
일반 소개
Easy Dataset은 대규모 모델(LLM)의 미세 조정을 위해 특별히 설계된 오픈 소스 도구로, GitHub에서 호스팅됩니다. 사용자가 파일을 업로드하고, 콘텐츠를 자동으로 분류하고, 질문과 답변을 생성하고, 궁극적으로 미세 조정에 적합한 구조화된 데이터 세트를 출력할 수 있는 사용하기 쉬운 인터페이스를 제공합니다. 개발자 Conard Li는 사용자가 도메인 지식을 고품질의 학습 데이터로 변환할 수 있도록 이 도구를 만들었습니다. 이 도구는 JSON, 알파카 등 다양한 내보내기 형식을 지원하며 OpenAI 형식을 따르는 모든 LLM API와 호환되므로 기술 전문가든 일반 사용자든 누구나 쉽게 시작하고 빠르게 데이터 세트를 만들 수 있습니다.

기능 목록
- 지능형 문서 처리마크다운 파일을 업로드하면 도구가 자동으로 파일을 작은 덩어리로 분할합니다.
- 질문 생성: 세그먼트화된 텍스트를 기반으로 관련 질문을 자동으로 생성합니다.
- 답변 생성각 질문에 대한 자세한 답변을 생성하려면 LLM API를 호출하세요.
- 유연한 편집모든 단계에서 질문, 답변 또는 데이터 세트 콘텐츠 수정을 지원합니다.
- 여러 내보내기 형식데이터 세트는 JSON, JSONL 또는 알파카 형식으로 내보낼 수 있습니다.
- 광범위한 모델 지원OpenAI 형식을 따르는 모든 LLM API와 호환됩니다.
- 사용자 친화적인 인터페이스직관적인 디자인으로 기술 및 비기술 사용자 모두에게 적합합니다.
- 사용자 지정 팁사용자가 모델에 특정 스타일의 답변을 생성하도록 지시하는 시스템 프롬프트를 추가할 수 있습니다.
도움말 사용
설치 프로세스
Easy Dataset은 Docker를 통해 배포하거나 로컬 소스에서 실행하는 두 가지 주요 사용 방법을 제공합니다. 자세한 단계는 다음과 같습니다:
Docker를 통한 설치
- Docker 설치
컴퓨터에 아직 도커가 설치되어 있지 않은 경우 도커 데스크톱을 다운로드하여 설치합니다. 설치가 완료되면 터미널을 열어 성공 여부를 확인합니다:
docker --version
버전 번호가 표시되면 설치되었다는 의미입니다.
- 이미지를 가져와 실행
터미널에 다음 명령을 입력하여 공식 이미지를 가져와 서비스를 시작합니다:
docker run -d -p 3000:3000 -v {你的本地路径}:/app/local-db --name easy-dataset conardli17/easy-dataset:latest
{你的本地路径}데이터를 저장하는 데 사용하는 컴퓨터의 폴더 경로로 대체해야 합니다.C:\data(Windows) 또는/home/user/data(Linux/Mac).-p 3000:3000컨테이너 내의 포트 3000이 로컬로 포트 3000에 매핑되어 있음을 나타냅니다.-v컨테이너가 다시 시작된 후 데이터가 손실되는 것을 방지하기 위한 것입니다.
- 액세스 인터페이스
실행에 성공하면 브라우저를 열고 다음을 입력합니다.http://localhost:3000Easy Dataset 홈페이지가 표시됩니다. Easy Dataset 홈페이지가 표시되면 '프로젝트 만들기' 버튼을 클릭하여 시작합니다.
소스 코드를 통해 로컬에서 실행
- 환경 준비하기
- 컴퓨터에 Node.js(버전 18.x 이상)와 npm이 설치되어 있는지 확인합니다.
- 확인 방법: 터미널에 입력
node -v노래로 응답npm -v를 클릭해 버전 번호를 확인하세요.
- 클론 창고
터미널에 입력합니다:
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset
- 종속성 설치
프로젝트 폴더 내에서 실행됩니다:
npm install
- 서비스 시작
다음 명령을 입력하여 컴파일하고 실행합니다:
npm run build
npm run start
완료되면 브라우저를 열고 다음 사이트를 방문합니다. http://localhost:3000도구 화면에 액세스할 수 있습니다.
