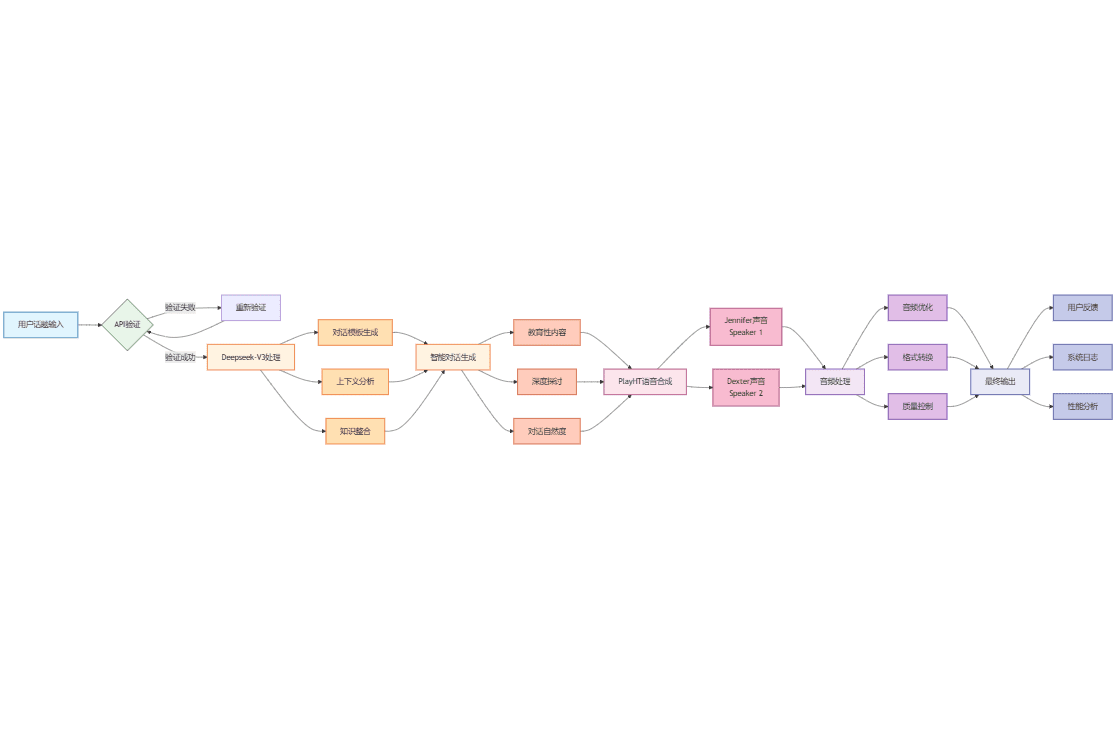

일반 소개
판타지토킹은 판타지-AMAP 팀이 개발한 오픈 소스 프로젝트로, 사실적인 느낌의 말하는 인물 동영상을 오디오 기반으로 생성하는 데 중점을 두고 있습니다. 이 프로젝트는 고급 비디오 확산 모델 Wan2.1을 기반으로 오디오 인코더 Wav2Vec 및 독점 모델 가중치와 결합하여 인공지능 기술을 사용하여 매우 사실적인 립싱크와 얼굴 표정을 구현합니다. 파노라마, 바스트 또는 클로즈업과 같은 다양한 시점을 위해 실제 인물과 만화 이미지를 포함한 다양한 스타일의 인물 생성을 지원합니다. 사용자는 간단한 명령줄 조작을 통해 이미지와 오디오를 입력하여 고품질의 토킹 비디오를 빠르게 생성할 수 있습니다.

기능 목록
- 오디오와 고도로 동기화된 입술 움직임으로 실감나는 인물 동영상을 제작하세요.
- 클로즈업, 반신, 전신 초상화 등 다양한 시점으로 사진을 생성할 수 있습니다.
- 실제 인물 사진 및 만화 스타일의 인물 사진과 호환되어 다양한 요구 사항을 충족합니다.
- 캐릭터의 표정과 몸동작을 조절할 수 있는 큐 워드 제어 기능을 제공합니다.
- 최대 720P의 고해상도 출력을 지원합니다.
- 얼굴에 초점을 맞춘 교차 주의 모듈을 통합하여 얼굴 특징의 일관성을 보장합니다.
