
일반 소개
Easy-Voice-Toolkit은 오픈 소스 음성 프로젝트에 기반한 다목적 툴킷으로 음성 인식, 음성 전사, 음성 변환, 데이터 세트 생성 및 모델 학습을 위한 다양한 자동화된 오디오 도구를 제공합니다. 사용자는 필요에 따라 이러한 도구를 선택적으로 사용하거나 순차적으로 사용하여 원시 오디오 파일을 이상적인 음성 모델로 점진적으로 변환할 수 있습니다. 툴킷은 로컬 배포를 지원하며, 사용자는 경량 설치 패키지 또는 휴대용 패키지를 다운로드하여 사용할 수 있습니다.

기능 목록
- 오디오 처리

- 음성 인식

- 음성 전사

- 데이터 세트 생성(SRT 변환 및 WAV 분할)

- 모델 교육

- 음성 합성

도움말 사용
설치 프로세스:
- 경량 설치 프로그램 다운로드설치 지침이 포함되어 있지만 필요한 환경 종속성 및 모델이 포함되어 있지 않은 작은 패키지입니다.
- 바로 사용 가능한 휴대용 케이스 다운로드모든 환경 종속성과 여러 모델 사전 설정이 포함된 대용량 패키지, 다운로드하여 압축을 풀고 사용하세요.
로컬 배포 - 사용자 설치:
- 경량 설치 패키지 또는 바로 사용할 수 있는 휴대용 패키지를 다운로드하세요.
- 다운로드한 파일의 압축을 풉니다.
- 움직여야 합니다.
.exe파일 또는 바로 가기.
로컬 배포 - 개발자 설정 환경입니다:
- Python 3.8 이상이 설치되어 있는지 확인합니다.
- 프로젝트 웨어하우스 복제:
git clone https://github.com/Spr-Aachen/Easy-Voice-Toolkit.git - 프로젝트 디렉토리로 전환합니다:
cd Easy-Voice-Toolkit - 종속성을 설치합니다:
pip install -r requirements.txt - GUI 종속 요소를 설치합니다:
pip install pyside6 QEasyWidgets pywin32==300 psutil pynvml darkdetect PyGithub - 프로그램을 실행합니다:
python Run.py
기능별 작업 흐름:
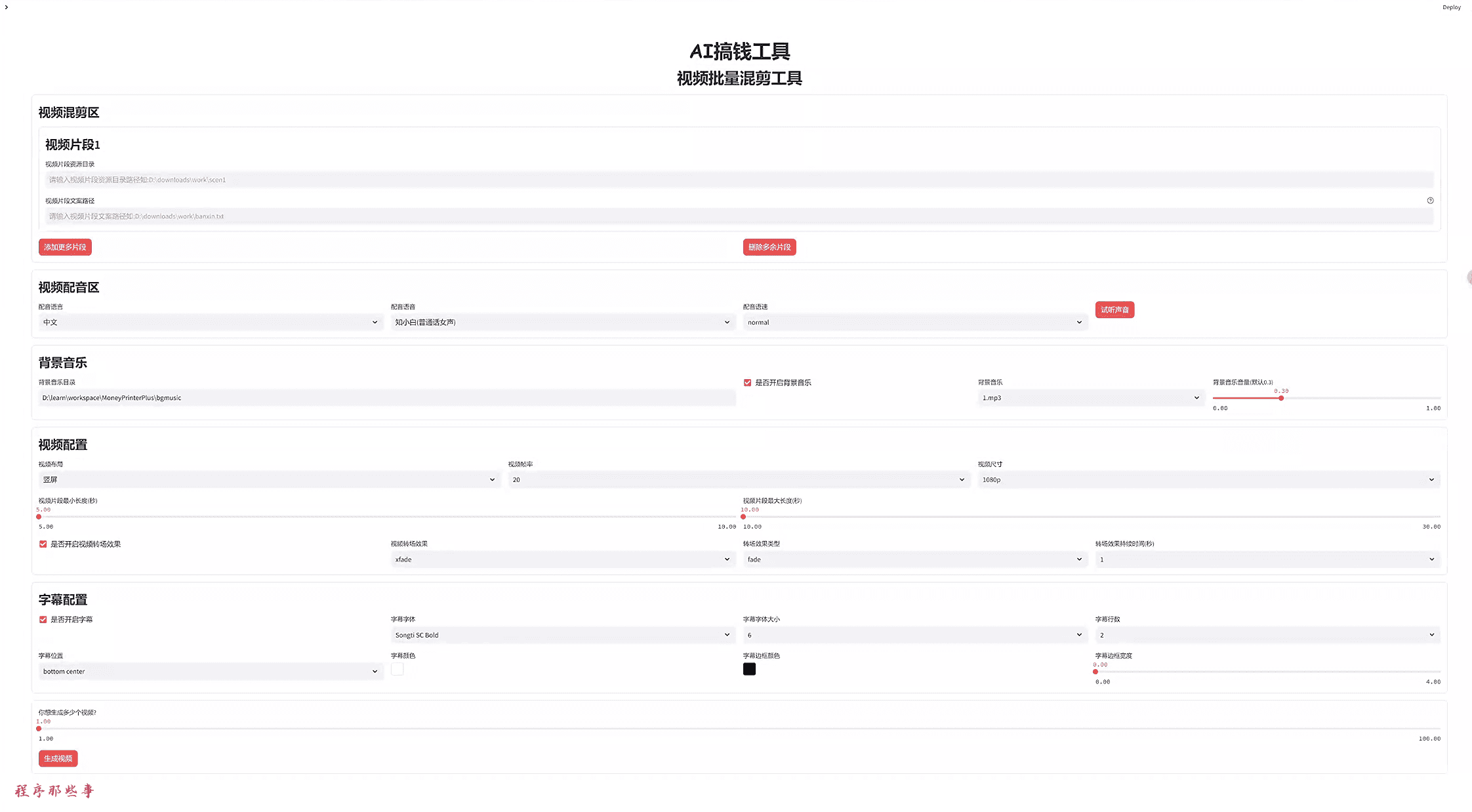
- 오디오 처리: 오디오 파일을 가져오고 원하는 처리 도구(예: 노이즈 제거, 편집 등)를 선택한 후 처리를 적용하고 결과를 저장합니다.
- 음성 인식: 오디오 파일을 가져오고, 음성 인식 모델을 선택하고, 인식을 실행한 후 텍스트 결과를 내보냅니다.
- 음성 전사오디오 파일을 가져오고, 트랜스크립션 도구를 선택한 다음, 트랜스크립션을 실행하고 자막 파일(예: SRT)을 내보냅니다.
- 데이터 집합 생성: 오디오 파일을 가져오고, 데이터 세트 생성 도구를 선택한 다음, SRT 변환 또는 WAV 분할을 수행하여 학습 데이터 세트를 생성합니다.
- 모델 교육학습 데이터 세트를 가져오고, 모델 학습 도구를 선택하고, 학습 매개변수를 구성하고, 학습을 실행하고, 모델을 저장합니다.
- 음성 전사오디오 파일을 가져오고, 음성 변환 도구를 선택하고, 변환 매개변수를 구성하고, 변환을 실행하고, 결과를 저장합니다.
주의
- 현재 UI 인터페이스는 Windows 시스템만 지원합니다.
- 다운로드 및 사용 중에는 인터넷 연결이 안정적인지 확인하세요.
- 문제가 발생하면 프로젝트 리포지토리에 있는 지침과 자주 묻는 질문을 참조하세요.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...