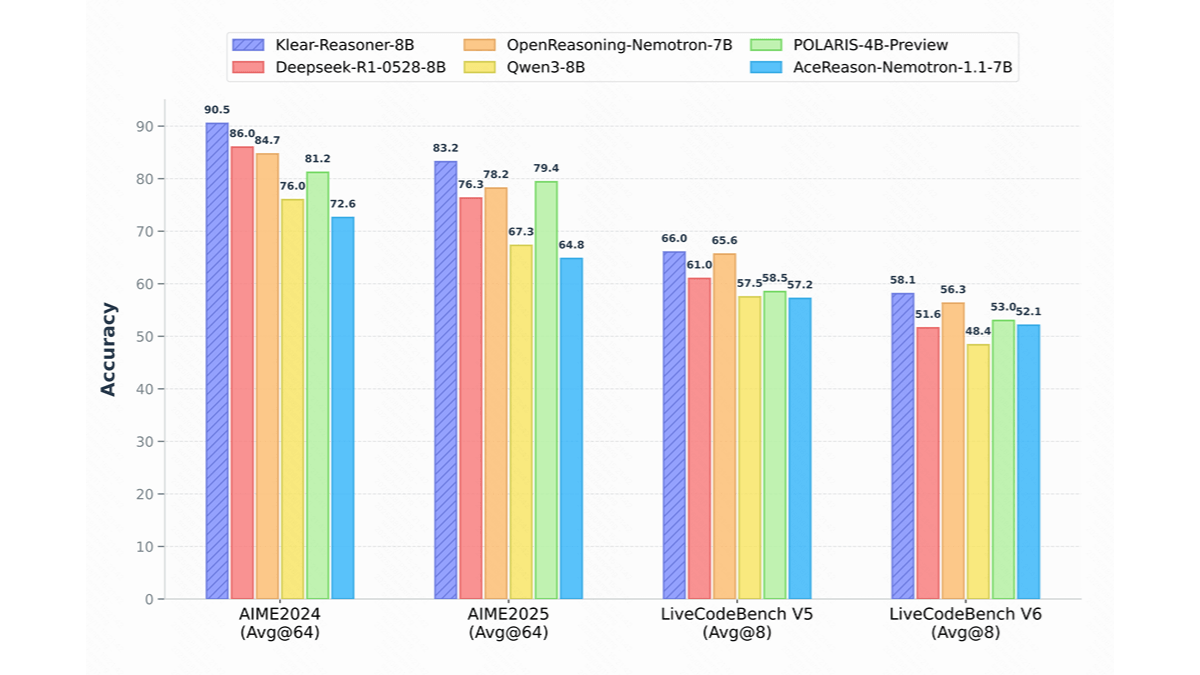

Fun-AudioGen-VD是什么
Fun-AudioGen-VD 是阿里通义实验室推出的创新语音大模型,专注于声音设计与场景化音频生成。模型支持通过自然语言指令直接生成包含特定音色、情绪表达和完整听觉场景的高质量音频,无需参考音频即可实现"人物+场景"的一体化声音创作。具备精细化音色控制(性别、年龄、口音、音高、语速)、复杂心理状态模拟(如"表面镇定但内心颤抖"的细腻情感)、沉浸式场景构建(叠加城市喧嚣、战场轰鸣等环境音与空间混响)、设备听感滤镜(老式广播、对讲机等特殊音质)以及动态环境互动(风噪断续、回声变化)等能力,内置客服、老兵、孩童等典型角色预设,为影视制作、游戏开发、有声内容创作等领域提供专业级声音设计解决方案。

Fun-AudioGen-VD的功能特色
- 精细化音色控制:支持调控性别、年龄、口音、音高、语速等基础属性,提供沙哑、清亮、磁性等音质特征选项,以及愤怒、悲伤、坚定等情绪表达。
- 复杂心理状态模拟:能呈现"表面镇定但内心颤抖"等细腻情感层次,实现角色内心活动的声音化表达。
- 沉浸式场景构建:可叠加城市喧嚣、咖啡馆背景、战场轰鸣等环境音,模拟大教堂、水下等空间混响,增强场景空间感。
- 设备听感滤镜:还原老式广播、对讲机、呼吸面罩等设备的特殊音质特征,丰富声音表现力。
- 动态环境互动:实现风噪断续、回声变化、嘶哑效果等实时环境互动,提升音频真实感。
- 角色预设模拟:内置客服、老兵、孩童、AI助手、播音员等典型角色音色模板,快速匹配创作需求。
Fun-AudioGen-VD的核心优势
- 零样本声音设计:无需参考音频,仅凭自然语言描述即可从无到有生成全新声音,大幅降低声音创作门槛。
- 人物场景一体化:突破传统语音生成仅输出干声的局限,实现角色音色与环境音效、空间混响的同步生成。
- 情感层次细腻:支持复杂心理状态建模,可呈现表面与内心情绪反差等高级表达,超越单一情绪标签。
- 专业级音质输出:生成音频具备影视级品质,可直接用于游戏、动画、有声书等专业内容制作。
- 角色库快速调用:内置多类典型角色预设,创作者可快速匹配需求,提升内容生产效率。
- API灵活接入:通过阿里云百炼平台提供API服务,支持开发者集成至自有应用与工作流。
Fun-AudioGen-VD官网是什么
알리바바의 100개 대장간通过API调用
Fun-AudioGen-VD的适用人群
- 声音设计师与音频工程师:需要快速生成原型声音或补充素材,提升影视、游戏项目的音频制作效率。
- 인디 게임 개발자:缺乏专业配音预算的小团队,可通过文本描述低成本创建游戏角色语音与环境音效。
- 오디오 콘텐츠 제작자:播客主播、有声书制作人、广播剧导演,需要为作品定制角色音色与场景氛围。
- 短视频与新媒体制作人:需快速生成带情绪与场景感的配音内容,提升视频质感与完播率。
- 광고 카피라이터:为品牌Campaign设计独特声音形象,制作差异化音频广告素材。
- AI应用开发者:通过API集成声音生成能力,为教育、客服、娱乐等应用添加语音交互功能。
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...