주요 기능
프로젝트 만들기
- 홈페이지에서 '프로젝트 만들기' 버튼을 클릭합니다.
- 프로젝트 이름(예: "내 데이터세트")을 입력합니다.
- "확인"을 클릭하면 시스템이 새 프로젝트 공간을 생성합니다.
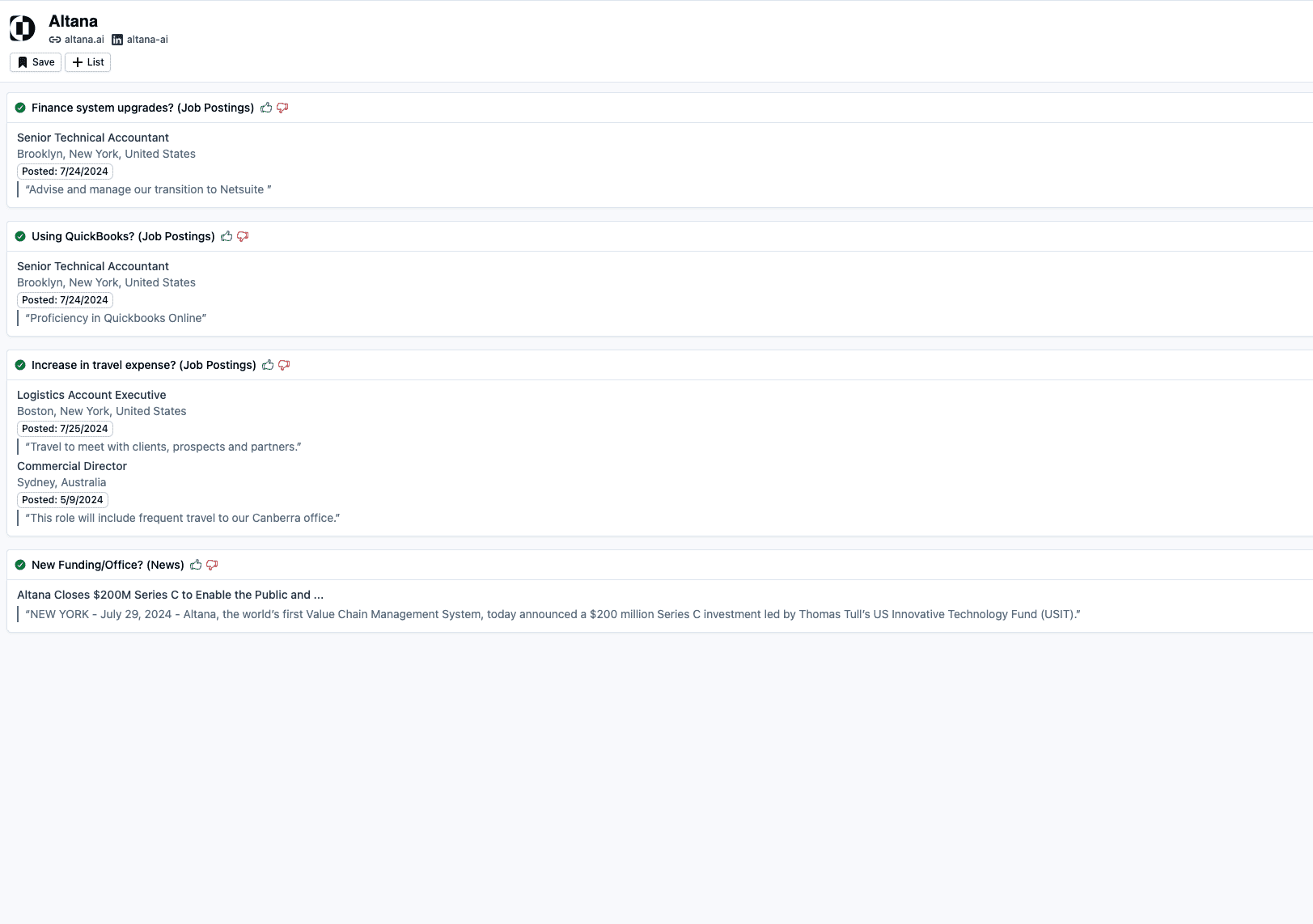
문서 업로드 및 처리
- 프로젝트 페이지에서 "텍스트 분할" 또는 "텍스트 분할" 옵션을 찾습니다.
