합니다.
- 정적 HTML 문서의 자동 크롤링
- 문서의 HTML 구조에 대한 정보 유지
평가 시스템
- 지표 구성을 평가합니다:
- 정답의 정확성 평가
- 답안 관련성 평가
- 루즈 점수 계산
- 사용자 지정 평가 지표 설정
- 평가 도구 사용:
from ragas.metrics import AnswerRelevancy
from langchain.embeddings import HuggingFaceEmbeddings
# 初始化评估器
embeddings = HuggingFaceEmbeddings('BAAI/bge-base-en')
answer_relevancy = AnswerRelevancy(embeddings=embeddings)
# 加载模型
answer_relevancy.init_model()
# 运行评估
results = answer_relevancy.score(dataset)
4. 결과 분석 및 최적화
- 제공된 시각화 도구를 사용하여 평가 결과를 분석하세요.
- 평가 지표에 따른 시스템 매개변수 조정
- 쿼리 재작성 전략 및 문서 처리 방법 최적화하기
5. 주의 사항
- HTML 데이터를 처리할 수 있는 충분한 저장 공간 확보
- API 사용 한도 및 요금 한도 준수
- 최신 기능에 대한 종속성 패키지를 정기적으로 업데이트하세요.
- 데이터 형식의 정확성에 주의하세요.
- 대규모 데이터 처리를 가속화하려면 GPU를 사용하는 것이 좋습니다.
HTML 문서 정리에 대한 참고 사항
HTML 정리 규칙(패턴 정리)
def clean_html(html: str) -> str: # 1. 使用BeautifulSoup解析HTML soup = bs4.BeautifulSoup(html, 'html.parser') # 2. 调用simplify_html进行简化处理 html = simplify_html(soup) # 3. 调用clean_xml清理XML标记 html = clean_xml(html) return html

1. HTML 문서 처리 관련 단어(다음 내용은 프로젝트 코드가 아님)
# HTML清洗提示词
CLEAN_HTML_PROMPT = """
任务:清洗HTML文档,保留有效信息
输入:原始HTML文档
要求:
1. 移除:
- JavaScript代码 (<script>标签)
- CSS样式信息 (<style>标签)
- HTML注释
- 空白标签
- 多余属性
2. 保留:
- 主要内容标签(<title>, <p>, <div>, <h1>-<h6>等)
- 文本内容
- 结构关系
输出:清洗后的HTML文本
"""
# HTML分块提示词
HTML_BLOCK_PROMPT = """
任务:将HTML文档分割成语义完整的块
输入:
- 清洗后的HTML文档
- 最大块大小:{max_words}词
要求:
1. 保持HTML标签的层级结构
2. 确保每个块的语义完整性
3. 记录块的层级路径
4. 控制每个块的大小不超过限制
输出:JSON格式的块列表,包含:
{
"blocks": [
{
"content": "块内容",
"path": "HTML路径",
"depth": "层级深度"
}
]
}
"""
2. 블록 트리 구성과 관련된 단서 단어
# 块树节点评分提示词
BLOCK_SCORING_PROMPT = """
任务:评估HTML块与问题的相关性
输入:
- 问题:{question}
- HTML块:{block_content}
- 块路径:{block_path}
要求:
1. 计算语义相关性分数(0-1)
2. 考虑以下因素:
- 文本相似度
- 结构重要性
- 上下文关联
输出:
{
"score": float, # 相关性分数
"reason": "评分理由"
}
"""
# 块树剪枝提示词
TREE_PRUNING_PROMPT = """
任务:决定是否保留HTML块
输入:
- 问题:{question}
- 当前块:{current_block}
- 父级块:{parent_block}
- 子块列表:{child_blocks}
要求:
1. 分析块的重要性:
- 与问题的相关性
- 在文档结构中的作用
- 与父子块的关系
2. 生成保留/删除决策
输出:
{
"action": "keep/remove",
"confidence": float, # 决策置信度
"reason": "决策理由"
}
"""
3. 지식 검색 관련 용어
# 相关性计算提示词
RELEVANCE_PROMPT = """
任务:计算文档片段与问题的相关性
输入:
- 问题:{question}
- 文档片段:{text_chunk}
评估标准:
1. 直接相关性:内容直接回答问题的程度
2. 间接相关性:提供背景或补充信息的程度
3. 信息完整性:回答是否完整
输出:
{
"relevance_score": float, # 相关性分数0-1
"reason": "评分理由",
"key_matches": ["关键匹配点1", "关键匹配点2", ...]
}
"""
# 答案生成提示词
ANSWER_GENERATION_PROMPT = """
任务:根据相关文档生成答案
输入:
- 用户问题:{question}
- 相关文档:{relevant_docs}
- 文档评分:{doc_scores}
要求:
1. 综合高相关性文档信息
2. 保持答案的准确性
3. 确保回答完整且连贯
4. 必要时标注信息来源
输出格式:
{
"answer": "生成的答案",
"sources": ["使用的文档来源"],
"confidence": float # 答案置信度
}
"""
4. 관련 프롬프트 평가
# 答案评估提示词
EVALUATION_PROMPT = """
任务:评估生成答案的质量
输入:
- 原始问题:{question}
- 生成答案:{generated_answer}
- 参考答案:{reference_answer}
评估维度:
1. 正确性:信息是否准确
2. 完整性:是否完整回答问题
3. 相关性:内容与问题的相关程度
4. 连贯性:表述是否清晰连贯
输出:
{
"scores": {
"correctness": float,
"completeness": float,
"relevance": float,
"coherence": float
},
"feedback": "详细评估意见"
}
"""
# 错误分析提示词
ERROR_ANALYSIS_PROMPT = """
任务:分析答案中的潜在错误
输入:
- 生成答案:{answer}
- 参考资料:{reference_docs}
分析要点:
1. 事实准确性检查
2. 逻辑推理验证
3. 信息来源核实
输出:
{
"errors": [
{
"type": "错误类型",
"description": "错误描述",
"correction": "建议修正"
}
],
"reliability_score": float # 可信度评分
}
"""© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서

댓글 없음...