- 표현과 동작 범위를 제어하는 운동 강도 조절 모듈이 포함되어 있습니다.
- 2차 커뮤니티 개발 및 최적화를 지원하는 오픈 소스 모델과 코드.
도움말 사용
설치 프로세스
판타지토킹을 사용하려면 먼저 필요한 종속성 및 모델을 설치해야 합니다. 다음은 자세한 설치 단계입니다:
- 프로젝트 코드 복제
터미널에서 다음 명령을 실행하여 프로젝트를 로컬로 복제합니다:git clone https://github.com/Fantasy-AMAP/fantasy-talking.git cd fantasy-talking
- 종속성 설치
이 프로젝트는 Python 환경과 PyTorch(버전 >= 2.0.0)에 따라 달라집니다. 다음 명령을 실행하여 필요한 라이브러리를 설치합니다:pip install -r requirements.txt옵션 장착
flash_attn를 사용하여 주의력 계산을 가속화합니다:pip install flash_attn - 모델 다운로드
판타지토킹에는 Wan2.1-I2V-14B-720P(기본 모델), Wav2Vec(오디오 인코더), 판타지토킹 모델 웨이트의 세 가지 모델이 필요합니다. 이 모델들은 Hugging Face 또는 ModelScope를 통해 다운로드할 수 있습니다:- 허깅 페이스 CLI를 사용합니다:
pip install "huggingface_hub[cli]" huggingface-cli download Wan-AI/Wan2.1-I2V-14B-720P --local-dir ./models/Wan2.1-I2V-14B-720P huggingface-cli download facebook/wav2vec2-base-960h --local-dir ./models/wav2vec2-base-960h huggingface-cli download acvlab/FantasyTalking fantasytalking_model.ckpt --local-dir ./models - 또는 ModelScope CLI를 사용합니다:
pip install modelscope modelscope download Wan-AI/Wan2.1-I2V-14B-720P --local_dir ./models/Wan2.1-I2V-14B-720P modelscope download AI-ModelScope/wav2vec2-base-960h --local_dir ./models/wav2vec2-base-960h modelscope download amap_cvlab/FantasyTalking fantasytalking_model.ckpt --local_dir ./models
- 허깅 페이스 CLI를 사용합니다:
- 인증 환경
GPU를 사용할 수 있는지 확인하세요(RTX 3090 이상 권장, VRAM 24GB 이상). 메모리 문제가 발생하면 해상도를 낮추거나 VRAM 최적화를 활성화하세요.
사용법
설치가 완료되면 사용자는 추론 스크립트를 실행하여 명령줄에서 동영상을 생성할 수 있습니다. 기본 명령은 다음과 같습니다:
python infer.py --image_path ./assets/images/woman.png --audio_path ./assets/audios/woman.wav
--image_path: 세로 이미지의 경로를 입력합니다(PNG/JPG 형식 지원).--audio_path: 오디오 파일 경로 입력(WAV 형식 지원).--prompt: 예를 들어 역할 동작을 제어하기 위한 선택적 프롬프트 단어입니다:--prompt "The person is speaking enthusiastically, with their hands continuously waving."--audio_cfg_scale노래로 응답--prompt_cfg_scale오디오 및 큐워드의 영향력 수준을 제어하며, 권장 범위는 3~7입니다. 오디오 CFG를 높이면 립싱크가 향상됩니다.
주요 기능 작동
- 립싱크 동기화
판타지토킹의 핵심 기능은 오디오를 기반으로 정확한 입술 움직임을 생성하는 것입니다. 사용자는 선명한 오디오 파일을 준비해야 합니다(예: WAV 형식, 샘플링 속도 16kHz가 최적). 추론 스크립트가 실행되면 모델이 자동으로 오디오를 분석하여 일치하는 입술 움직임을 생성합니다. 최상의 결과를 얻으려면 오디오에 심각한 노이즈가 없는지 확인하세요. - 큐 단어 제어
통과(청구서 또는 검사 등)--prompt매개변수를 사용하여 캐릭터의 표정과 동작을 정의할 수 있습니다. 예를 들어, 다음과 같이 입력합니다.--prompt "The person is speaking calmly with slight head movements."차분하게 말하는 동영상을 생성할 수 있습니다. 단서는 모호한 설명을 피하고 간결하고 명확해야 합니다. - 다양한 스타일 지원
이 프로젝트는 실제와 만화 스타일의 초상화 생성을 모두 지원합니다. 사용자는 다양한 스타일의 입력 이미지를 제공할 수 있으며, 모델은 이미지의 특징에 따라 출력 스타일을 조정합니다. 카툰 스타일은 애니메이션 장면에 적합하고 실제 스타일은 가상 앵커와 같은 애플리케이션에 적합합니다. - 운동 강도 조절
판타지토킹의 모션 강도 변조 모듈을 사용하면 표정과 움직임의 진폭을 조절할 수 있습니다. 예를 들어, 더 높은--audio_weight이 매개변수는 팔다리 움직임을 향상시키며 역동적인 장면에 적합합니다. 기본 설정은 최적화되어 있으므로 처음 사용할 때는 기본값을 유지하는 것이 좋습니다.