- "파일 업로드"를 클릭하고 로컬 마크다운 파일을 선택합니다(예
example.md). - 업로드 후 도구가 자동으로 파일 콘텐츠를 작은 세그먼트로 분할합니다. 각 세그먼트는 인터페이스에 표시되며 분할 결과를 수동으로 조정할 수 있습니다.
질문 및 답변 생성
- '질문' 또는 '질문 관리' 페이지로 이동합니다.
- '질문 생성' 버튼을 클릭하면 도구가 각 텍스트를 기반으로 질문을 생성합니다.
- 생성된 문제를 확인하고 만족스럽지 않은 경우 문제 옆에 있는 수정 버튼을 클릭하여 문제를 변경할 수 있습니다.
- "답변 생성"을 클릭하고 LLM API를 선택하면(미리 API 키를 구성해야 함) 도구가 각 질문에 대한 답변을 생성합니다.
- 답변이 생성되면 수동으로 편집하여 콘텐츠가 요구 사항을 충족하는지 확인할 수 있습니다.
데이터 집합 내보내기
- 데이터 세트 또는 데이터 세트 관리 화면으로 이동합니다.
- '내보내기' 버튼을 클릭하고 내보내기 형식(예: JSON 또는 알파카)을 선택합니다.
- 시스템이 파일을 생성하고 다운로드를 클릭한 후 로컬에 저장합니다.
주요 기능 작동
LLM API 구성
- 설정 또는 설정 페이지에서 모델 구성을 찾습니다.
- LLM API 키(예: OpenAI의 API 키)를 입력합니다.
- 모델 유형(많은 일반적인 모델이 지원됨)을 선택하고 구성을 저장합니다.
- 구성이 완료되면 이 모델은 답변을 생성할 때 호출됩니다.
맞춤형 시스템 알림
- 설정 페이지에서 프롬프트 또는 프롬프트 템플릿을 찾습니다.
- "간단한 언어로 답변해 주세요"와 같은 사용자 지정 메시지를 입력합니다.
- 저장되면 프롬프트에 따라 스타일이 조정된 답변이 생성됩니다.
데이터 집합 최적화
- 데이터 세트 화면에서 최적화 버튼을 클릭합니다.
- 시스템이 데이터 세트를 분석하여 중복을 제거하거나 형식을 최적화합니다.
- 최적화된 데이터 세트는 모델 미세 조정에 직접 사용하기에 더 적합합니다.
주의
- Docker로 배포하는 경우 정기적으로 백업하는 것을 잊지 마세요!
{你的本地路径}그 안의 데이터. - 로컬에서 실행하는 경우 답변을 생성하려면 API를 호출하기 위해 인터넷 연결이 필요하므로 네트워크가 열려 있는지 확인하세요.
- 오류가 발생하면 GitHub의 '릴리즈' 페이지에서 최신 버전을 다운로드하여 문제를 해결할 수 있습니다.
애플리케이션 시나리오
- 모델 개발자가 LLM을 미세 조정합니다.
개발자는 간편 데이터셋을 사용하여 기술 문서를 처리하고, Q&A 쌍을 생성하고, 학습 세트를 빠르게 생성하고, 특정 도메인에서 모델 성능을 개선할 수 있습니다. - 교육자가 직접 학습 자료 제작
교사는 코스 유인물을 업로드하고 학생 복습 또는 온라인 코스 콘텐츠 생성을 위한 질문과 답변을 생성할 수 있습니다. - 연구원이 도메인 지식 수집
연구자는 논문이나 보고서를 업로드하고, 주요 질문과 답변을 추출하여 분석할 수 있는 구조화된 데이터로 정리할 수 있습니다.
QA
- Easy Dataset은 어떤 파일 형식을 지원하나요?
현재 주요 지원은 마크다운 파일(.md), 향후 다른 형식 지원이 추가될 수 있습니다. - 자체 LLM API를 제공해야 하나요?
예, 도구 자체는 LLM 서비스를 제공하지 않으며 사용자가 OpenAI 또는 기타 호환 모델과 같은 자체 API 키를 구성해야 합니다. - 내보낸 데이터 집합을 어떤 모델에 사용할 수 있나요?
모델이 OpenAI 형식(예: LLaMA, GPT 등)을 지원하는 한, 내보낸 데이터 집합을 바로 사용할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서

댓글 없음...