주의
- 하드웨어 요구 사항32GB VRAM이 장착된 RTX 5090은 여전히 메모리 부족 문제가 발생할 수 있으며, 고해상도 동영상을 생성하는 데 필요한 메모리 양을 줄이는 것이 좋습니다.
--image_size어쩌면--max_num_frames. - 모델 다운로드모델 파일은 대용량(약 수십 기가바이트)이므로 안정적인 네트워크와 충분한 디스크 공간이 있는지 확인하세요.
- 큐 단어 최적화: 큐 단어는 출력에 큰 영향을 미치므로 최적의 설명을 찾기 위해 여러 가지 실험을 해보는 것이 좋습니다.
애플리케이션 시나리오
- 가상 앵커 콘텐츠 제작
사용자는 판타지토킹을 사용하여 가상 앵커를 위한 사실적인 토크 동영상을 생성할 수 있습니다. 앵커의 인물 이미지와 음성 해설 오디오를 입력하여 라이브 스트리밍, 짧은 동영상 또는 교육용 콘텐츠 제작을 위한 립싱크 비디오를 생성할 수 있습니다. - 애니메이션 캐릭터 더빙
애니메이터는 만화 캐릭터의 보이스오버 동영상을 생성할 수 있습니다. 만화 이미지와 오디오를 제공하면 모델이 그에 맞는 입술 움직임과 표정을 생성하여 애니메이션 제작 과정을 간소화할 수 있습니다. - 교육용 비디오 제작
교사 또는 교육 기관은 가상 강사 비디오를 생성할 수 있습니다. 강사의 초상화와 코스 오디오를 입력하여 콘텐츠의 호소력을 높이는 교육용 비디오를 빠르게 생성할 수 있습니다. - 엔터테인먼트 및 매혹적인 콘텐츠 제작
사용자는 팬픽이나 엔터테인먼트 동영상에 사용할 재미있는 말투의 인물 사진을 만들 수 있습니다. 큐 단어를 조정하여 소셜 미디어 공유에 적합한 과장된 표정이나 동작으로 동영상을 제작할 수 있습니다.
QA
- 판타지토킹은 어떤 입력 형식을 지원하나요?
이미지는 PNG 및 JPG 형식으로 지원되며 오디오는 최적의 립싱크 동기화를 위해 권장 샘플링 속도 16kHz의 WAV 형식으로 지원됩니다. - 동영상 메모리 부족 문제를 해결하려면 어떻게 해야 하나요?
GPU의 메모리가 충분하지 않은 경우(예: RTX 5090의 32GB VRAM), GPU의 메모리를--image_size(예: 512x512) 또는 감소됨--max_num_frames(예: 30fps). VRAM 최적화 옵션을 활성화하거나 더 구성 가능한 GPU를 사용할 수도 있습니다. - 생성된 동영상의 품질을 어떻게 개선할 수 있나요?
고해상도 입력 이미지(최소 512x512)를 사용하여 오디오가 선명하고 노이즈가 없는지 확인하세요. 조정--audio_cfg_scale(예: 5-7)을 사용하면 립싱크가 향상되고, 큐 단어를 최적화하면 표현의 자연스러움이 향상됩니다. - 실시간 생성을 지원하나요?
현재 버전은 오프라인 추론만 지원하며, 실시간 생성에는 추가적인 모델 최적화와 하드웨어 지원이 필요합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서

댓글 없음...